프론트엔드에서 "빠르다"는 말은 사실 두 가지 의미가 섞여 있습니다. 하나는 JavaScript 엔진이 계산을 빨리 끝내는 것이고, 다른 하나는 사용자가 화면이 빠르다고 느끼는 것입니다. Lighthouse 점수를 1점 올리려고 밤을 새워본 분이라면 아시겠지만, 이 둘은 놀라울 정도로 자주 어긋납니다. React 생태계에서 최근 주목할 만한 세 가지 움직임—Fiber 아키텍처의 재조명, React Router의 Loader/Action 패턴, TanStack Query의 Key 설계 논쟁—은 결국 이 간극을 메우려는 시도의 서로 다른 레이어입니다.
렌더링 엔진의 재설계: Fiber가 "끊김"을 없앤 방법
React 16 이전의 렌더링은 재귀 호출 스택 기반이었습니다. 한 번 시작하면 컴포넌트 트리 전체를 동기적으로 순회해야 했고, 그 사이 브라우저는 페인트도, 이벤트 처리도 할 수 없었습니다. Velog에 올라온 Fiber 해부 글이 잘 정리한 것처럼, 이건 "React가 빠르다"는 통념과 정면으로 충돌하는 구조였죠.
Fiber는 이 문제를 "반복 가능한 객체 기반 트리"로 풀었습니다. 각 컴포넌트가 { type, props, state, child, sibling, return } 형태의 Fiber 노드가 되면서, 작업을 잘게 쪼개고(time-slicing), 우선순위를 매기고, 중간에 브라우저에 제어권을 돌려줄 수 있게 된 겁니다. 사용자 입장에서는 텍스트 입력 중 키보드 반응이 100ms 씹히느냐 아니냐의 차이인데, 개발자 입장에서는 렌더링 파이프라인 전체가 재귀에서 이터레이션으로 바뀐 패러다임 전환입니다. Hydration조차 이 스케줄링 안에서 하나의 작업 단위로 처리된다는 점—Figma에서 볼 때는 같은 화면인데 SSR → CSR 전환 시 깜빡임이 느껴진다면, 이 레이어를 의심해야 합니다.
데이터 페칭의 위치 이동: useEffect에서 Loader로
Fiber가 "어떻게 그릴지"를 재설계했다면, React Router의 Loader 패턴은 "무엇을 언제 준비할지"를 재배치합니다. dev.to의 Loader/Action 해설에서 보여주듯, 기존의 useEffect + useState 콤보는 컴포넌트가 마운트된 이후에 데이터를 요청합니다. 화면은 이미 그려졌는데 데이터가 없으니 스켈레톤이 번쩍이고, CLS(Cumulative Layout Shift)가 튀죠.
Loader는 이 순서를 뒤집습니다. 라우트 진입 시점에 데이터를 먼저 확보하고, 컴포넌트는 useLoaderData()로 이미 준비된 데이터를 꺼내 씁니다. useEffect 없이, 로딩 상태 분기 없이, 컴포넌트가 렌더되는 순간 콘텐츠가 완성되어 있는 구조입니다. Action과 <Form> 컴포넌트도 같은 철학인데—useState로 폼 값 관리하고, handleSubmit에서 e.preventDefault() 쓰고, 에러 핸들링 분기 태우던 보일러플레이트가 라우터 레벨의 선언적 패턴으로 흡수됩니다. useNavigation으로 submitting 상태만 잡아주면 버튼 하나에 로딩 인디케이터 넣는 것도 3줄이면 끝이에요.
솔직히 이거, 처음 보면 "그냥 데이터 페칭 위치 옮긴 거 아닌가?" 싶을 수 있는데요. 사용자 입장에서는 페이지 전환 시 빈 화면이 보이느냐 vs. 이전 화면이 유지되다가 새 화면이 완성된 채로 전환되느냐의 차이입니다. Core Web Vitals로 치면 LCP와 CLS가 동시에 개선되는 지점이고, 이건 px 단위보다 더 근본적인 체감 품질의 문제입니다.
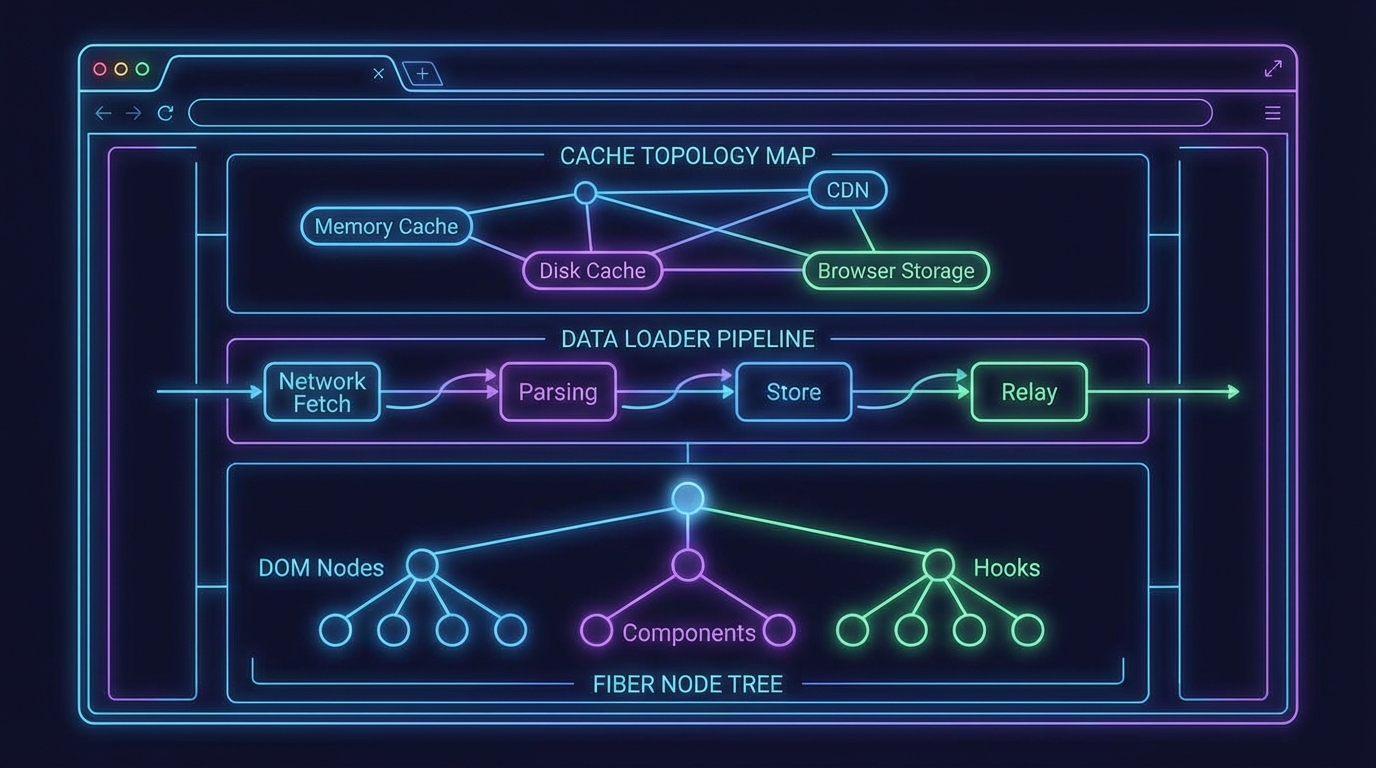
캐시 토폴로지의 설계: Query Key는 "이 데이터가 무엇인가"의 선언
Fiber가 렌더링을, Loader가 데이터 타이밍을 잡았다면, 마지막 레이어는 캐시의 구조입니다. Velog의 Query Key 논쟁 글이 다루는 문제—['kr', 'products'] vs. ['products', { country: 'kr' }]—는 단순한 배열 순서 취향이 아닙니다. 이건 캐시를 앱 상태로 볼 것이냐, 서버 데이터의 동기화 레이어로 볼 것이냐의 아키텍처 결정입니다.
원문 필자의 결론에 저도 동의하는 편인데요. country를 최상위에 두면 invalidateQueries({ queryKey: ['kr'] })가 직관적으로 보이지만, 실제로 국가 전환은 invalidation이 아니라 새로운 쿼리의 실행입니다. gcTime이 알아서 정리해주죠. 반면 리소스를 앞에 두면 invalidateQueries({ queryKey: ['products'] })가 "products 전체 재검증"이라는 명확한 시맨틱을 갖게 됩니다. React Query Devtools에서 리소스 단위로 그루핑해서 볼 수 있다는 점도—디버깅할 때 이거 의외로 큰 차이예요. country가 앞에 오면 products 관련 쿼리만 모아보는 게 불가능해집니다.
여기에 TypeScript 제네릭 기반 Query Key Factory까지 조합하면, 새 리소스 추가 시 createQueryKeys('reviews') 한 줄이면 일관된 키 구조가 보장됩니다. 인터페이스로 params 타입을 잠그면 country 빠뜨리는 실수도 컴파일 타임에 잡히고요. TkDodo가 강조하는 "React Query is a data synchronization tool, not a state manager"라는 원칙이 코드 레벨에서 실현되는 순간입니다.
세 레이어가 만나는 지점
정리하면 이렇습니다. Fiber는 렌더링 작업을 쪼개서 브라우저가 숨 쉴 틈을 만들고, Loader는 데이터를 라우트 진입 시점으로 끌어올려 빈 화면을 제거하며, Query Key 설계는 캐시의 의미 구조를 바로잡아 불필요한 리페칭과 디버깅 비용을 줄입니다. 이 세 가지는 각각 다른 추상화 레이어에 있지만, 공통적으로 "사용자가 기다리는 시간을 구조적으로 줄인다"는 하나의 목표를 향하고 있습니다.
앞으로 React 19의 Server Components와 use() 훅이 안정화되면, Loader 패턴과 서버 사이드 데이터 페칭의 경계가 더 흐려질 가능성이 높습니다. Fiber 기반의 Selective Hydration은 이미 그 방향으로 움직이고 있고요. 결국 프론트엔드 성능 최적화의 전장은 "더 빠른 코드"가 아니라 "더 똑똑한 스케줄링"으로 이동하고 있습니다. 번들 사이즈 깎는 것도 중요하지만, 그 1프레임 안에서 무슨 일이 일어나는지를 이해하는 게 먼저입니다.