90%의 CEO가 체감하지 못하는 AI, 어디서 막혔나
Fortune이 인용한 NBER 연구 결과는 꽤 충격적이다. 미국·영국·독일·호주의 경영진 6,000명 중 약 90%가 지난 3년간 AI가 고용이나 생산성에 영향을 미치지 않았다고 답했다. S&P 500 기업 374곳이 실적 발표에서 AI를 언급하면서도, 정작 경영진의 AI 사용 시간은 주당 1.5시간에 불과하다. 25%는 직장에서 AI를 아예 쓰지 않는다. 1987년 노벨 경제학상 수상자 Robert Solow가 "컴퓨터 시대는 어디에서나 보이지만 생산성 통계에서는 보이지 않는다"고 했던 그 패러독스가, 거의 40년 만에 AI 버전으로 재연되고 있는 셈이다.
이 숫자를 보면서 나는 "역시 AI는 아직 멀었네"가 아니라, "이 사람들이 AI를 쓰는 방식 자체가 틀렸을 가능성"을 먼저 떠올렸다. AI-First 팀을 리빌딩하면서 매일 체감하는 건, AI 도구의 성능 문제가 아니라 워크플로우 인프라의 부재가 생산성 병목이라는 사실이다.
생산성 패러독스의 진짜 원인: I/O 병목과 Context 오염
Hacker News 토론에서 한 시니어 개발자가 핵심을 짚었다. "문제는 코딩 속도가 아니라 I/O 병목이다." 대기업을 결함 있는 하드웨어 위의 분산 시스템으로 비유한 것도 인상적이다. 각 개인(CPU)은 빠르지만, 회의·승인 대기·컨텍스트 스위칭으로 지연이 발생한다. AI가 코드 생성 속도를 3배 올려줘도, 리뷰·승인·정렬이라는 I/O 병목이 그대로면 전체 처리량은 변하지 않는다.
실무에서 이 병목이 가장 날카롭게 드러나는 지점이 바로 AI 코딩 에이전트의 Context Window 관리다. Velog의 Claude Code 실무 아키텍처 시리즈에서 다룬 사례가 정확히 이 문제를 보여준다. PR 리뷰를 위해 20개 파일을 한 세션에 올렸더니 Context Window의 40~60%가 즉시 소모되고, 이어서 구현·테스트·에러 핸들링까지 같은 세션에서 처리하려 하자 auto-compaction이 발동하면서 아침에 정의했던 설계 원칙이 통째로 날아갔다. 방금 리뷰에서 "이 방식은 쓰지 말자"고 정리한 부분을 Claude가 다시 생성하기 시작한 것이다.
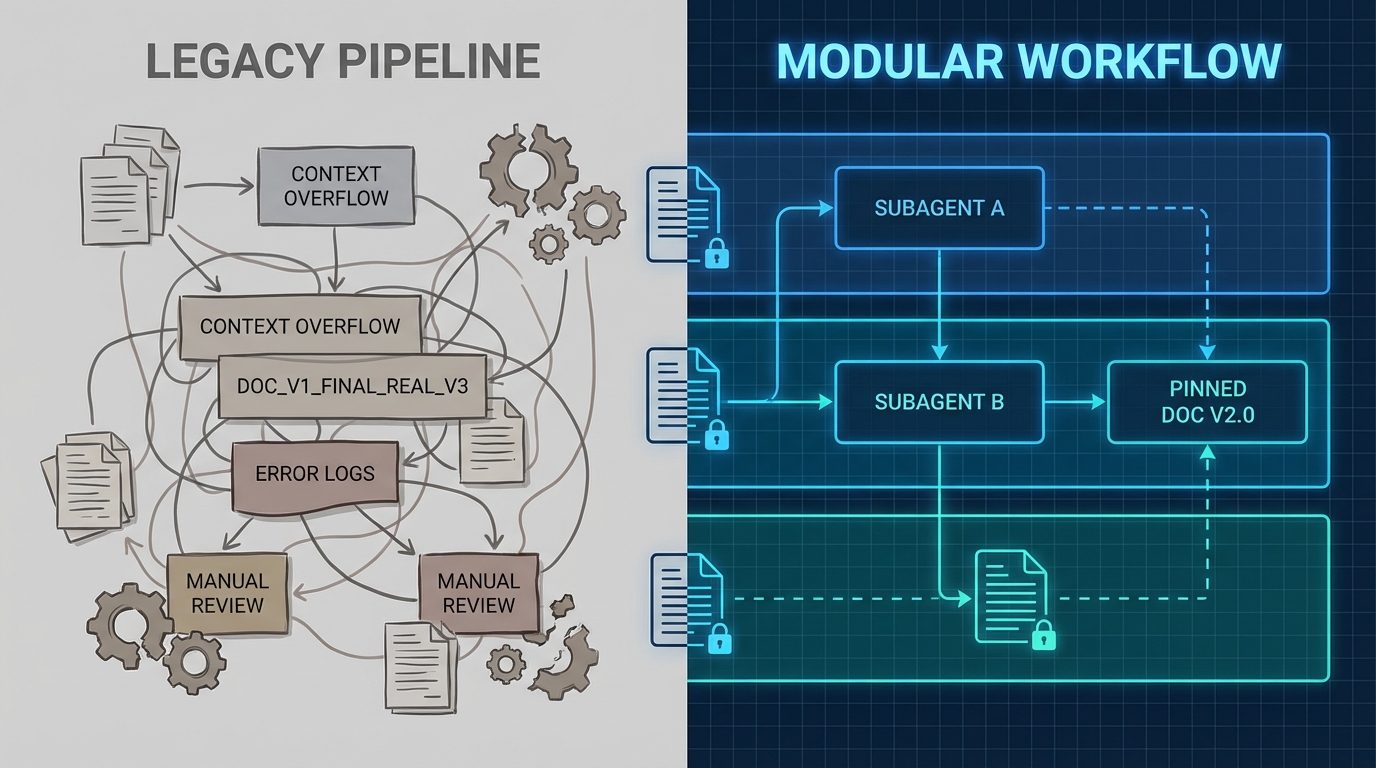
이것을 "Context 오염"이라 부른다. 하나의 세션에 조사·설계·구현·테스트를 전부 밀어 넣는 패턴이다. 모델 능력의 문제가 아니라 세션 설계의 실패다. CEO들이 "AI가 생산성에 영향 없다"고 답한 배경에도 같은 구조가 있다고 본다. 도구는 줬지만, 그 도구가 효과적으로 작동하기 위한 워크플로우 인프라를 설계하지 않은 것이다.
패러독스를 깨는 3가지 워크플로우 인프라
1. Context 분할 설계: Subagent 아키텍처
해법은 단순하다. Context를 분할하라. Claude Code의 Subagent(Task tool) 구조가 정확히 이 원리다. 메인 세션은 의사결정과 구현에 집중하고, 파일 탐색·구조 분석 같은 조사 작업은 독립된 Context Window를 가진 Explore Subagent에 위임한다. 50개 파일을 읽어도 메인에는 요약 몇 줄만 반환된다. 대규모 변경 전에는 Plan Subagent로 설계를 먼저 세우고, 실제 수정은 별도 단계에서 진행한다. 이 구조 하나만으로 auto-compaction 위험이 줄고 설계 일관성이 유지된다.
2. 버전 고정 문서 인프라: "모델이 아니라 데이터가 문제다"
Dev.to에 올라온 Neuledge Context 사례가 두 번째 인프라를 설명한다. AI SDK v5에서 작업하는데 어시스턴트가 v6 API로 코드를 생성하는 상황—Experimental_Agent가 ToolLoopAgent로, parameters가 inputSchema로 바뀌었는데, 에러 메시지는 "undefined properties"만 뱉는다. 한 시간을 디버깅한 뒤에야 SDK 체인지로그를 확인하게 된다. 훈련 데이터는 모든 버전을 혼합하고, 클라우드 문서 서비스는 최신 버전만 인덱싱한다. Git 태그 기반으로 특정 버전의 문서를 MCP로 제공하는 인프라가 팀 차원에서 구축되어야 "AI가 맞는 코드를 틀리게 쓰는" 유령 버그가 사라진다.
3. 세션 관리 도구: 흩어진 맥락을 되찾기
agf 같은 TUI 도구가 세 번째 퍼즐 조각이다. AI 코딩 에이전트를 본격적으로 쓰면 세션이 기하급수적으로 쌓인다. "이 프로젝트 어디서 작업했더라?"를 반복하는 순간, 생산성 이득이 컨텍스트 복구 비용으로 상쇄된다. 퍼지 검색으로 세션을 즉시 탐색하고, Enter 한 번으로 재개하며, 불필요한 세션을 벌크 삭제하는 인프라가 있어야 세션 간 맥락 전환 비용이 최소화된다.
J-커브의 꺾이는 지점은 인프라가 결정한다
1970~80년대 IT 투자가 1990년대 생산성 급등으로 이어진 전례가 있다. AI도 J-커브 형태의 지연 후 성장이 예상된다는 분석은 Stanford 디지털경제연구소장 Erik Brynjolfsson부터 Apollo 수석 이코노미스트 Torsten Slok까지 공통된 견해다. 하지만 이번에는 다른 조건이 하나 있다. LLM 간 경쟁으로 도구 가격이 이미 Slack 구독료 수준까지 내려왔다는 것이다. J-커브의 꺾이는 시점을 앞당기는 건 더 좋은 모델이 아니라, 팀이 그 모델을 효과적으로 쓸 수 있게 만드는 워크플로우 인프라다.
Context Window를 분할하는 세션 설계, 버전이 고정된 문서 파이프라인, 세션 맥락을 한 곳에서 관리하는 도구—이 세 가지는 화려하지 않다. 하지만 CEO들이 "AI 효과가 없다"고 답하는 조직과, 실제로 생산성 곡선을 꺾어 올리는 팀 사이의 차이는 정확히 이 인프라의 유무에 있다. AI-First 팀 리빌딩의 첫 번째 과제는 더 똑똑한 모델을 도입하는 게 아니라, AI가 제대로 작동할 수 있는 맥락의 배관을 깔아주는 일이다.