근거는 있나요? — 두 논문의 '상호 의존'이라는 블라인드 스팟
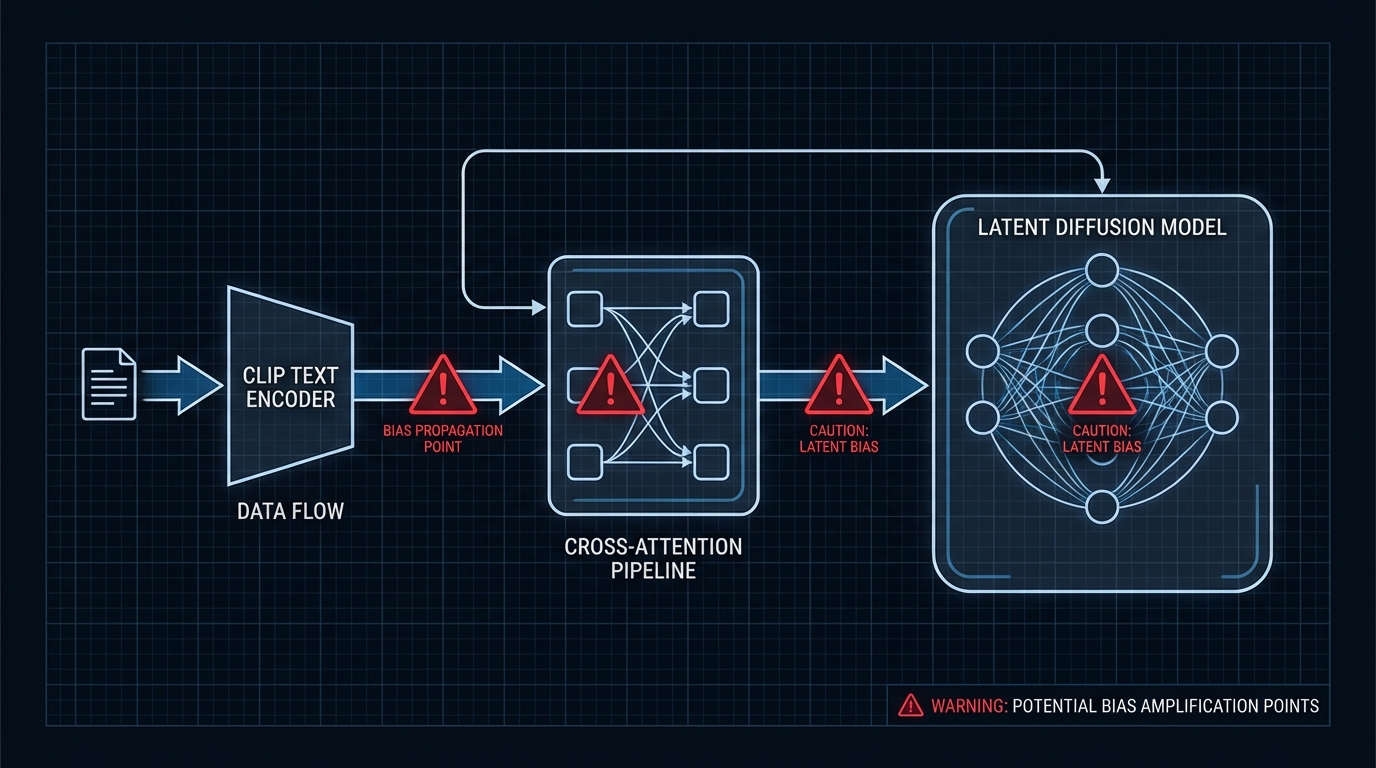
CLIP(ICML 2021)과 Latent Diffusion Models(CVPR 2022)은 각각 멀티모달 표현 학습과 고해상도 이미지 생성의 랜드마크 논문입니다. 그런데 실무에서 이 둘은 독립된 모델이 아닙니다. Stable Diffusion 파이프라인에서 CLIP 텍스트 인코더의 출력이 LDM U-Net의 Cross-Attention에 Key/Value로 주입되어 조건부 생성을 제어합니다. 즉, CLIP의 임베딩 품질이 LDM의 생성 품질의 상한선이 됩니다. 그런데 두 논문 어디에도 이 '상류→하류' 편향 전파에 대한 체계적 ablation은 존재하지 않습니다.
CLIP의 제로샷 일반화, 샘플 사이즈는 충분하되 분포는 의심스럽다
CLIP은 웹에서 수집한 약 4억 개의 이미지-텍스트 쌍(WIT, WebImageText)으로 contrastive learning을 수행했습니다. 샘플 사이즈 자체는 압도적입니다. 문제는 분포(distribution)입니다. 웹 크롤링 데이터는 영어 중심이고, 서구 문화권의 시각적 맥락에 과대 대표(over-represented)되어 있습니다. 논문 자체도 ImageNet-A 등 분포 변화에 대한 robustness를 강조하지만, 이는 ImageNet 변종 내에서의 robustness이지 진정한 cross-cultural 일반화를 증명하는 것은 아닙니다. 'A photo of a {class}' 같은 prompt template을 앙상블하여 성능을 부스팅하는 전략도, 결국 영어 문법 구조에 최적화된 텍스트 인코더의 편향을 반영합니다. 이건 correlation이지 causation이 아닙니다 — 제로샷 정확도가 높다고 해서 임베딩 공간이 편향 없이 구성되었다는 증거는 되지 않습니다.
LDM의 연산 비용 절감, 베이스라인 대비 '얼마나' 개선되었나요?
LDM 논문의 핵심 주장은 pixel-space diffusion 대비 latent space에서의 연산량 대폭 감소입니다. CelebA-HQ에서 기존 likelihood 모델과 GAN 대비 우수한 FID를 보고하고, 적은 sampling step에서도 높은 FID 성능을 유지한다고 합니다. 여기서 데이터 분석가로서 몇 가지 질문이 생깁니다. 첫째, 오토인코더의 perceptual compression 단계에서 제거되는 '불필요한 디테일'의 기준은 누가 정하나요? 이 기준 자체가 학습 데이터의 분포에 종속됩니다. 둘째, Precision/Recall 지표에서 mode-covering 특성이 보존된다는 보고는 고무적이지만, 실제 운영 환경에서 다양한 프롬프트 분포에 대해서도 이 성능이 나올까요? 논문의 실험은 학술 벤치마크 데이터셋에 한정되어 있습니다.
편향의 배달 경로: CLIP → Cross-Attention → 생성 이미지
여기서 진짜 문제가 드러납니다. LDM의 Cross-Attention 메커니즘은 U-Net feature를 Query로, CLIP 텍스트 임베딩을 Key/Value로 사용합니다. CLIP 임베딩에 내재된 사회적 편향 — 특정 직업군의 성별 연관, 인종별 시각적 스테레오타입 — 이 Key/Value를 통해 attention weight에 직접 반영됩니다. 결과적으로 'a photo of a CEO'라는 프롬프트가 특정 인종·성별의 이미지를 과도하게 생성하는 현상은, LDM 자체의 문제가 아니라 상류(upstream) 인코더인 CLIP의 학습 데이터 편향이 하류(downstream) 생성 모델로 전파된 결과입니다. 두 논문 모두 이 파이프라인 수준의 편향 전파에 대한 정량적 분석을 제공하지 않습니다.
저작권이라는 또 하나의 데이터 품질 문제
이 편향 논의를 더 복잡하게 만드는 것이 학습 데이터의 저작권 문제입니다. 최근 경향신문 보도에 따르면, Anthropic의 'Project Panama' 사례에서 미국 법원이 종이 책 구매 후 스캔·학습을 '공정 이용'으로 판결했습니다. CLIP의 WIT 데이터셋 역시 웹에서 크롤링한 이미지-텍스트 쌍이며, 수집 과정의 저작권 처리는 불투명합니다. 데이터셋의 구성이 불투명하면 편향의 원인을 추적(audit)할 수 없고, 편향을 추적할 수 없으면 하류 모델의 공정성도 보장할 수 없습니다. 세종대 최승재 교수의 지적처럼 '사용 권리 중심 정책'이 창작 생태계를 훼손하는 동시에, 데이터 시장 형성 기회를 소멸시킬 수 있다는 점은 ML 파이프라인의 데이터 품질 관점에서도 심각한 문제입니다.
시사점: 파이프라인 전체를 하나의 실험으로 봐야 합니다
결국 CLIP→LDM 파이프라인의 성능을 평가할 때, 개별 논문의 FID나 제로샷 정확도만으로는 절반의 그림만 보는 셈입니다. 필요한 것은 파이프라인 수준의 ablation study입니다. CLIP 인코더를 다른 텍스트 인코더(예: T5, LLaMA 기반)로 교체했을 때 생성 품질과 편향이 어떻게 변화하는지, 오토인코더의 downsampling factor(f=4, 8, 16)별로 편향 전파율이 달라지는지. 이런 실험 없이 'SOTA 달성'을 주장하는 것은, df.describe()만 보고 데이터를 이해했다고 말하는 것과 같습니다.
전망: 투명한 데이터 계보(Data Lineage)가 다음 SOTA의 조건이 됩니다
제주대 노대원 교수가 지적한 '학습 데이터셋 비공개 관행'의 개선은 단순한 윤리적 요청이 아닙니다. 재현 가능성(reproducibility)과 편향 감사(bias audit)의 전제 조건입니다. 향후 생성 AI의 진짜 경쟁력은 모델 아키텍처의 참신함이 아니라, 학습 데이터의 계보를 추적할 수 있고, 편향을 정량적으로 측정·완화할 수 있는 파이프라인 거버넌스에서 나올 것입니다. 다음에 누군가 '우리 모델이 FID를 5포인트 개선했다'고 말하면, 이렇게 물어보세요 — "그 5포인트, 어떤 데이터에서 나왔고, 그 데이터에는 어떤 편향이 있나요?"