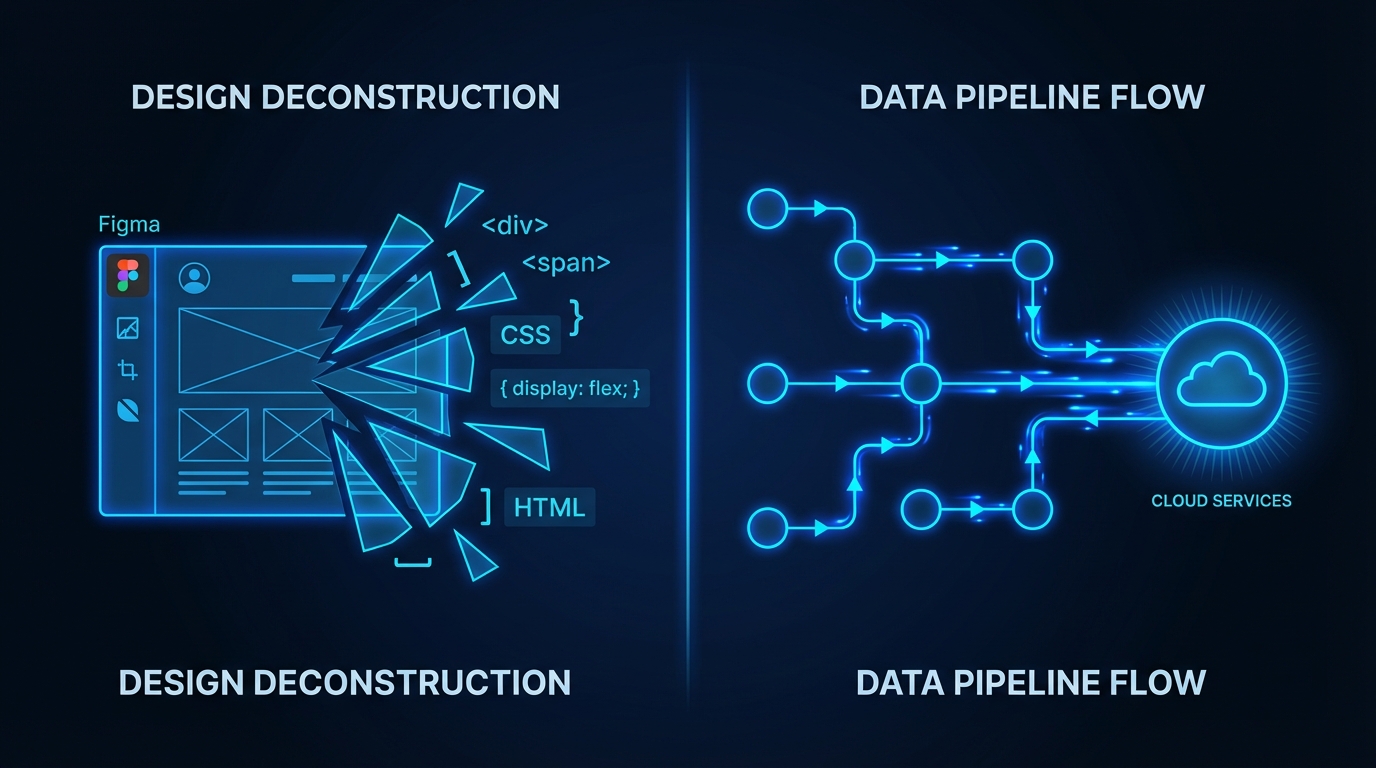
핵심 이슈: "추출 한 번이면 끝" 이라는 위험한 환상
피그마 디자인을 코드로 변환하는 워크플로우가 점점 간편해지고 있습니다. velog에 올라온 한 퍼블리싱 실습기를 보면, Figma의 Inspect 플러그인으로 프레임을 클릭하자 React + Tailwind 조합의 코드가 "알아서 추출"됩니다. 저자는 이 결과를 보고 "그렇다면 리액트를 사용하는 방향으로 가야겠다"고 결정하죠. 솔직히, 이 문장에서 등줄기가 서늘해졌습니다.
사용자 입장에서는 '자동 생성 = 프로덕션 코드'라고 느끼기 쉽습니다. 하지만 Figma에서 볼 때는 괜찮았던 레이아웃이, 실제로 브라우저에 렌더링되면 이야기가 완전히 달라집니다. 자동 추출 코드가 뱉어내는 CSS는 대부분 absolute 좌표 기반이거나, 의미 없는 div 중첩으로 가득합니다. 반응형 브레이크포인트? 없습니다. 시맨틱 HTML? 기대하기 어렵습니다. aria-label이나 키보드 포커스 순서 같은 접근성은 아예 고려 대상이 아니죠. Lighthouse 접근성 점수를 돌려보면 40점대가 나와도 놀랍지 않을 겁니다.
진짜 문제는 이런 자동 생성 코드가 디자인-개발 갭을 "줄여주는 것"이 아니라 "감춰준다"는 점입니다. 디자인 토큰이 없으니 컬러 값이 하드코딩되고, 컴포넌트 단위 분리가 안 되니 재사용이 불가능합니다. 사실 이건 flexbox와 grid로 의미 있게 재구성해야 하는 작업인데, 추출 결과를 그대로 쓰면 기술 부채가 첫 커밋부터 쌓이기 시작합니다. Figma Dev Mode의 디자인 토큰 연동이나 Style Dictionary 같은 파이프라인을 먼저 설계하고, 추출 코드는 "참고 자료" 정도로 취급하는 게 맞습니다.
맥락 해석: 버킷이 아니라 호스로 마셔라
피그마 추출이 "정적 결과물을 한 번에 받는" 패러다임이라면, 프론트엔드 데이터 처리는 정반대 방향으로 진화하고 있습니다. dev.to에 실린 async generator 해설 기사가 정확히 이 전환을 보여줍니다. 50,000명의 유저 데이터를 전부 배열에 담은 뒤 처리하는 기존 방식—기사의 표현을 빌리면 "스트림을 버킷처럼 다루는 것"—은 20초간 화면이 멈추는 최악의 UX를 만듭니다.
async function*과 for await...of 조합은 이 문제를 구조적으로 해결합니다. 페이지 단위로 fetch하면서 즉시 yield하고, 소비 측 루프는 네트워크 대기 중 자동으로 일시정지됩니다. 사용자 입장에서는 첫 10건이 즉시 렌더링되니 체감 로딩이 극적으로 줄어듭니다. 여기서 로딩 스켈레톤을 async generator의 첫 yield 전까지만 보여주면, First Contentful Paint와 Largest Contentful Paint 모두 개선할 수 있겠죠. AbortController로 스트림을 중단할 수 있다는 점도 중요합니다—SPA에서 라우트 전환 시 메모리 누수를 막는 필수 패턴이니까요.
이 스트림 사고방식이 극단적으로 적용된 사례가 WebRTC Insertable Streams입니다. 같은 dev.to의 E2EE 구현 기사를 보면, WebRTC 파이프라인의 인코더와 패킷타이저 사이에 TransformStream 훅을 삽입해서 프레임 단위로 AES-GCM 암호화를 수행합니다. ReadableStream에서 인코딩된 프레임을 읽고, TransformStream으로 암호화한 뒤, WritableStream으로 내보내는 구조죠. 초당 30~60프레임을 처리해야 하니 Web Worker로 오프로딩하는 건 당연하고, SubtleCrypto API를 통한 하드웨어 가속 없이는 메인 스레드 jitter가 눈에 보일 겁니다.
시사점: 스트림은 이제 '특수 기술'이 아니라 기본 소양
두 스트림 기사를 관통하는 메시지는 동일합니다. "데이터를 모아서 한 번에 처리"하는 배치 사고에서, "흘러가는 데이터를 파이프라인으로 변환"하는 스트림 사고로 전환하라는 것입니다. async generator는 API 페이지네이션에, Insertable Streams는 실시간 미디어 암호화에 쓰이지만, 근본적으로는 ReadableStream → TransformStream → WritableStream이라는 동일한 브라우저 네이티브 패턴 위에 있습니다. 프론트엔드 아키텍처에서 이 패턴을 이해하지 못하면, LLM 스트리밍 응답 처리도, 대용량 파일 업로드 진행률 표시도 제대로 구현하기 어렵습니다.
이걸 피그마 워크플로우와 다시 연결하면 이렇습니다. 디자인 추출 도구가 아무리 발전해도, 스켈레톤 로딩·점진적 렌더링·스트림 기반 데이터 바인딩 같은 "시간 축 위의 UX"는 자동 생성할 수 없습니다. 그건 개발자가 아키텍처 레벨에서 설계해야 하는 영역이죠.
전망: 추출은 시작점일 뿐, 프로덕션은 파이프라인이다
피그마 추출의 품질은 계속 좋아질 겁니다. Container Queries나 :has() 같은 최신 CSS를 지원하는 플러그인도 나오겠죠. 하지만 프로덕션 수준의 프론트엔드는 정적 마크업이 아니라, 데이터가 흐르는 파이프라인입니다. 디자인 토큰으로 시각적 일관성을 확보하고, 스트림 API로 데이터 흐름을 제어하고, Core Web Vitals로 결과를 측정하는—이 세 축이 맞물려야 비로소 "피그마에서 프로덕션까지"가 완성됩니다. 추출 버튼 한 번으로 끝나는 건, 아직은 환상입니다.