"왜 느리죠?"가 아니라 "어디서 느리죠?"를 물어야 합니다
솔직히 말하면 저도 한때 <script>를 <body> 맨 아래에 두는 게 그냥 관례인 줄 알았습니다. Figma에서 시안 잡고 컴포넌트 찍어내는 데만 집중하다 보면, 브라우저가 내 코드를 어떤 순서로 해석하고 그리는지는 생각보다 멀리 있거든요. 그런데 Lighthouse 점수가 갑자기 떨어지거나, LCP가 3초를 넘기는 순간 — 그때서야 "렌더링 파이프라인"이라는 단어가 현실로 다가옵니다.
최근 velog에 올라온 브라우저 렌더링부터 React Fiber까지 글을 읽으면서, 그리고 같은 시기에 공유된 React Native Dimensions API 글과 CSS Cascading 원리 글을 함께 놓고 보니, 결국 하나의 맥락으로 수렴하더군요. 렌더링 파이프라인의 각 단계가 어디서 병목을 만드는지 모르면, 최적화는 '감'으로 하는 주술이 됩니다.
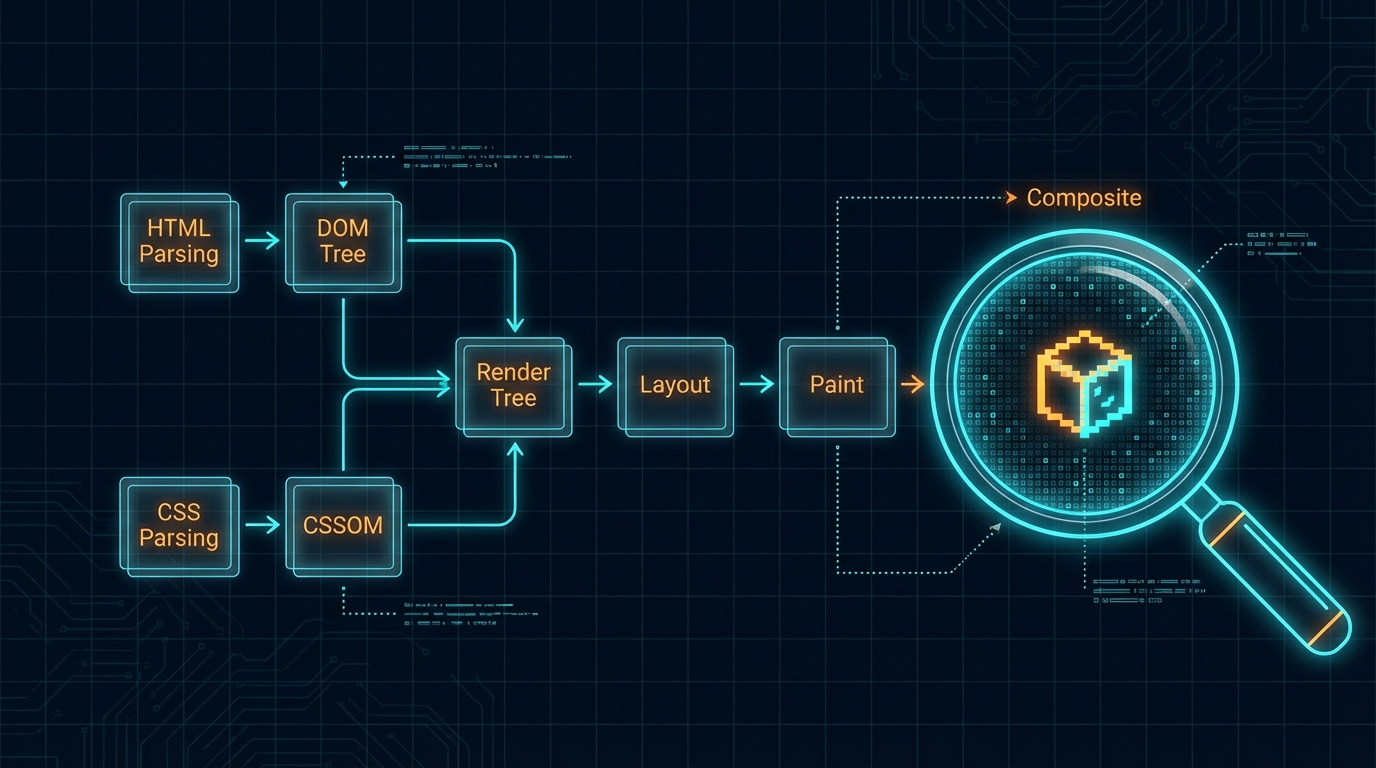
CRP의 연쇄 차단: CSS → JS → HTML 파싱, 이 순서가 전부입니다
브라우저의 Critical Rendering Path(CRP)는 단순해 보이지만 예민합니다. HTML이 네트워크 버퍼에 도착하는 즉시 점진적 파싱(Incremental Parsing)이 시작되고, 이 속도가 곧 LCP와 직결됩니다. 문제는 파서가 <script> 태그를 만나는 순간 멈춘다는 거예요. JavaScript가 document.write()로 DOM 구조 자체를 뒤집을 수 있는 "강력한 권한"을 갖고 있기 때문입니다.
여기에 CSS가 끼어듭니다. CSSOM이 완성되기 전에는 JS 실행 자체가 차단돼요. JS가 getComputedStyle()로 스타일 값을 참조할 수 있으니까요. 결국 "CSS는 JS 실행을 막고, JS는 HTML 파싱을 막는" 연쇄 차단이 발생합니다. async와 defer가 단순한 편의 속성이 아니라 이 병목을 정밀하게 제어하는 도구인 이유입니다.
사용자 입장에서는 이 연쇄 차단이 "흰 화면이 0.5초 더 길게 보이는" 것으로 체감됩니다. Figma에서 볼 때는 완벽했던 디자인이, 실제 구현에서 <head> 안의 렌더 블로킹 CSS 한 줄 때문에 First Paint가 밀리는 거죠.
Layout Thrashing부터 Composite까지: 1px을 옮기는 데도 비용 등급이 있습니다
CSSOM과 DOM이 합쳐져 Render Tree가 만들어진 뒤에도, 브라우저는 각 요소의 정확한 좌표를 모릅니다. %, em, vh 같은 상대 단위가 Layout(Reflow) 단계에서 물리 픽셀로 확정되는데, 이 과정이 생각보다 비쌉니다.
특히 Forced Synchronous Layout — 스타일을 바꾼 직후 offsetWidth를 읽는 패턴 — 이 루프 안에서 반복되면 매 반복마다 Reflow가 터지는 Layout Thrashing이 발생합니다. 프론트엔드 개발자라면 이거 한 번쯤 경험해 봤을 겁니다. 리스트 아이템 100개의 너비를 동적으로 바꾸는데 스크롤이 뚝뚝 끊기는 그 현상이요.
여기서 핵심은 스타일 변경의 비용 등급입니다. width나 margin을 건드리면 Reflow → Repaint → Composite 전 과정이 메인 스레드에서 돌아가지만, transform과 opacity는 해당 요소를 별도 Composite Layer로 승격시켜 GPU가 처리합니다. 같은 "1px 이동"이라도 top: 1px과 translateY(1px)의 렌더링 비용은 차원이 다릅니다. will-change: transform으로 레이어 승격을 미리 힌트하는 게 애니메이션 60fps의 관건인 이유죠.
React Fiber가 끼어드는 지점: 브라우저의 한계를 프레임워크가 보완합니다
브라우저의 렌더러 프로세스 안에서 렌더링 엔진(Chrome의 Blink)과 JS 엔진(V8)은 메인 스레드를 공유합니다. 한쪽이 스레드를 잡고 있으면 다른 쪽은 대기해야 해요. React의 이전 재조정(Reconciliation) 알고리즘은 Virtual DOM 비교를 한 번에 동기적으로 수행했기 때문에, 대규모 상태 변경 시 메인 스레드를 오래 점유하며 Jank를 유발했습니다.
Fiber 아키텍처는 이 작업을 작은 단위(Fiber Node)로 쪼개고, 각 프레임의 여유 시간에 나눠 처리하는 시간 분할 스케줄링을 도입했습니다. 사용자 인터랙션 같은 높은 우선순위 작업이 들어오면 진행 중이던 렌더링을 일시 중단하고 먼저 처리할 수 있게 된 거죠. 결국 Fiber는 "브라우저 메인 스레드의 공유 자원 문제"를 프레임워크 레벨에서 우회하는 전략입니다.
반응형까지 연결하면: 런타임 레이아웃 계산의 진짜 비용
CSS Cascading 규칙 — 중요도, 명시도(Specificity), 선언 순서에 따른 우선순위 결정 — 은 CSSOM 생성 시점에 모두 해결됩니다. 이 과정이 복잡해질수록 Style Calculation 비용이 올라가고, 이는 곧 Layout 단계의 입력값에 영향을 줍니다.
React Native 환경에서도 본질은 같습니다. Dimensions.get('window')가 정적 상수로 박제되는 문제, useWindowDimensions Hook으로 회전·폴더블 대응을 하는 패턴, PixelRatio로 dp와 물리 픽셀 간 변환을 처리하는 전략 — 이 모든 것이 결국 "런타임에 레이아웃을 다시 계산하는 비용을 누가, 언제 부담하느냐"의 문제입니다. 피그마 기준 375px 디자인을 scale() 함수로 비례 변환하는 접근이 실무에서 쓰이는 이유도, 매 프레임마다 브레이크포인트를 재평가하는 비용을 줄이기 위해서죠.
시사점: 파이프라인을 모르면 최적화가 아니라 추측입니다
정리하면 이렇습니다. CRP의 연쇄 차단을 이해해야 defer와 preload를 제대로 쓸 수 있고, Reflow-Repaint-Composite의 비용 등급을 알아야 애니메이션 속성을 올바르게 선택할 수 있으며, Fiber의 시간 분할 스케줄링을 알아야 useDeferredValue나 useTransition 같은 API의 존재 이유가 납득됩니다.
프론트엔드 성능 최적화는 Lighthouse 점수를 1점 올리기 위한 트릭이 아닙니다. 브라우저가 1px을 그리기까지의 전체 경로를 머릿속에 그릴 수 있을 때, 비로소 "어디를 건드려야 하는지"가 보이기 시작합니다. 저요? 저는 그래서 오늘도 Chrome DevTools의 Performance 탭을 열고, Layout Shift 빨간 블록을 노려보고 있습니다.