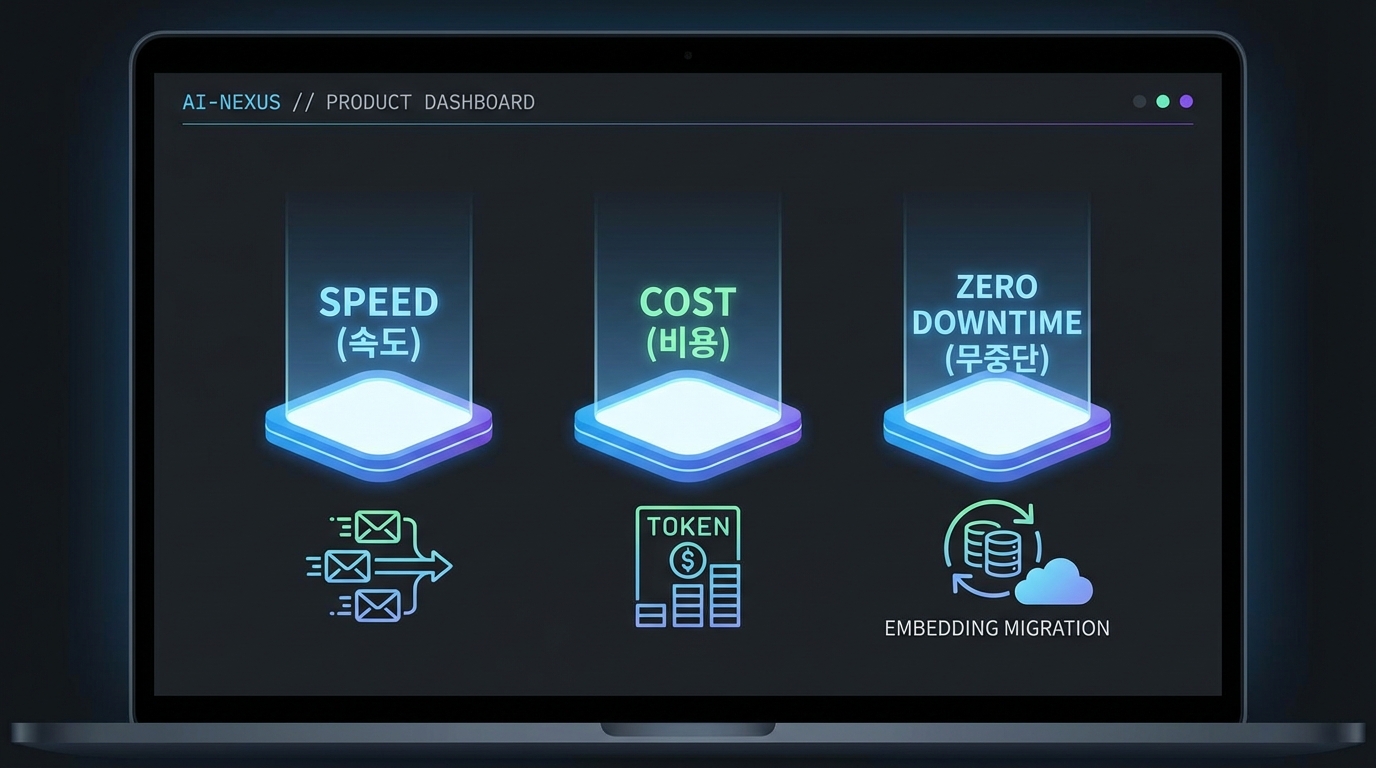
LLM 기능이 붙는 순간, 제품 성장은 모델 성능보다 퍼널의 체감 속도(응답/처리시간)·안정성·비용(토큰/인프라)에 의해 결정됩니다. 유저는 “똑똑함”보다 “안 기다림”에 먼저 반응하고, 팀은 “잘 됨”보다 “예측 가능한 비용”에 살아남습니다. 이번 소스들은 그 지점을 정확히 찌릅니다: 비동기로 대기시간을 깎고, RAG의 토큰 낭비를 줄이고, 임베딩/데이터를 무중단으로 교체해 실험 속도를 올리는 방법들이요.
먼저 속도. velog의 RabbitMQ 비동기 처리 사례는 LLM 호출/크롤링 같은 n초짜리 I/O 바운드 작업을 요청-응답 경로에서 분리합니다(출처: velog ‘RabbitMQ로 비동기 처리’). API 서버는 큐에 메시지만 넣고 즉시 응답, 워커가 독립적으로 처리하니 사용자는 4초짜리 작업을 기다리지 않고 ms 단위로 빠져나갑니다. 이거다 싶었던 포인트는 “성능 최적화”가 아니라 퍼널 최적화라는 점입니다. 대기시간이 길면 Activation 이전에 이탈이 터지고, 동기 처리로 서버가 밀리면 장애가 곧 CAC 상승(광고 유입이 버려짐)으로 연결됩니다.
두 번째는 비용. dev.to의 스마트 청킹 글은 “Vertex AI 청구서가 트래픽과 무관하게 오른다”는 현상을 모델 탓이 아니라 토큰 아키텍처 탓으로 돌립니다(출처: dev.to ‘Smart Chunking’). 핵심은 Parent–Child Retrieval: 약 500토큰의 child로 정확히 찾고, 약 3,000토큰의 parent로 묶어 중복을 제거해 전달합니다. 이렇게 하면 비슷한 질문에서 매번 조금씩 겹치는 청크를 여러 개 보내는 실수가 줄고, 캐싱 임계치(예: 2,048 토큰) 조건도 안정적으로 맞춰 토큰 낭비를 최대 40%까지 줄일 수 있다는 주장입니다. “비용 최적화는 미세조정”이 아니라, ARPU 대비 COGS를 통제해 LTV/CAC 비율을 지키는 성장 전략이라는 메시지가 명확합니다.
세 번째는 무중단. 임베딩 모델이 예고 없이 deprecated 되면 RAG는 바로 망가집니다. dev.to의 임베딩 마이그레이션 플레이북은 이를 48시간 내, 다운타임 없이 처리한 절차를 공개합니다(출처: dev.to ‘Zero-Downtime Embedding Migration’). 요지는 단순하지만 강력합니다: (1) 모델/차원을 env로 분리해 하드코딩 제거, (2) 기존 컬럼을 지우지 말고 v2 컬럼을 추가해 병행, (3) 인덱스는 CONCURRENTLY로 락 없이 생성, (4) 배치 재임베딩 + 레이트리밋, (5) 결과 겹침(오버랩)으로 드라이런 검증, (6) 피처 플래그로 트래픽 스위치. 이 구조는 “배포 리스크↓ = 실험 속도↑”로 직결됩니다. 모델 A/B, 임베딩 교체, 리트리벌 튜닝을 롤백 가능한 상태로 상시 운영할 수 있으니까요.
여기에 대규모 동기화 운영 감각을 더해주는 글이 6만 상품 싱크 사례입니다(출처: dev.to ‘Syncing 60,000 Products…’). 웹훅 기반(푸시)으로 받고 202로 즉시 응답 후 Celery 비동기 처리, 그리고 “변경된 것만 임베딩”하도록 해시 기반 스킵 로직을 둡니다. 한 번의 풀 리싱크에서 실제 변경이 200개라면 59,800개의 임베딩을 건너뛰는 식이죠. 이거 바이럴 될 것 같은 포인트는 B2B 온보딩에서도 같습니다. “연동 한 번에 서버 녹음”은 최악의 첫 경험인데, 비동기·배치·스킵 조합은 온보딩 실패율을 확 줄여줍니다.
시사점은 세 가지로 정리됩니다. ① 응답 경로에서 ‘느린 일’을 분리하세요: 큐/워커로 비동기화하면 p95 latency를 낮추고 장애를 격리해 리텐션이 움직입니다. ② 토큰은 기능이 아니라 과금 단위입니다: 청킹/중복제거/캐싱 친화 설계로 COGS를 안정화하면 가격 실험(프리미엄/크레딧)도 공격적으로 할 수 있습니다. ③ 모델·임베딩 교체는 “언젠가”가 아니라 “항상” 일어납니다: 컬럼 병행 + 검증 + 피처 플래그를 기본값으로 두면, 배포 공포가 줄어들고 실험 루프가 빨라집니다. 빨리 테스트해봐야 돼요.
전망: LLM 제품 경쟁은 “더 큰 모델”에서 “더 빠른 운영”으로 이동 중입니다. 앞으로의 승부처는 (1) 비동기 파이프라인으로 체감 속도를 낮추고, (2) RAG 토큰 아키텍처로 비용을 예측 가능하게 만들고, (3) 무중단 마이그레이션으로 실험을 상시화하는 팀입니다. 결국 성장 지표로 번역하면 간단합니다. 대기시간↓ → 전환↑, 토큰 낭비↓ → ARPU 방어↑, 무중단 배포↑ → 실험 속도↑. 이 세 레버를 잡는 팀이 PMF 이후 스케일 구간에서 더 멀리 갑니다.