근거는 있나요? — 397B 파라미터의 화려한 숫자 뒤를 뒤집어 봅니다
알리바바가 Qwen3.5-397B-A17B를 공개하면서 던진 숫자들은 확실히 인상적입니다. 총 3,970억 파라미터, 쿼리당 170억만 활성화, 전작 대비 최대 19배 빠른 디코딩 처리량, MMLU-Pro 94.9, MathVision 88.6. 하지만 데이터 분석가로서 가장 먼저 묻고 싶은 건 이겁니다 — 이 숫자들의 측정 조건과 재현 가능성은 검증되었나요?
벤치마크 자체 보고의 구조적 문제
Qwen3.5의 성능 비교 대상은 GPT-5.2, Claude 4.5 Opus, Gemini-3 Pro입니다. 디지털포커스 보도에 따르면, TAU2(에이전트 벤치마크)에서 86.7점으로 GPT-5.2의 87.1에 근접하고, IFBench(76.5)와 MultiChallenge(67.6)에서는 최고점을 기록했다고 합니다. 그런데 여기서 통계적 의심 하나: 이 비교는 동일한 평가 프로토콜, 동일한 프롬프트 설정, 동일한 시점의 모델 버전으로 이루어진 것인가요? 자체 보고(self-reported) 벤치마크에서 경쟁 모델의 점수는 대개 해당 모델의 공식 발표치를 가져오는데, 평가 시점·프롬프트 포맷·디코딩 전략(temperature, top-p 등)이 다르면 동일 벤치마크라도 수 포인트의 차이가 발생합니다. Hacker News 커뮤니티에서도 "벤치마크와 체감 성능의 차이가 크다"는 지적이 나왔고, "양자화를 거치면 성능이 더 떨어진다"는 경험적 보고가 있었습니다.
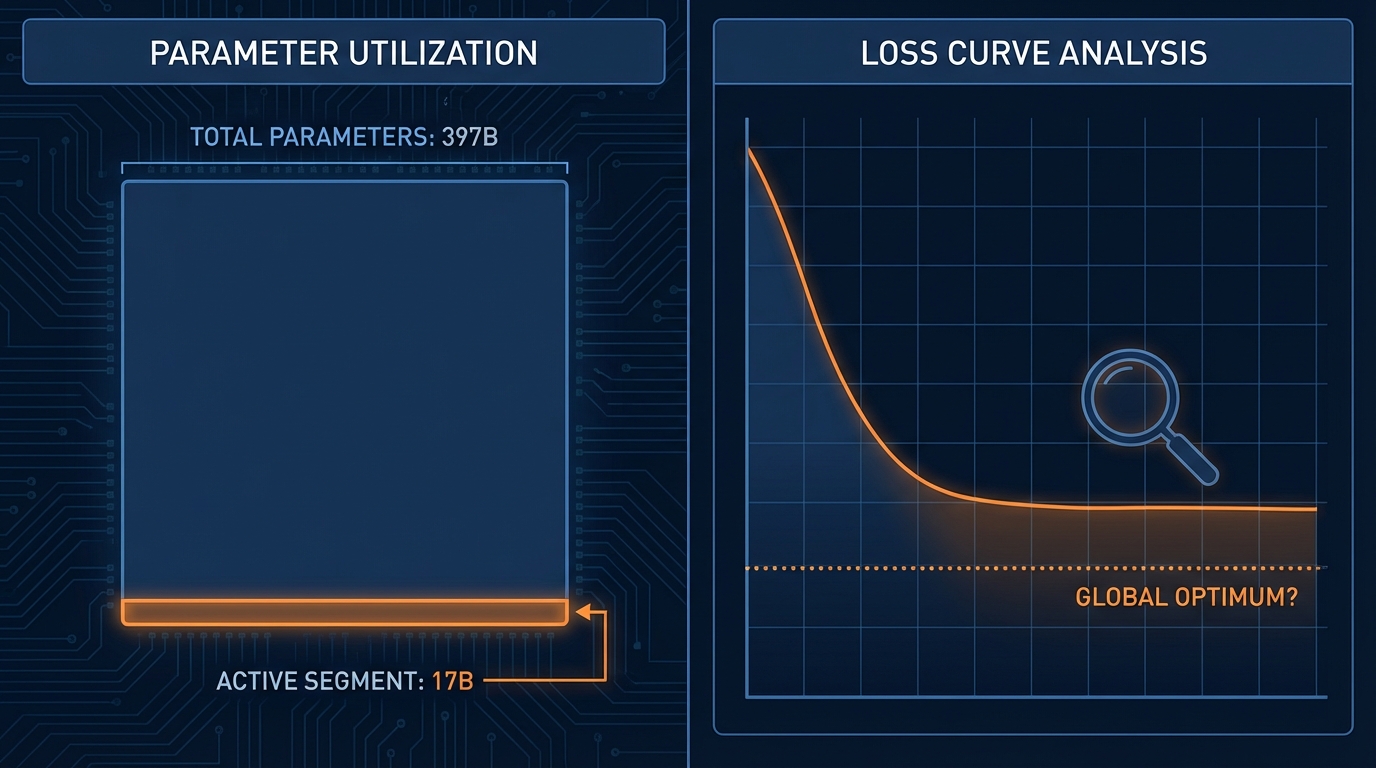
397B vs 17B — MoE의 진짜 trade-off
Mixture-of-Experts(MoE) 아키텍처에서 397B 중 17B만 활성화된다는 것은, 추론 시 연산량(FLOPs) 기준으로는 17B dense 모델에 가깝지만 메모리 적재량(memory footprint)은 여전히 397B 전체를 요구한다는 뜻입니다. Gated Delta Networks 기반 선형 어텐션으로 256k 컨텍스트에서 Qwen3-Max 대비 19배 처리량을 달성했다는 주장도, 베이스라인인 Qwen3-Max가 어떤 하드웨어·배치 사이즈 조건이었는지에 따라 해석이 완전히 달라집니다. FP8 파이프라인으로 메모리 50% 절감, 속도 10%+ 향상이라는 수치도 마찬가지입니다 — ablation study에서 각 기법(MoE 희소화, GDN 어텐션, FP8 양자화)의 개별 기여도가 분리되어 있는지가 핵심입니다. 공개된 기술 블로그만으로는 이 분리가 충분히 이루어졌다고 보기 어렵습니다.
API 가격 비교의 함정 — correlation ≠ causation
입력 100만 토큰당 $0.40, 출력 $2.40이라는 가격은 확실히 OpenAI·Anthropic 대비 파격적입니다. 하지만 '가격이 낮으니 효율적'이라는 결론으로 바로 도약하면 안 됩니다. 동일 태스크에서 동일 품질의 출력을 얻기까지 필요한 총 토큰 수, 재시도 횟수, 그리고 후처리 비용까지 포함한 TCO(Total Cost of Ownership) 비교가 없으면, 토큰 단가 비교는 불완전합니다. 실제 운영 환경에서 에이전트가 멀티스텝 도구 호출 중 문맥을 잃어버려 재시도가 빈번하다면, 저렴한 단가가 오히려 더 높은 총비용으로 이어질 수 있습니다.
MAE 0.96을 'Global Optimum'이라 부를 수 있을까
흥미롭게도, Qwen3.5의 거대 모델 벤치마크 이야기와 정반대 스케일에서 비슷한 통계적 함정이 발생합니다. 한 ML 학습 기록에서 XGBoost 모델의 MAE 0.9596을 두고 "데이터가 줄 수 있는 정보 안에서 뽑아낼 수 있는 최대 성능, 즉 Global Optimum에 도달했다"고 판단한 사례가 있었습니다. 데이터 분석가로서 이건 위험한 결론입니다. Global Optimum 주장을 하려면 최소한 (1) 교차 검증 분산(CV variance)이 충분히 작은지, (2) learning curve가 실제로 plateau에 도달했는지, (3) 잔차(residual) 분포에 패턴이 남아 있지 않은지, (4) 다른 모델 패밀리(예: LightGBM, CatBoost, 심층 신경망)에서도 유사한 상한을 보이는지를 확인해야 합니다. 단일 모델의 단일 메트릭으로 전역 최적이라 선언하는 것은, local minimum을 global minimum으로 착각하는 전형적인 오류입니다.
학습 목적(training objective)이 '어텐션'을 결정한다
이 모든 논의를 관통하는 더 근본적인 질문이 있습니다. 한 velog 포스트가 흥미로운 사고실험을 제시합니다 — 동일한 네트워크를 회전 예측(rotation prediction)과 분류(classification)로 각각 학습시키면, 모델이 이미지에서 '보는 것' 자체가 달라진다는 것입니다. 이 관점은 벤치마크 해석에도 직접 적용됩니다. Qwen3.5가 15,000개의 RL 환경에서 학습했다면, 그 환경이 어떤 '질문'을 던졌느냐가 모델의 실제 역량을 결정합니다. 벤치마크에서 높은 점수가 나왔다는 것은 그 벤치마크가 묻는 질문에 맞는 어텐션을 학습했다는 뜻이지, 실제 프로덕션 태스크의 다양성을 커버한다는 증거가 아닙니다.
시사점 — 숫자를 의심하는 습관이 최고의 방어선
정리하면 세 가지입니다. 첫째, 자체 보고 벤치마크의 SOTA 주장은 독립적 재현(independent reproduction) 전까지 보류해야 합니다. 특히 MoE 모델은 활성 파라미터 수 대비 성능만 볼 것이 아니라, 전체 파라미터의 메모리 비용과 실제 latency를 함께 봐야 합니다. 둘째, '최적점 도달'이라는 선언은 단일 실험이 아니라 체계적인 ablation과 다중 모델 교차 검증으로만 정당화됩니다 — XGBoost든 397B LLM이든 마찬가지입니다. 셋째, 학습 목적(objective)이 모델의 어텐션 패턴을 결정한다는 사실을 잊지 말아야 합니다. 벤치마크 점수는 '그 질문에 대한 답'이지 '모든 질문에 대한 답'이 아닙니다.
중국 AI 진영의 오픈 웨이트 경쟁(GLM-5, Kimi K2.5, ERNIE 5.0 등)은 접근성과 가격 측면에서 생태계를 확실히 넓히고 있습니다. 그러나 숫자가 화려할수록 '샘플 사이즈가 충분한가요?', '베이스라인 대비 얼마나 개선되었나요?', '이 데이터에는 어떤 편향이 있을까요?'라는 기본적인 질문이 더 중요해집니다. 397B라는 파라미터 수는 마케팅 지표입니다. 실제 프로덕션에서의 성능은 여러분의 데이터, 여러분의 태스크, 여러분의 평가 파이프라인에서만 검증됩니다.