핵심 이슈: 파이프라인은 돌아가는데, 검증은 어디에 있나요?
ML 파이프라인을 구축하는 실무자라면 한 번쯤 이런 경험이 있을 겁니다. 모델 학습 → 평가 → 배포까지 자동화해놓고, 정작 '이 모델이 공정한가', '이 통계 검정이 적절한가', '이 임베딩이 의미적으로 정확한가'라는 질문에는 명확한 답을 내지 못하는 상황. 최근 dev.to에 게시된 AI 공정성 실무 가이드, velog의 세 집단 비교 통계 검정 사례, 그리고 RAG 레시피 챗봇 구축기를 교차해서 읽어보니, 공통적으로 드러나는 빈 칸이 하나 있었습니다. '근거 기반 의사결정(evidence-based decision)'이 파이프라인 어디에도 구조적으로 내장되어 있지 않다는 점입니다.
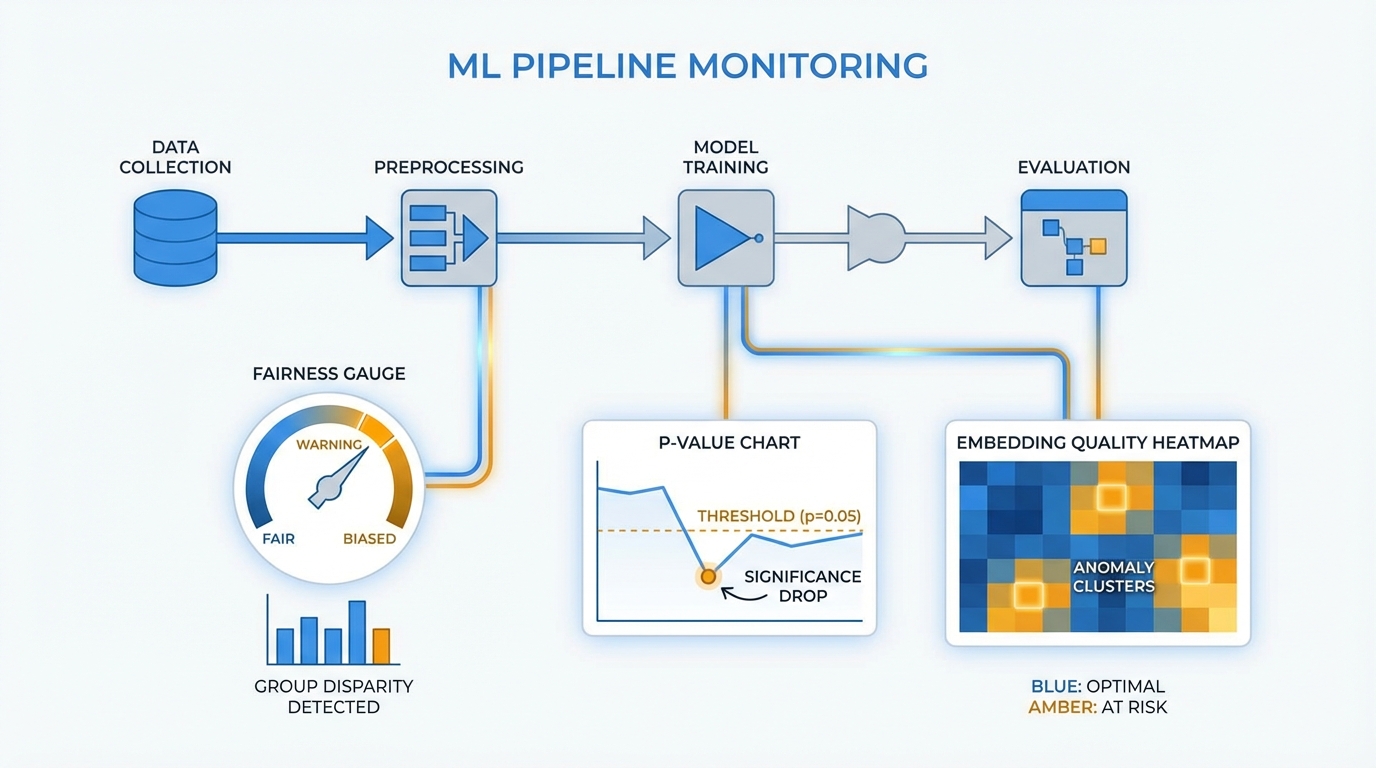
맥락 해석 ①: 편향 감지 — 임계값의 근거를 물어야 합니다
dev.to의 AI Ethics 가이드(Paul Robertson)는 Fairlearn과 IBM AI Fairness 360을 활용한 편향 감지 파이프라인을 제시합니다. DataBiasDetector 클래스에서 보호 속성(gender, race, age_group)별 representation bias를 체크하고, FairnessTestSuite에서 Demographic Parity Difference와 Equalized Odds Difference를 계산한 뒤, 임계값 0.1을 기준으로 PASS/FAIL을 판정하는 구조입니다.
여기서 데이터 분석가로서 첫 번째 질문을 던지겠습니다. 그 0.1이라는 threshold의 근거는 무엇인가요? 이 값은 미국 EEOC의 4/5 규칙(80% rule)에서 파생된 관행적 수치에 가깝지, 도메인별로 검증된 보편적 기준이 아닙니다. 대출 승인 모델에서의 0.1과 콘텐츠 추천 모델에서의 0.1은 완전히 다른 의미를 가집니다. 또한 outcome_diff > 0.2면 HIGH, > 0.1이면 MODERATE라는 분류도 — 샘플 사이즈에 따라 통계적 유의성이 전혀 달라질 수 있다는 점이 빠져 있습니다. selection rate 차이가 0.12라고 해서 그것이 통계적으로 유의미한 편향인지, 아니면 표본 변동(sampling variation)에 의한 노이즈인지를 구분하려면 신뢰구간(confidence interval)이나 부트스트랩 검정이 필요합니다.
더 중요한 건 프로덕션 환경에서의 드리프트입니다. 가이드가 제시한 FairnessMonitor는 SQLite에 시계열로 metric을 저장하고 dp_diff > 0.15일 때 alert를 트리거합니다. 좋은 시작이지만, 실제 운영 환경에서는 입력 데이터의 분포가 지속적으로 변합니다. 어제의 fairness metric이 오늘도 유효하다는 보장은 없습니다. 데이터 드리프트 감지와 공정성 모니터링을 연동하지 않으면, alert가 울렸을 때 그것이 모델의 문제인지 입력 분포의 변화인지 구분할 수 없습니다.
맥락 해석 ②: 통계 검정 — p-value 0.0이 말해주는 것과 말해주지 않는 것
velog의 세 집단 비교 사례는 건물용도별(아파트, 연립다세대, 오피스텔, 단독다가구) ㎡당 가격 차이를 Kruskal-Wallis 검정과 Dunn 사후검정으로 분석합니다. Q-Q plot에서 정규성을 기각하고, 비모수 검정으로 전환한 판단 자체는 교과서적으로 올바릅니다. 하지만 여기서 간과된 것이 있습니다.
각 그룹에서 9,534개씩 샘플링했습니다. 이 정도 샘플 사이즈에서 Kruskal-Wallis의 p-value가 0.0으로 나온 것은 사실상 당연합니다. n이 충분히 크면, 실질적으로 의미 없는 차이도 통계적으로 유의하게 나옵니다. 이것이 바로 '통계적 유의성 ≠ 실질적 유의성(practical significance)'의 고전적 함정입니다. 효과 크기(effect size) — 예컨대 Cohen's d나 eta-squared — 없이 p-value만으로 "차이가 있다"고 결론 내리는 것은, 근거의 절반만 제시하는 셈입니다. 실제로 아파트가 다른 용도보다 50~60% 높다는 기술통계는 유용하지만, 이것이 검정의 결론이 아니라 별도의 기술통계 분석이라는 구분이 필요합니다.
이 문제는 ML 파이프라인의 A/B 테스트에도 그대로 적용됩니다. 모델 A와 모델 B의 성능 차이가 p < 0.05로 유의하다고 해서 배포를 결정했는데, 실제 accuracy 차이가 0.001이라면? 베이스라인 대비 얼마나 개선되었는지, 그 개선이 인프라 비용 증가를 정당화할 만큼 실질적인지를 함께 봐야 합니다.
맥락 해석 ③: RAG 파이프라인 — 임베딩 품질은 누가 검증하나요?
velog의 RAG 한식 레시피 챗봇은 ko-sroberta-multitask 임베딩과 FAISS 벡터 DB, LLaMA 3.3 70B(Groq)를 조합한 구조입니다. chunk_size=500, chunk_overlap=50, top-k=5라는 설정으로 검색을 수행하는데, 여기서 질문합니다. 그 하이퍼파라미터의 선택 근거는 무엇인가요? chunk_size를 300으로 줄이거나 1000으로 늘렸을 때 retrieval precision은 어떻게 변하나요? top-k=3과 top-k=7의 차이는? 이런 ablation study 없이 설정된 파라미터는 경험적 감(gut feeling)일 뿐 근거가 아닙니다.
더 근본적으로, ko-sroberta-multitask가 레시피 도메인에서 얼마나 좋은 임베딩 품질을 보이는지 정량 평가가 빠져 있습니다. "존재하는 메뉴 → 정확한 레시피 출력, 없는 메뉴 → 미등록 안내"라는 정성적 확인은 좋지만, retrieval recall@k나 MRR(Mean Reciprocal Rank) 같은 검색 품질 지표로 측정하지 않으면 프로덕션에서 edge case가 터졌을 때 원인이 임베딩인지, 청킹인지, 프롬프트인지 분리할 수 없습니다. 이것은 correlation과 causation의 문제이기도 합니다 — "챗봇이 잘 답했다"는 결과(correlation)가 "임베딩이 좋다"는 원인(causation)을 증명하지 않습니다.
시사점: 검증 없는 파이프라인은 기술 부채입니다
세 사례를 관통하는 교훈은 명확합니다. 편향 감지에는 통계적 검증이 필요하고, 통계적 검증에는 효과 크기와 실질적 의미가 필요하고, RAG 파이프라인에는 임베딩·검색 품질의 정량 평가가 필요합니다. 이 세 가지가 빠진 ML 파이프라인은 자동화된 무지(automated ignorance)에 가깝습니다.
실무에서 당장 적용할 수 있는 체크리스트를 제안합니다: - 편향 감지: Demographic Parity 임계값을 설정할 때, 부트스트랩 신뢰구간을 함께 계산하고 도메인 전문가와 합의된 기준을 문서화할 것 - 통계 검정: p-value와 함께 반드시 효과 크기(effect size)를 보고할 것. n > 5,000이면 거의 모든 것이 유의하다는 사실을 기억할 것 - RAG 파이프라인: chunk_size, overlap, top-k에 대한 grid search를 수행하고, retrieval recall과 end-to-end answer quality를 분리 측정할 것
전망: 'Validation-First MLOps'의 시대
모델 정확도만 올리면 되던 시대는 끝났습니다. 이제 파이프라인의 모든 단계 — 데이터 수집, 전처리, 학습, 평가, 배포, 모니터링 — 에 검증 가능한 근거(verifiable evidence)가 내장되어야 합니다. Fairlearn의 generate_report()가 CI/CD에 통합되는 것처럼, 효과 크기 보고서와 임베딩 품질 벤치마크도 파이프라인의 gate로 작동해야 합니다. 실제 운영 환경에서도 이 성능이 나오는지 — 이 한 문장을 배포 버튼 위에 붙여놓는 것에서부터 시작할 수 있습니다.