런타임 1ms도 아깝다면, 스타일 계산부터 빌드로 밀어내야 합니다
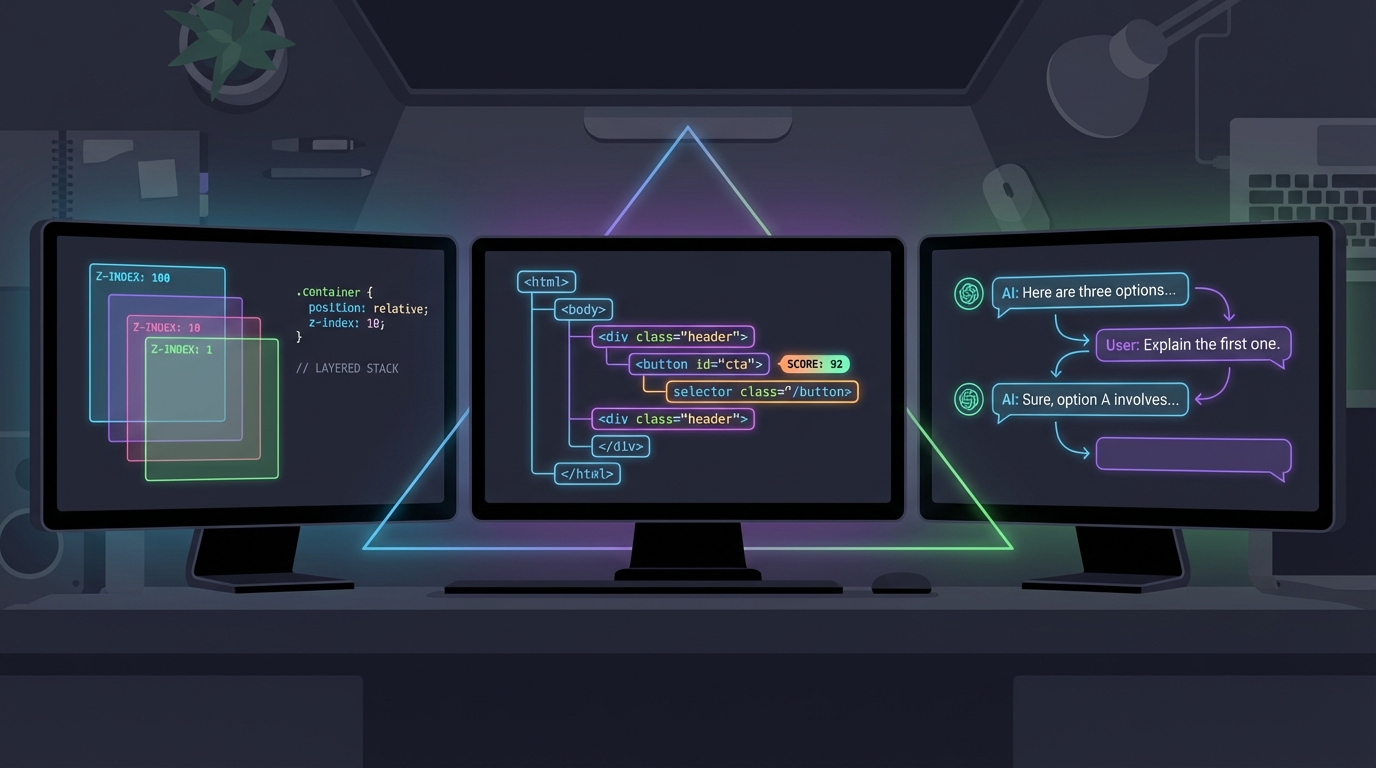
React에서 다이얼로그 여러 개를 스택으로 쌓을 때, z-index를 어떻게 관리하고 계신가요? 아마 대부분은 dialogs.map 안에서 인덱스에 5를 곱해 backdrop과 content에 인라인 스타일로 넣고 있을 겁니다. 작동은 합니다. 그런데 사용자 입장에서는 아무 변화도 없는데 매 렌더 사이클마다 산술 연산이 돌아간다는 거, 좀 거슬리지 않나요?
dev.to에 올라온 한 포스트(9thquadrant)가 정확히 이 지점을 찔렀습니다. SCSS @for 루프로 1부터 6까지 :nth-of-type 셀렉터에 z-index를 미리 찍어 두면, 컴파일 타임에 플레인 CSS로 떨어지고 런타임 비용은 완전히 제로가 됩니다. backdrop과 content 사이에 2 단위, 레이어 간에 5 단위의 갭을 두는 설계도 깔끔합니다. Hooks도, Effects도, 상태 관리도 필요 없습니다. "스타일 문제는 스타일 레이어에서 해결하라"는 원칙 그대로입니다.
다만 Figma에서 볼 때는 괜찮았는데, 실제로 구현하면 걸리는 부분이 있습니다. nth-of-type은 같은 타입의 형제 요소에 민감해서, Portal 컨테이너 안에 다이얼로그 외의 div가 끼어들면 셀렉터가 어긋납니다. DOM 구조를 반드시 검증해야 하고, 레이어 상한 6이라는 숫자도 프로젝트 z-index 스케일에 맞춰 조정해야 합니다. 그래도 핵심은 변하지 않습니다 — 런타임에서 반복되는 계산을 빌드 타임으로 옮기는 것, 이건 성능 최적화의 가장 기본적인 방향이고, CSS Container Queries나 @layer 같은 최신 스펙이 지향하는 "스타일 계층의 명시적 통제"와도 맥이 닿습니다.
셀렉터 하나 따는 데 30초씩 쓰고 있다면
프론트엔드 개발자에게 QA 셀렉터 작성은 "내가 이걸 왜 하고 있지?"의 대표 격입니다. DevTools 열고, 엘리먼트 찍고, data-testid가 있는지 확인하고, 없으면 안정적인 속성을 조합해서 Playwright 문법으로 감싸고, 테스트 파일에 붙여넣기. 7년차 QA 엔지니어 wissemd가 dev.to에 공개한 Chrome 확장 QA Power-Click은 이 루틴 전체를 브라우저 사이드바 한 번의 클릭으로 압축합니다.
기술적으로 흥미로운 건 셀렉터 스코어링 엔진입니다. data-testid가 있으면 100점으로 즉시 확정하고, aria-label 80~85점, 안정적 ID 88점, 텍스트 75점, CSS class는 최후의 10점. 여기에 Ember·React :r1a:·Angular ng-content-*·Webpack 해시 클래스 등 100개 이상의 동적 ID 패턴을 블랙리스트로 감지해 자동 회피합니다. 사실 이건 프론트엔드 개발자가 컴포넌트에 data-testid를 빠뜨렸을 때의 fallback 전략 그 자체입니다.
또 하나 눈에 띄는 건 React·Vue의 폼 채우기 문제를 nativeInputValueSetter로 우회한 부분입니다. 프레임워크가 내부적으로 value를 추적하기 때문에 DOM에 직접 값을 넣으면 상태가 씹히는데, 프로토타입 체인의 setter를 호출한 뒤 input 이벤트를 dispatch해서 프레임워크 상태 업데이트를 트리거하는 방식이죠. Shadow DOM 관통, iframe 전환 코드 자동 삽입까지 — 이 정도면 단순 확장이 아니라 셀렉터 전략 자체를 도구화한 것에 가깝습니다.
AI 에디터의 UX는 곧 '컨텍스트 관리'입니다
Cursor 토큰이 바닥나서 GitHub Copilot으로 넘어간 maximsaplin의 비교 포스트는, 두 도구의 기능 목록이 아니라 대화 흐름의 UX 차이를 정밀하게 드러냅니다. 프론트엔드 개발자로서 가장 공감한 대목은 세 가지입니다.
첫째, Plan Mode의 깊이 차이. Cursor는 구조화된 .MD 플랜을 생성하고 거기서 별도 모델·클린 컨텍스트로 새 에이전트를 스폰할 수 있는데, Copilot의 Plan Mode는 서브에이전트가 범용적인 텍스트를 뱉고 'Proceed' 버튼이 그냥 Agent 모드로 전환할 뿐입니다. 이건 마치 Figma에서 Auto Layout 쓰다가 절대 좌표로 돌아간 느낌이에요.
둘째, 다이얼로그 분기와 토큰 카운터. Cursor에서는 대화 중간 지점에서 브랜치를 치거나 클론할 수 있고, 컨텍스트 윈도우 사용량 인디케이터가 항상 보입니다. Copilot은 토큰 카운터조차 2025년 1월에야 Insider Preview에 추가됐고, 자동 요약이 불시에 개입해서 에이전트가 맥락을 잃는 사고가 발생합니다. 컨텍스트 오버플로를 시각적으로 모니터링할 수 없다면, 그건 반응형 브레이크포인트 없이 모바일 대응하는 것과 다를 바 없습니다.
셋째, Agent Skills의 명시적 호출. Cursor는 자동 매칭과 슬래시 커맨드 호출을 모두 지원하지만, Copilot의 Agent Skills는 모델이 알아서 판단하는 자동 모드만 있습니다. /spec, /task 같은 명시적 트리거 없이는 Spec-Driven 워크플로우를 제어할 수 없죠. 이미지 파일을 컨텍스트로 읽지 못하는 것, reasoning effort를 모델별로 세분화할 수 없는 것까지 — 결국 도구의 DX는 "내가 컨텍스트를 얼마나 정밀하게 통제할 수 있느냐"로 귀결됩니다.
시사점: DX 최적화의 공통 문법
이 세 소스를 관통하는 키워드는 "반복의 제거"와 "제어권의 이동"입니다. SCSS 컴파일타임 z-index는 런타임 반복 계산을 빌드로 옮기고, QA Power-Click은 셀렉터 작성의 수동 반복을 점수 엔진으로 자동화하고, Cursor의 UX 우위는 컨텍스트 제어권을 개발자에게 돌려줍니다.
프론트엔드 DX를 논할 때 우리는 흔히 프레임워크 선택이나 번들러 교체 같은 큰 그림에 집중하지만, 실제로 Lighthouse 점수 1점, 테스트 커버리지 1%, 에이전트 대화 한 턴의 차이를 만드는 건 매일 반복하는 30초짜리 마찰을 제거하는 작은 결정들입니다. z-index를 빌드에서 찍을지 런타임에서 계산할지, 셀렉터를 손으로 쓸지 도구에 맡길지, 대화 컨텍스트를 분기할 수 있는지 없는지 — 이 "1px 단위의 DX 차이"가 쌓여서 팀의 속도를 결정합니다.
결국 사용자 입장에서는 보이지 않지만 개발자 입장에서는 매일 체감하는 이 삼각지대 — 컴파일타임 스타일 전략, 테스트 셀렉터 자동화, AI 에디터의 컨텍스트 UX — 를 의식적으로 점검하는 팀이, 다음 스프린트에서 한 발 더 빠를 것입니다.