핵심 이슈: "AI 코딩 비용"은 도구가 아니라 아키텍처의 문제다
AI 코딩 에이전트를 팀에 도입하고 나면, 가장 먼저 부딪히는 벽은 품질이 아니라 비용입니다. Claude한테 물어보니까 실제로 대규모 레포를 통째로 컨텍스트에 밀어넣는 순간, 한 번의 리서치 세션에 $5~15가 증발하더라고요. 개인이면 감수하겠지만, 팀 단위로 하루 수십 번 에이전트를 호출하면 월 API 비용이 수백만 원을 쉽게 넘깁니다. 문제는 이 비용 구조를 "어쩔 수 없는 것"으로 받아들이는 팀이 대부분이라는 겁니다.
하지만 최근 dev.to에 공유된 세 가지 실전 사례를 엮어보면, 토큰 효율화 + 로컬/클라우드 듀얼 오케스트레이션 + AI 디버깅 도구라는 세 겹의 레이어로 비용을 95%까지 깎으면서도 품질을 유지하는 구체적인 인프라 전략이 보입니다. AI-First 팀이라면 도구 "도입"이 아니라 도구 "스택 설계"에 집중해야 할 시점입니다.
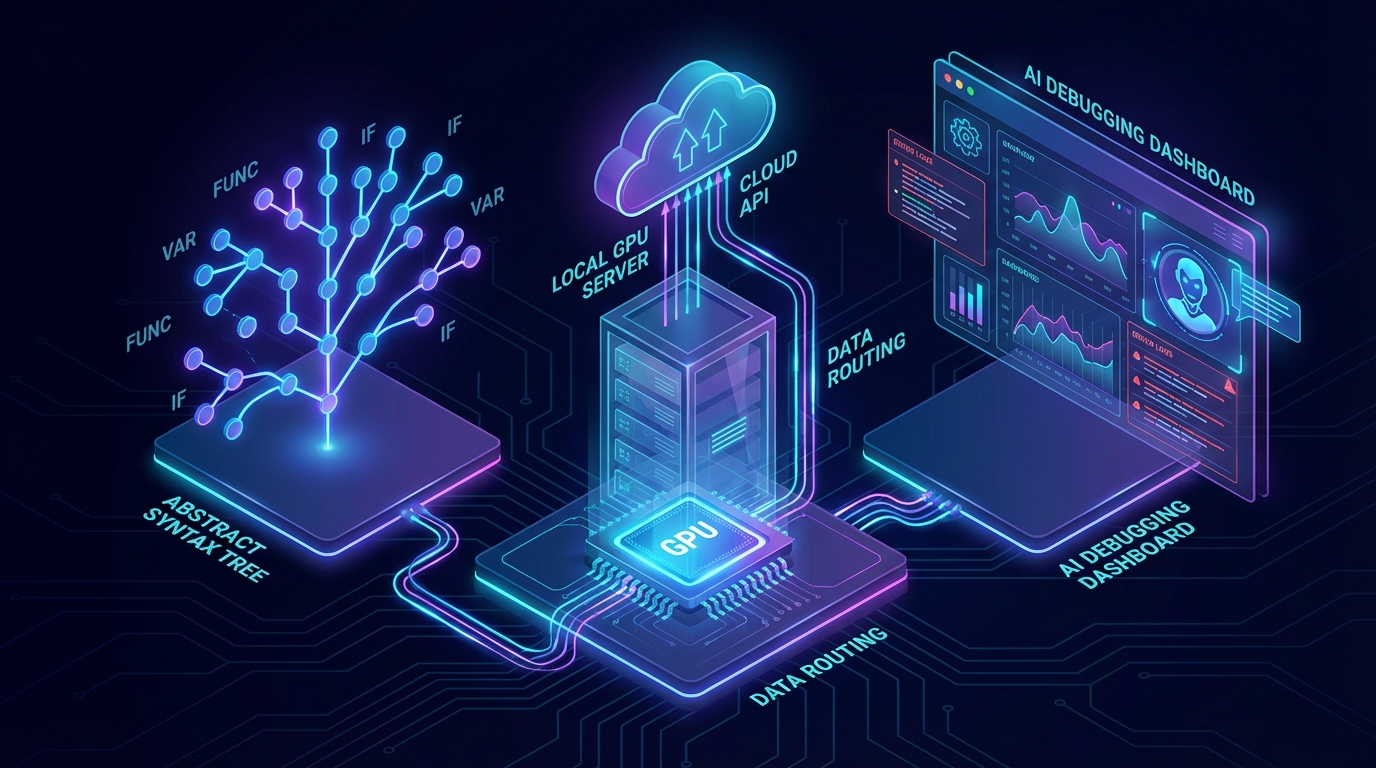
레이어 1: 코드 RAG로 토큰부터 깎는다
개발자 badmonster0가 공개한 cocoindex-code는 MCP(Model Context Protocol) 기반의 초경량 코드 RAG 서버입니다. 기존 코드 RAG가 벡터 DB 구축, ETL 파이프라인, 스키마 관리라는 인프라 프로젝트 수준의 부담을 요구했다면, 이 도구는 Tree-sitter 기반 AST 파싱으로 함수·클래스·블록 단위의 의미 있는 청크만 추출합니다. Rust 엔진 위에서 변경된 파일만 증분 인덱싱하니, 리팩토링 직후에도 에이전트가 즉시 최신 코드를 참조할 수 있습니다.
이걸 팀 워크플로우에 끼면 어떤 일이 생기냐면요—에이전트가 "폴더 통째로 읽기" 대신 "필요한 함수만 정확히 가져오기"로 전환됩니다. 원저자는 토큰 70% 절감을 보고했는데, 팀 규모로 환산하면 이건 단순한 절약이 아니라 "같은 예산으로 3배 더 많은 에이전트 호출"이 가능해진다는 뜻입니다. Claude, Codex, OpenCode 어디에든 uvx 한 줄로 붙으니, 온보딩 비용도 거의 제로입니다.
레이어 2: 로컬 80% + 클라우드 20%의 듀얼 모델 라우팅
토큰을 줄여도 호출 자체가 전부 클라우드로 가면 비용 구조는 바뀌지 않습니다. 개발자 Rayne Robinson이 공유한 "듀얼 모델 오케스트레이션" 패턴은 이 문제를 정면으로 풉니다. 핵심은 간단합니다: 수집·스캔·스코어링·검증은 로컬 모델(Qwen3 8B + Ollama)이 처리하고, 최종 합성·판단만 Claude API로 보낸다.
실제 수치가 인상적입니다. 50개 아이템 기준 리서치 파이프라인에서 올 클라우드는 $8~15, 듀얼 모델은 $0.15~0.40. 95~97% 비용 절감이면서 합성 품질은 프론티어 모델 수준을 유지합니다. 물론 고통 포인트도 있습니다—로컬 모델의 thinking 토큰 과다 생성, GPU 메모리 한계, Docker 네트워킹 삽질, 그리고 라우팅 로직을 직접 짜야 한다는 점. 하지만 이건 팀 차원에서 한 번 인프라를 세팅하면 모든 후속 도구가 상속받는 구조이므로, 투자 대비 회수가 압도적입니다.
레이어 3: AI 디버깅 도구로 "시간 비용"까지 깎는다
토큰 비용과 API 비용을 깎아도, 개발자의 시간이 디버깅에 빠지면 팀 전체의 처리량이 떨어집니다. Jaideep Parashar가 정리한 AI 디버깅 도구 카테고리는 이 "보이지 않는 비용"을 체계적으로 압축합니다. 로그·트레이스 요약기로 수천 줄을 타임라인으로 압축하고, 코드베이스 Q&A로 컨텍스트 복원 시간을 30~60분 단축하고, AI 가설 생성기로 비구조적 탐색을 구조적 실험으로 전환합니다.
여기서 중요한 건 저자가 강조하는 세 가지 원칙입니다: AI가 제안하고, 내가 결정한다. 모든 수정에 테스트를 붙인다. 증상이 아니라 의도를 디버깅한다. AI로 리뷰 받아보니까 이런 원칙 없이 "AI가 찾아준 대로 고치기"를 반복하면, 단기 속도가 장기 신뢰성 부채로 바뀝니다. 이건 팀 그라운드 룰로 박아둬야 하는 내용입니다.
시사점: 세 레이어를 하나의 팀 스택으로 엮기
이 세 가지를 조합하면 팀 차원의 AI 코딩 비용 최적화 스택이 완성됩니다. 코드 RAG(cocoindex-code)로 에이전트에 넘기는 토큰을 70% 줄이고, 듀얼 모델 라우팅으로 남은 호출의 80%를 로컬에서 무료로 처리하며, AI 디버깅 도구로 개발자의 시간 비용까지 압축합니다. dev.to의 또 다른 글에서 제시된 "Quality per Dollar(Qp$)" 프레임워크—Composite_Score = (w1 × Quality) - (w2 × Cost) - (w3 × Latency)—를 팀 대시보드에 올려두면, 최적화가 감이 아니라 지표로 관리됩니다.
전망: "도구 공장"이라는 사고 전환
기획 단계부터 AI를 끼면 훨씬 효율적이에요—그런데 이제는 "어떤 AI를 어디에 끼느냐"가 팀의 경쟁력을 가릅니다. Rayne Robinson이 자신의 셋업을 "tool factory"라고 부른 것처럼, 듀얼 모델 오케스트레이션 + 코드 RAG + 구조화된 디버깅이라는 인프라를 한 번 세팅하면, 이후 만드는 모든 AI 워크플로우가 이 아키텍처를 상속받습니다. 이거 자동화하면 우리가 더 중요한 일에 집중할 수 있어요—바로 "어떤 제품을 만들 것인가"라는 본질적 질문에요. 비용을 95% 깎는 건 시작일 뿐이고, 진짜 목표는 팀원 전원이 이 스택 위에서 AI-First로 사고하는 문화를 만드는 겁니다.