AI 에이전트 붐의 역설이 시작됐습니다. 에이전트는 사람처럼 ‘검색’하지 않고, 결정을 위해 웹을 5개가 아니라 5,000개를 훑습니다. Cloudflare가 “주간 요청 수가 한 달 만에 두 배”라고 말한 배경(google_news/TIKR 인용)이죠. 이 트래픽은 곧바로 비용입니다. 토큰, 크롤링, 네트워크, 서빙까지 전부 변동비로 튀어 오릅니다.
그런데 동시에, 이 폭발이 엔터프라이즈 침투의 문도 열어요. LG CNS가 OpenAI와 리셀러/구현 파트너 계약을 맺고 ‘도입→운영→확산’ 풀스택을 판다는 뉴스(파이낸셜투데이)는 신호입니다. “에이전트=비용”인 조직에 “에이전트=업무 표준”을 심어주면, 락인이 생깁니다. 문제는 단 하나: 리텐션과 수익화로 비용을 역전시키는 설계가 없으면 PoC로 끝납니다.
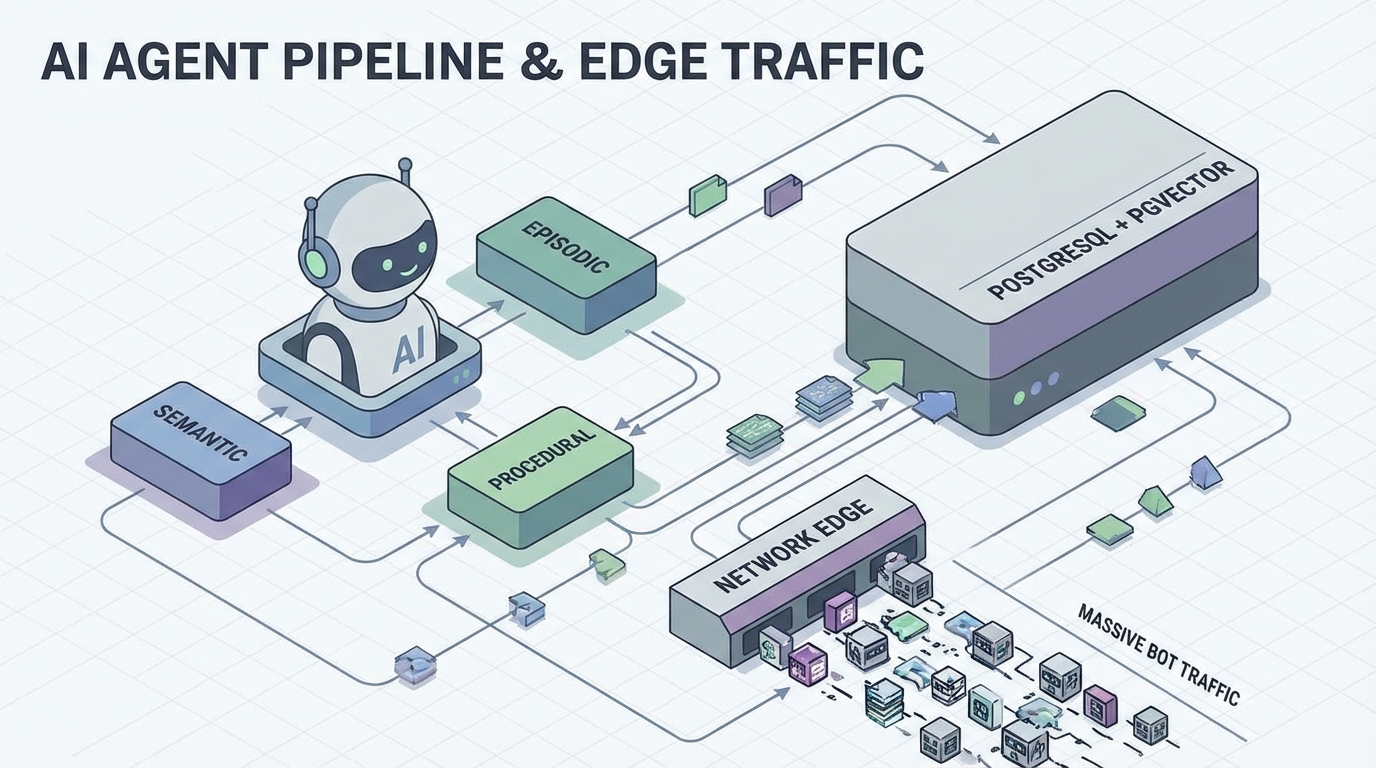
여기서 dev.to의 Mengram 사례가 꽂힙니다. 기존 메모리 도구가 ‘사실(semantic)’만 저장해 개인화에 머물렀다면, Mengram은 ‘사건(episodic)’과 ‘절차(procedural)’까지 한 번에 뽑아 저장합니다(dev_to 원문). 이게 왜 그로스냐고요? 절차 메모리는 에이전트의 재작업을 줄여 서빙 비용을 낮추고, 성공/실패 트래킹으로 다음 실행을 더 빠르고 정확하게 만듭니다. 즉, 같은 유저 가치(Outcome)를 더 싼 CAC/COGS로 제공할 수 있는 구조가 됩니다.
맥락을 그로스 퍼널로 번역해보면 명확합니다. (1) 획득: 에이전트가 트래픽을 만들며 채널이 열립니다(에이전트 SEO/AEO, 파트너 유통, 마켓플레이스). (2) 활성화: 첫 세션에서 “개인화된 답”이 아니라 “개인화된 실행”이 나와야 합니다. (3) 리텐션: 다음 세션에서 ‘기억’이 아니라 ‘업무가 계속’되어야 합니다. 바로 episodic/procedural이 D7/D30 리텐션을 끌어올릴 레버예요. (4) 수익화: 엔터프라이즈는 ‘정확도’보다 ‘재현성’과 ‘통제’를 삽니다.
시사점은 두 가지입니다. 첫째, 개인화는 이제 “유저가 뭘 좋아하는지”가 아니라 “유저가 일을 어떻게 끝내는지”로 넘어갑니다. 절차 메모리가 붙은 에이전트는 유저의 워크플로우를 저장하고, 반복 업무의 마찰(Friction)을 제거합니다. Conversion rate가 어디서 오르냐면, 온보딩 CTA가 아니라 ‘두 번째 성공’에서 오릅니다. 성공 경험이 누적되면 습관이 되고, 습관은 LTV가 됩니다.
둘째, 비용은 모델이 아니라 메모리/인프라 설계에서 크게 갈립니다. Mengram이 PostgreSQL+pgvector로 별도 벡터DB 없이 구성한 것(dev_to)은 단순 기술 선택이 아니라 unit economics 선택이에요. 저장/검색을 하이브리드(벡터+FTS+리랭크)로 최적화하고, “필요할 때만” 컨텍스트를 올리면 토큰 다이어트가 됩니다. 여기에 Cloudflare가 AI 크롤링 제어/수익화 도구로 ‘브로커’ 포지션을 노리는 흐름(TIKR 인용)을 붙이면, 앞으로는 에이전트 트래픽을 ‘그냥 받는 것’이 아니라 ‘통제하고 과금하는 것’이 표준이 됩니다.
전망: 에이전트 그로스의 승자는 ‘더 똑똑한 모델’보다 ‘더 잘 기억하고, 더 싸게 반복하는 시스템’을 가진 팀이 될 가능성이 큽니다. 특히 엔터프라이즈는 할루시네이션/비결정성 같은 한계가 남아있는 한(관련 비판 논의는 dev_to 다른 글에서도 제기), “완벽한 답변”보다 “실패를 기록하고 다음에 개선되는 절차”를 더 신뢰합니다. 그러니 다음 실험은 이겁니다: 절차 메모리(성공/실패) + 트리거(리마인더/모순 탐지) + 저비용 저장소를 묶어, 유저 100명 코호트에서 D7 리텐션과 작업 성공률을 같이 보세요. 이거 바이럴 될 것 같은데? ‘에이전트가 일을 점점 더 잘한다’는 체감은 공유를 부르고, 공유는 CAC를 낮춥니다. 빨리 테스트해봐야 돼요.