근거는 있나요? LLM을 시계열 예측에 쓴다는 Time-LLM 논문이 화제입니다. 핵심 아이디어는 매력적입니다 — GPT나 LLaMA의 파라미터를 건드리지 않고(frozen backbone, 학습 파라미터 ~0.2%), 시계열 패치를 사전학습된 단어 임베딩 공간의 'Text Prototype'에 Cross-Attention으로 정렬시켜 예측하는 리프로그래밍 전략이죠. 모델 설계 문제를 representation 정렬 문제로 재정의한 점은 분명 흥미롭습니다. 하지만 데이터 분석가로서 실험 섹션부터 펼쳐야 합니다.
베이스라인 대비 실질 개선폭부터 봅시다. velog의 논문 리뷰에서도 솔직하게 지적하듯, ETTh1·ETTm2·Weather·Traffic 등 주요 벤치마크에서 PatchTST 대비 개선은 "소폭이지만 안정적"입니다. 여기서 질문이 생깁니다. 그 '소폭'이 통계적으로 유의한가요? 논문에서 여러 시드(seed)에 걸친 신뢰구간이나 p-value가 명시적으로 보고되었는지 확인이 필요합니다. MSE나 MAE 기준으로 소수점 셋째 자리에서 갈리는 차이라면, 그것이 데이터 분할이나 하이퍼파라미터에 의한 노이즈인지 실제 구조적 우위인지 ablation study만으로 구분하기 어렵습니다. 논문이 patch reprogramming과 Prompt-as-Prefix 각각의 기여도를 ablation으로 분리한 점은 긍정적이지만, 이 실험이 몇 회 반복되었고 분산이 어떤 수준이었는지가 재현 가능성(reproducibility)의 열쇠입니다.
진짜 강점은 few-shot/zero-shot에 있습니다 — 그리고 거기에 함정도 있습니다. Time-LLM이 "일관되게 큰 성능 향상"을 보인다는 few-shot 시나리오는 데이터가 부족한 프로덕션 환경에서 가장 절실한 영역입니다. 그러나 few-shot 실험의 샘플 사이즈 설정(5%·10% 등)과 데이터 선택 전략이 결과에 미치는 민감도를 면밀히 살펴야 합니다. 학습 데이터를 5%만 남겼을 때의 성능 개선이 '어떤 5%를 남겼느냐'에 따라 크게 흔들린다면, 이건 모델의 일반화 능력이 아니라 실험 설계의 행운일 수 있습니다. 또한 Text Prototype이 'seasonal', 'periodic', 'average' 같은 시계열 속성어로 수렴한다는 정성적 분석은 해석 가능성(interpretability) 측면에서 고무적이지만, 이것이 correlation인지 causation인지는 별개의 문제입니다.
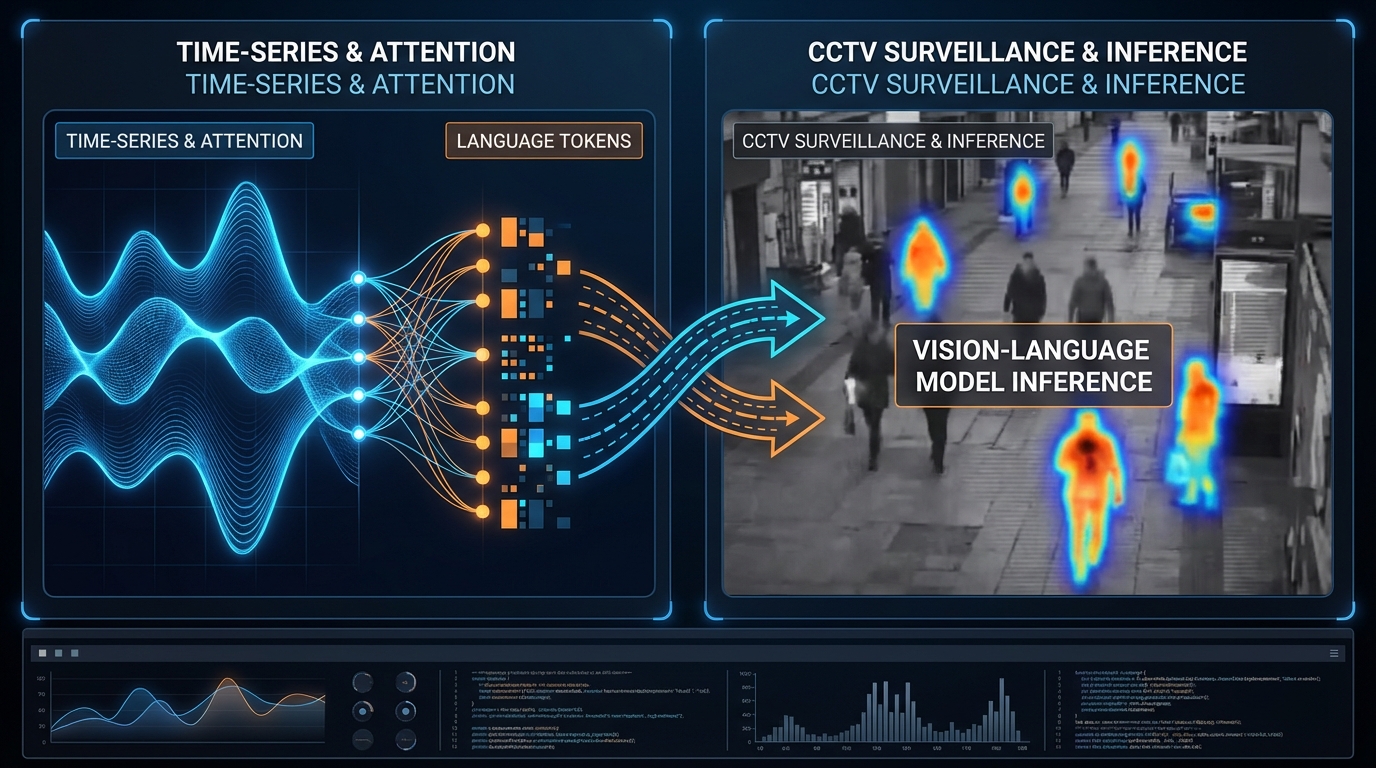
이 질문을 라온피플의 VLM 관제 사례에 그대로 던져봅시다. 라온피플은 CNN 기반 객체 검출의 맥락 이해 한계를 VLM(Vision-Language Model)으로 돌파한 '오딘 AI'를 프로덕션에 올렸습니다. aitimes 인터뷰에서 이석중 대표가 밝힌 수치 하나가 눈에 띕니다 — VLM 관제 도입 시 일반 CNN 대비 인프라 비용 증가가 1.2배에 그쳤다는 것. 이 지표가 latency, throughput, 정확도(Precision/Recall) 중 어떤 trade-off 위에 서 있는지가 핵심입니다. 비용이 1.2배인데 맥락 추론의 Recall이 유의미하게 올라갔다면 훌륭한 ROI이지만, 실제 관제 현장에서 VLM이 필요한 '중요 사건'이 거의 없다는 대표의 언급은 역설적으로 VLM의 프로덕션 가치를 base rate 문제로 환원합니다. 희귀 이벤트 탐지에서는 Precision-Recall 곡선의 우측 꼬리가 전부이고, 여기서 합성 데이터의 품질과 분포가 모델 편향을 결정짓습니다.
두 사례가 공유하는 본질적 문제는 '도메인 전이의 검증 프레임워크 부재'입니다. Time-LLM은 언어 → 시계열, 오딘 AI는 범용 VLM → 특정 관제 현장으로의 전이를 시도합니다. 두 경우 모두 벤치마크나 PoC에서의 성능이 프로덕션 일반화를 보장하지 않습니다. Time-LLM의 프롬프트 구성(데이터셋 컨텍스트, 통계 정보 선택)에는 "휴리스틱한 요소가 남아있다"고 논문 스스로 인정하며, 라온피플 역시 "제로샷으로 도입할 단계는 아니다"라고 명시합니다. 결국 도메인별 추가 설정, 합성 데이터 보강, 현장 PoC 반복이 불가피한데, 이 과정의 비용과 시간이 '전이 학습의 효율성'이라는 본래 가치 제안을 얼마나 잠식하는지를 정량화한 연구는 아직 부족합니다.
시사점을 정리하면 이렇습니다. 첫째, LLM의 도메인 전이를 평가할 때 full-data SOTA 비교보다 few-shot/zero-shot 시나리오에서의 개선폭과 그 통계적 유의성이 더 중요한 지표입니다. 둘째, 프로덕션 전이에는 모델 성능 외에 인프라 비용, latency 제약, 데이터 드리프트 대응, 합성 데이터 편향 관리라는 MLOps 차원의 검증 레이어가 반드시 병행되어야 합니다. 라온피플이 모델 경량화와 부분적 VLM 호출 전략, XAI 레이어 구축, Human-in-the-loop 체계를 동시에 추진하는 것은 이 현실을 정면으로 인식한 접근입니다.
전망은 조심스럽게 낙관적입니다. Time-LLM이 보여준 '표현 정렬' 패러다임과 라온피플이 실증하는 'VLM의 선택적 프로덕션 투입' 전략은, 멀티모달 foundation model이 범용 추론 엔진으로 진화하는 경로의 서로 다른 단면입니다. 다만 이 경로 위에서 "실제 운영 환경에서도 이 성능이 나오나요?"라는 질문에 신뢰구간과 비용 지표로 답할 수 있는 팀만이 벤치마크 너머의 가치를 증명할 것입니다. 숫자가 말하게 하되, 그 숫자의 출처와 분산까지 함께 말하게 해야 합니다.