테스트셋 정확도 93%, 그래서 프로덕션에서도 93%인가요?
근거는 있나요? ML 모델을 프로덕션에 올릴 때 가장 먼저 던져야 할 질문이지만, 놀라울 만큼 자주 생략됩니다. 정확도, F1-score, C-index 같은 지표가 테스트셋에서 빛나는 순간, 우리는 '검증 완료'라는 착각에 빠집니다. 하지만 실제 운영 환경은 데이터 분포가 다르고, 시간이 흐르면 드리프트가 발생하며, 모델이 마주하는 엣지 케이스는 학습 데이터에 존재하지 않았던 것들입니다. 이번 주 눈에 띈 세 가지 사례는 각기 다른 도메인—의료 AI, 로봇 제어, 에이전트 안전성—에서 출발하지만, 모두 같은 질문으로 수렴합니다. '모델이 잘 된다'를 어떤 메커니즘으로 증명할 것인가.
정밀 종양학: Precision·Recall로는 '임상 추론'을 측정할 수 없다
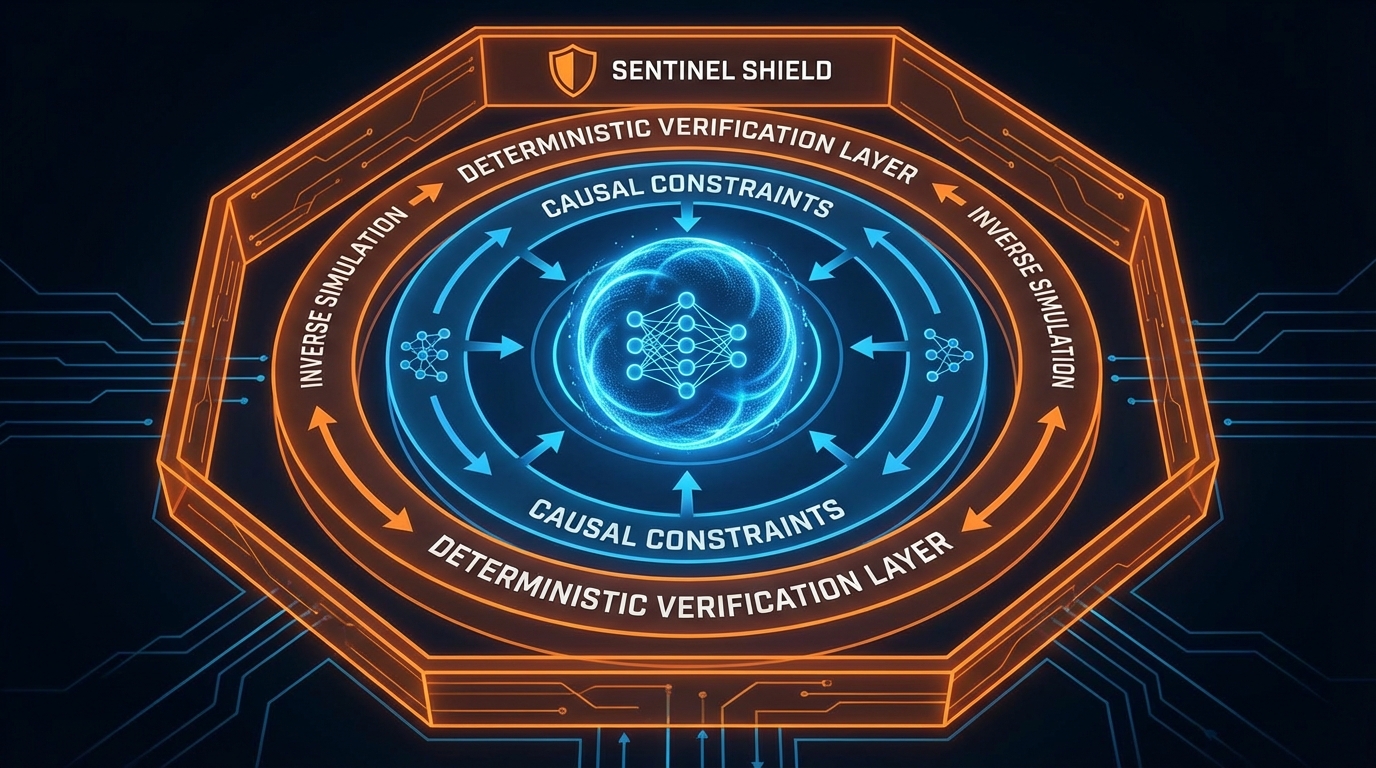
Dev.to에 공개된 정밀 종양학 임상 AI 검증 방법론은 문제를 정확히 짚습니다. 바이오마커 검출의 Precision·Recall을 아무리 높여도, 임상의가 실제로 수행하는 반복적 가설 검증, 멀티모달 데이터 통합, 반사실적(counterfactual) 추론이라는 프로세스 자체를 평가하지는 못한다는 것입니다. 이 연구가 제안하는 핵심은 두 가지입니다. 첫째, Pyro 기반의 인과적(causal) 제약 조건을 걸어 생성형 시뮬레이션으로 합성 환자 여정을 만들되, 순수 데이터 기반 생성기(GAN·VAE)가 빠지기 쉬운 생물학적 비개연성(biological implausibility)을 차단합니다. 둘째, '역시뮬레이션 검증(inverse simulation verification)'으로 결과에서 거꾸로 추론하여 의사결정 과정 자체의 정합성을 검사합니다.
데이터 분석가 관점에서 가장 흥미로운 건 인과 발견(causal discovery) 알고리즘과 도메인 지식 제약의 결합입니다. PC 알고리즘으로 관측 데이터에서 인과 구조를 학습하고, 여기에 임상 가이드라인이라는 하드코딩된 제약을 덧입히는 구조는 사실상 ablation study를 구조적으로 강제하는 셈입니다. 다만 질문을 던지지 않을 수 없습니다. 이 합성 환자 데이터의 분포가 실제 임상 코호트를 얼마나 대표하는지, 역시뮬레이션이 수렴하는 해(solution)의 유일성은 보장되는지—샘플 사이즈와 재현 가능성 문제는 논문의 실험 섹션에서 반드시 확인해야 합니다.
로봇 VLA: 400 에피소드의 '체감 검증'
Google AI 블로그에 소개된 VLA 로봇 학습 프로젝트는 완전히 다른 축에서 같은 문제를 드러냅니다. 개발자가 SmolVLA 모델로 SOARM101 로봇 팔을 훈련시켜 유아용 보드게임 'First Orchard'의 과일을 집어 옮기는 과제를 수행하는데, 데이터 수집 과정이 적나라합니다. 태스크 4개 × 100 에피소드 = 총 400 에피소드를 수작업 텔레오퍼레이션으로 모았고, SmolVLA를 20,000 스텝(~2시간)에서 100,000 스텝까지 올렸을 때 정성적으로 '유의미하게' 개선되었다고 보고합니다.
여기서 데이터 분석가의 본능이 발동합니다. 400 에피소드가 엔드투엔드 정책 학습에 충분한 샘플 사이즈인가요? 성능 개선의 '유의미함'은 어떤 정량 지표로 측정했나요? 이 실험에서 가장 솔직한 대목은 Pi0-Fast 모델로 200,000 스텝을 돌린 뒤 로봇 팔이 스스로 접혀 카메라 마운트를 부러뜨린 사건입니다. 이것은 correlation과 causation의 문제가 아니라, 학습 스텝 수와 아키텍처 선택이 프로덕션 안전성과 직결된다는 냉정한 현실입니다. 베이스라인 대비 몇 퍼센트 개선이라는 숫자 없이, '잘 된다'와 '장비가 부서진다' 사이의 경계는 주관적 판단에 맡겨집니다.
Constitutional Sentinel: 결정론적 계층이라는 안전망
세 번째 사례는 AI 에이전트 안전성 패턴으로, 'Constitutional Sentinel'이라는 개념입니다. 핵심은 단순합니다. 확률적(probabilistic) 모델 위에 결정론적(deterministic) 검증 계층을 씌우는 것. banned_actions 리스트와 max_spending_limit 같은 하드코딩된 규칙이 LLM의 tool_call을 가로채고, 통과·차단·사람 검토로 분기합니다. 구조적으로 올바른 JSON을 생성하더라도 '논리적으로 안전한가'는 별개의 문제라는 점을 명시적으로 분리한 것입니다.
이 패턴을 앞의 두 사례에 대입하면 검증 파이프라인의 공통 뼈대가 보입니다. 정밀 종양학의 역시뮬레이션은 임상 도메인에 특화된 결정론적 제약이고, VLA 로봇 학습에서 빠져 있었던 것이 바로 물리적 안전 경계를 강제하는 센티넬 계층입니다. Pi0 모델이 팔을 부러뜨린 건 모델 성능의 문제이기 이전에, 관절 각도의 물리적 한계를 하드코딩하지 않은 파이프라인 설계의 문제입니다.
시사점: 검증은 '지표'가 아니라 '아키텍처'다
세 사례를 관통하는 교훈은 명확합니다. ML 모델의 프로덕션 검증은 단일 지표(accuracy, F1, RMSE)의 문제가 아니라, 검증 파이프라인 자체의 아키텍처 설계 문제입니다. 역시뮬레이션으로 추론 과정을 역추적하고, 인과 제약으로 합성 데이터의 개연성을 강제하고, 결정론적 센티넬로 확률적 오류의 실행을 차단하는 것—이 세 가지는 모두 '모델 바깥'에서 모델을 감시하는 구조입니다.
실제 운영 환경에서도 이 성능이 나올까요? 이 질문에 대답하려면, 모델 카드에 적힌 숫자가 아니라 그 숫자를 만들어낸 실험 설계의 엄밀성을 먼저 검증해야 합니다. 베이스라인은 무엇이었는지, 데이터 분포에 어떤 편향이 있었는지, 실패 케이스의 분류 체계는 갖춰져 있는지. '잘 된다'의 근거는 모델 안에 있지 않습니다. 모델을 둘러싼 검증 아키텍처 안에 있습니다.