배경: “모델 성능”보다 “내 시간”이 병목이 된 시점
YC Lightcone Podcast 대화 이후, calv.info의 글(“Coding Agents in Feb 2026”)은 코딩 에이전트를 고르는 기준이 ‘최고 모델’이 아니라 ‘내가 지금 확보한 시간’으로 이동했다고 정리한다. 낮에 함께 붙어서 2~3시간 협업할지, 밤새 80% 초안을 돌려둘지에 따라 에이전트 선택이 달라진다는 얘기다. 흥미로운 지점은 도구 구성이 “한 가지 올인”이 아니라는 것. 글의 저자는 Claude Max, ChatGPT Pro, Cursor Pro+를 모두 결제하며, 이를 가장 효율적인 지출 중 하나로 평가한다. 팀 관점으로 번역하면, 에이전트는 ‘대체재’가 아니라 ‘포트폴리오’가 되고 있다는 신호다.
핵심 분석: 코딩 에이전트의 본질은 ‘컨텍스트 관리 능력’
원문이 반복해 강조하는 원리는 단순하다. 에이전트는 마법이 아니라 next-token prediction이며, 모든 추론은 컨텍스트 윈도우에 갇힌다. 따라서 성능 차이는 파라미터/학습데이터만이 아니라 “컨텍스트를 어떻게 구성·요약·재사용·분할하느냐”에서 크게 벌어진다. 여기서 파생되는 운영 규칙은 실무적으로 꽤 날카롭다. (1) 문제를 컨텍스트 윈도우에 들어갈 크기로 chunking하지 않으면 에이전트가 빙빙 돌며 품질이 급락한다. (2) compaction(요약)은 손실 기법이라, 요약을 과신할수록 성능 저하가 누적된다. (3) 컨텍스트를 대화창에 쌓기보다 파일시스템(예: 체크리스트형 plan 문서)로 외부화하면, 에이전트가 필요한 부분만 선택적으로 읽고 “기억”할 수 있다. 또 하나 중요한 개념이 ‘스마트 존’이다. 컨텍스트가 꽉 차면(원문 표현으로 dumb zone), 장문 문맥에서의 학습/추론 한계 때문에 결과가 흔들린다. 그래서 장기 작업일수록 “대화에 다 넣기” 대신 progressive disclosure(점진적 공개) 구조—여러 개의 작은 Markdown 문서로 아키텍처를 나누고, 필요할 때만 로드—가 효과적이라고 제안한다. 이 관점은 “에이전트 성능”을 “리포지토리 설계 문제”로 끌고 온다.
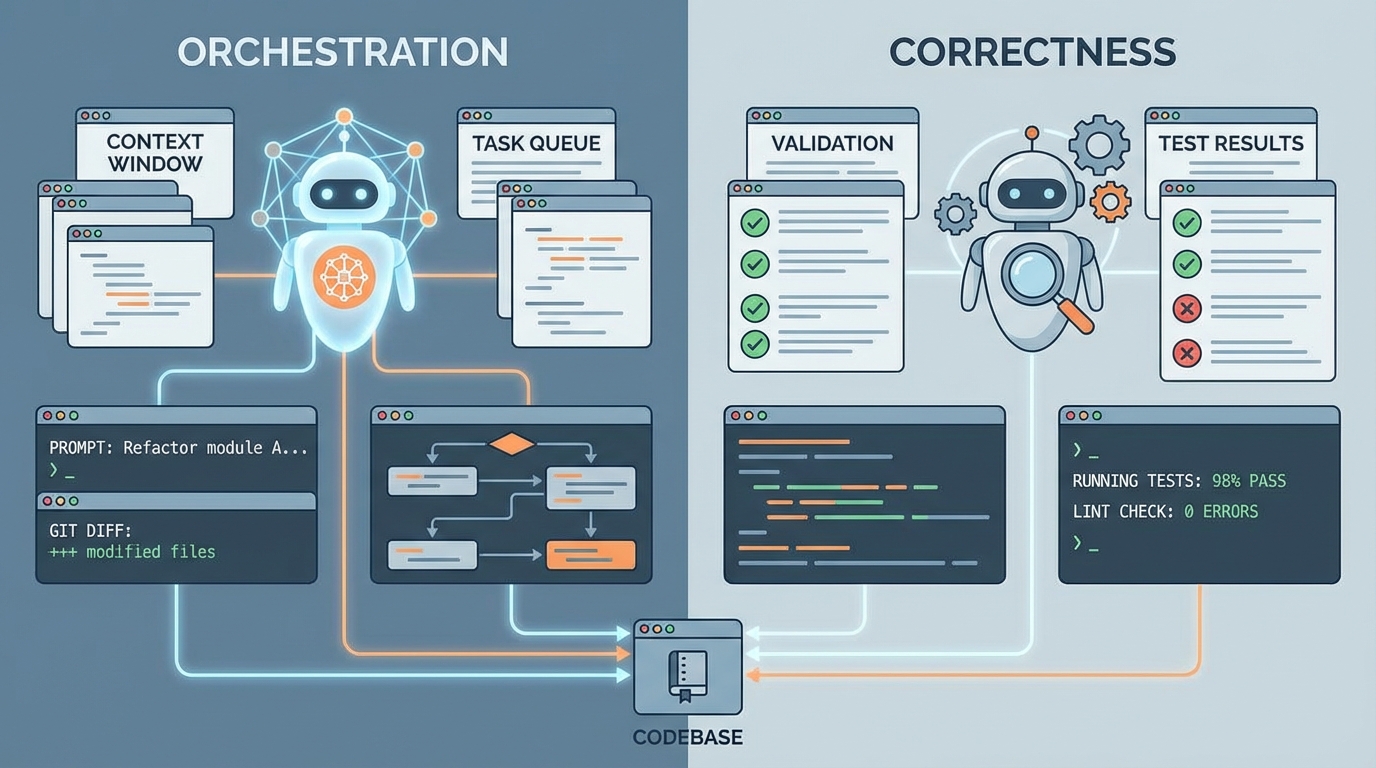
비교/대조: Opus(Claude Code) vs Codex—속도(오케스트레이션) vs 정확성(버그 밀도)
원문이 제시하는 결론은 명확한 역할 분담이다. Claude Code + Opus는 ‘컨텍스트 오케스트레이션과 툴 사용’에서 강하고, Codex는 ‘코드 정확성(버그가 적음)’에서 강하다. 팀이 체감하는 차이는 단순한 응답 품질이 아니라, “일을 어떻게 쪼개 병렬로 처리하느냐”에서 나온다.
Opus 쪽 강점은 두 가지다. 첫째, 여러 컨텍스트 윈도우를 효율적으로 넘나들며 서브에이전트를 병렬로 띄워 탐색/작업을 분담한다. 특히 Explore를 빠른 모델(Haiku)로 돌려 대량 토큰을 훑고, 핵심만 Opus에 전달하는 방식은 “큰 저장소를 빠르게 스캔”하는 팀 작업에 가깝다. 둘째, gh/git/MCP 서버 등 로컬 툴 사용이 매끈하고, Claude Code의 권한/명령 프리픽스 모델이 비교적 이해하기 쉬워 운영 리스크가 낮다고 말한다.
반대로 Codex는 실제 PR에 섞여 들어오는 자잘한 결함의 빈도에서 우위가 있다고 평가한다. 예시로, Opus가 유닛 테스트는 통과시키는 React 컴포넌트를 만들고도 최상위
시사점: 2026년 코딩 에이전트 도입의 승부처는 ‘리포 구조 + 운영 프로토콜’
이 글이 제품 비교를 넘어 주는 메시지는, 코딩 에이전트의 ROI는 모델 스펙이 아니라 팀의 컨텍스트 운영 능력에서 결정된다는 점이다. 특히 (1) 파일시스템에 계획을 남겨 재개 가능하게 만들기, (2) 저장소를 토큰 효율적으로 설계하기, (3) 에이전트가 놓친 파일/패키지로 인해 엉뚱한 방향으로 가는 리스크를 줄이는 정보 공개 방식이 “에이전트 시대의 기본기”가 된다. 또한 ‘느리지만 정확한 모델’과 ‘빠르지만 오케스트레이션 중심인 모델’이 공존하면, 팀은 단일 표준을 강요하기보다 단계별로 최적 도구를 지정하는 편이 낫다. 즉, 기획/탐색/설계/자동화는 Claude Code(툴링 강점), 구현/정확성 검증은 Codex(버그 밀도 낮음)처럼 파이프라인을 나누는 게 합리적이다. 이는 “개발자 1명이 만능”에서 “에이전트 조합을 설계하는 테크 리드 역량”으로 무게중심이 이동한다는 뜻이기도 하다.
실행 가이드: AI-First 팀에 바로 적용하는 5가지 체크리스트
1) plans/ 폴더를 표준화: 작업마다 번호가 붙은 계획 문서를 만들고(체크박스/단계/완료 조건 포함), 에이전트가 대화 대신 이 문서를 읽고 갱신하게 한다. 2) 컨텍스트 예산을 정한다: “대화창 60% 이상 채우지 않기”처럼 팀 규칙을 두고, 장기 작업은 문서로 분할해 progressive disclosure로 제공한다. 3) Claude Code는 ‘탐색/오케스트레이션’ 역할로 고정: 코드베이스 설명, gh/git 자동화, 다이어그램/PR 설명 생성, MCP 연동(사내 도구 포함)에서 생산성을 뽑는다. 4) Codex는 ‘구현/리뷰 게이트’로 배치: 핵심 PR은 Codex 기반 리뷰(/review 등)로 한 번 더 거치게 하고, 결함 유형(누락/경계조건/레이스)을 체크리스트화한다. 5) 병렬 서브에이전트 운영을 전제로 태스크를 쪼갠다: “탐색(파일 찾기)–설계–구현–검증”을 분리하고, 탐색은 빠른 모델/서브에이전트에 맡겨 메인 모델 컨텍스트를 ‘스마트 존’에 유지한다.
이 글(calv.info)의 관찰은 결국 하나로 요약된다. 2026년의 코딩 에이전트 경쟁은 모델 스펙표보다, 컨텍스트를 얼마나 잘 설계하고 병렬로 운영하느냐에서 승패가 난다.