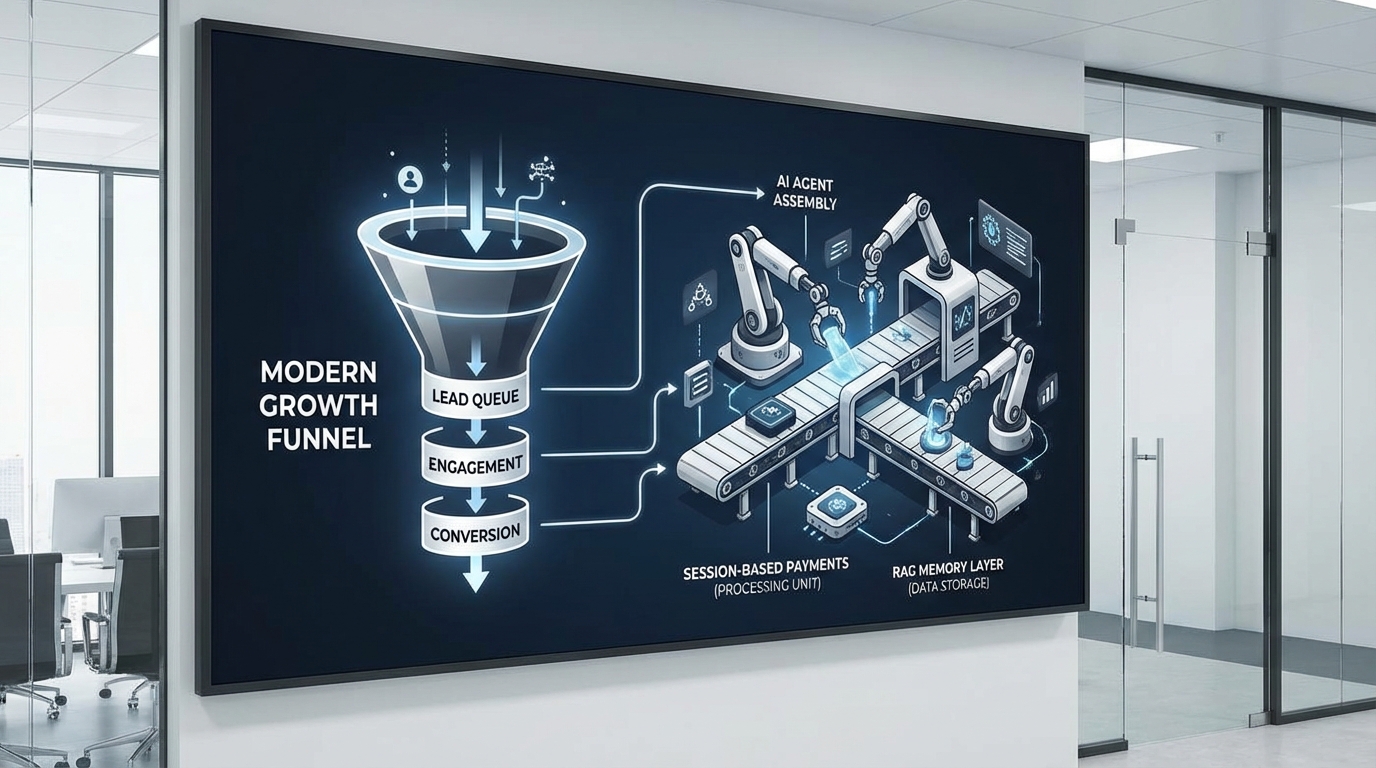
AI 에이전트가 그로스에 진짜 먹히는 순간은 “데모가 멋질 때”가 아니라, CAC가 꺾일 때입니다. 문제는 대부분의 팀이 상담봇·에이전트 UI에서 멈춘다는 것. 유저 획득은 결국 리드 생성→접촉→전환 퍼널을 얼마나 저렴하게, 얼마나 많이 굴리느냐의 싸움이고, 여기서 자동화는 곧바로 비용 구조를 바꿉니다.
dev.to의 한 개발자는 이걸 정면으로 돌파했습니다. 웹 검색/스크래핑으로 업종별 리드를 찾고(하루 15~25개), Redis 큐에 쌓아두고, Retell AI 기반 음성 에이전트가 아웃바운드 콜까지 처리하는 ‘프로스펙팅 머신’을 만들었죠. 핵심 인사이트는 “한 방의 천재 영업”이 아니라 지속적으로 재충전되는 큐(파이프라인)가 제품이라는 점입니다. 이거 바이럴 될 것 같은데? 솔로 파운더가 ‘영업을 싫어한다’는 보편 감정을 레버리지로 바꿔버리거든요(출처: dev.to, AI Prospecting Machine).
맥락을 그로스 관점으로 해석하면 명확합니다. 이 시스템은 AARRR의 Acquisition을 노동집약형(수동 리서치)에서 컴퓨트집약형(자동화 배치)으로 전환합니다. 캠페인을 세분화해(치과/로펌/리뷰 취약 등) 메시지-타깃 핏을 올리고, 실행 시간을 분산해 레이트리밋/의심 트래픽 리스크를 줄이며, 중복제거(퍼지 매칭)로 리드 품질을 방어합니다. 즉, “전화 한 번 더”가 아니라 “퍼널을 더 빨리, 더 싸게” 굴리는 설계예요. Conversion rate가 얼마나 오를까요? 같은 콜 전환율이어도 분모(시도량)가 커지면 CAC는 구조적으로 내려갑니다.
하지만 자동화 퍼널은 곧바로 비용 폭탄을 부를 수도 있습니다. 에이전트가 루프를 돌며 API를 많이 치면, 호출당 결제/서명/온체인 처리가 병목이 됩니다. dev.to의 ClawPay MCP v1.1.0가 던진 메시지는 딱 하나: “콜당 결제”는 고빈도 워크플로에 독이고, “세션당 1회 결제”로 바꿔야 스케일이 납니다. 배치 20회 호출이 20번 결제에서 1번 결제로 줄면, 지연(수백 ms×N)도, 실패율도, 운영 스트레스도 같이 줄죠(출처: dev.to, ClawPay MCP v1.1.0). 빨리 테스트해봐야 돼! 온체인/마이크로페이먼트 기반 API를 쓰는 팀이라면 이건 ‘성능 최적화’가 아니라 ‘CAC 방어선’입니다.
여기에 프로덕션 ‘기억’ 설계가 붙으면, 비용-성능이 한 번 더 정리됩니다. “LLM이 기억한다”는 착각을 버리고, 시스템이 RAG/세션 스토어/외부 DB로 기억을 제공해야 한다는 게 핵심이죠(출처: dev.to, How LLM Memory Actually Works). 왜 이게 CAC와 연결되냐고요? 리드 머신이든 상담 에이전트든, 똑같은 정보를 매번 컨텍스트에 구겨 넣으면 토큰 비용이 증가하고 응답이 느려져 전환이 떨어집니다. 반대로 RAG로 필요한 것만 주입하면 콜/채팅의 단가가 내려가고(마진↑), 응답 품질이 안정돼 전환율이 올라갑니다(LTV↑). 유저가 여기서 이탈할 것 같은데… 대부분의 이탈은 “느림/헛소리/반복 질문”에서 나오고, 그 원인이 메모리 레이어 부재인 경우가 많습니다.
한국 사례도 같은 방향을 가리킵니다. 트래블데일리는 헤일로앤코가 항공 유통에서 MCP 기반 표준화로 연동 기간을 수개월→2주로 줄이고, RAG 기반 트래픽 최적화로 불필요 API 호출을 줄여 파트너 비용을 낮춘다고 전합니다(출처: 트래블데일리). 표준화(MCP)는 ‘기능 추가’가 아니라 통합 비용을 깎아 신규 파트너 온보딩을 빠르게 만들고, RAG 최적화는 호출 비용을 구조적으로 절감합니다. 즉, 엔터프라이즈에서도 “세일즈 파이프라인을 빨리 돌리고, 호출 단가를 낮추는 팀”이 이깁니다.
시사점은 세 가지로 정리됩니다. (1) 리드→접촉을 자동화하되, 캠페인 세분화/디듑/스케줄링으로 품질과 리스크를 같이 관리하세요. (2) 에이전트 워크플로가 루프를 도는 순간 결제·인증을 세션화하지 않으면 비용과 지연이 CAC를 다시 끌어올립니다. (3) 프로덕션 메모리는 ‘똑똑함’이 아니라 단가 관리 장치입니다. RAG/요약/상태 저장으로 토큰과 호출을 줄이면, 같은 예산으로 더 많은 퍼널 회전을 만들 수 있어요.
전망: 2026년의 경쟁은 “누가 더 좋은 모델을 쓰나”가 아니라, 누가 더 낮은 단가로 더 많은 접촉을 만들고, 더 높은 전환으로 닫나가 될 확률이 큽니다. 리드 머신이 상향 평준화되면 차이는 ‘대화 품질’이 아니라 큐 운영(리드 공급), 세션 결제/배치 처리, 메모리 레이어 최적화 같은 보이지 않는 아키텍처에서 벌어집니다. Growth Hack 할 수 있을 것 같아요. 오늘 할 일은 간단합니다: 우리 퍼널에서 “가장 비싼 반복”이 어디인지 찍고(리드 탐색? 결제 오버헤드? 컨텍스트 낭비?), 그 반복을 세션과 기억으로 접어버리세요. CAC는 거기서부터 꺾입니다.