AI 평가자는 얼마나 믿을 수 있나요?
'AI가 AI를 평가한다'는 구조는 요즘 ML 파이프라인에서 점점 흔해지고 있습니다. LLM-as-Judge 패턴이 자동화 평가의 표준처럼 자리잡고 있죠. 그런데 저는 이 흐름을 볼 때마다 항상 같은 질문을 던집니다. "근거는 있나요? 그 평가자는 calibrated되어 있나요?"
최근 세 가지 실험—GPT-4o·Claude·Gemini 교육 자료 채점 연구, AI 코딩 에이전트 컨텍스트 파일 비용 실험, 로컬 분류기 벤치마크—을 함께 읽으면, LLM을 측정하고 평가하는 방법론 전체에 걸쳐 동일한 통계적 함정이 반복된다는 걸 알 수 있습니다.
핵심 이슈: 평가자 간 일치도가 흔들린다
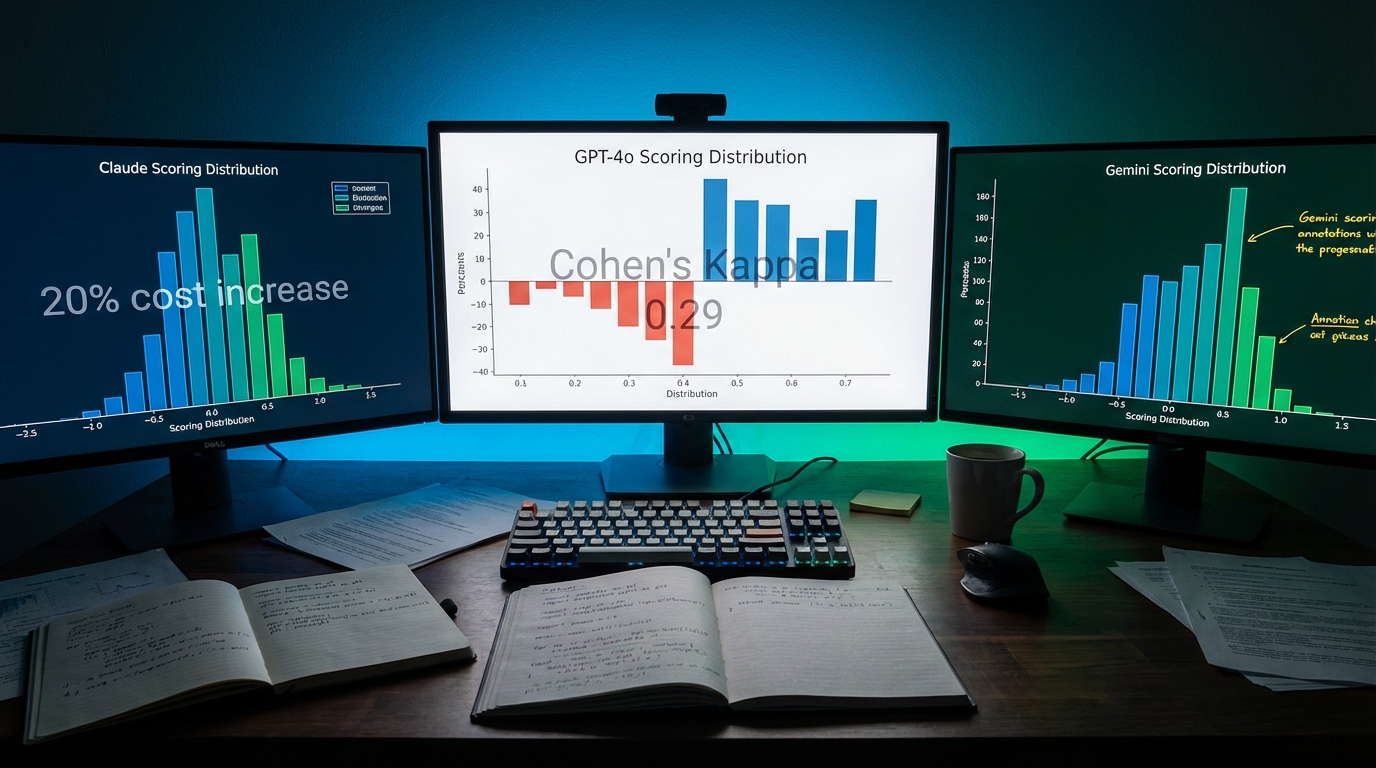
지디넷코리아가 소개한 워싱턴주립대·뉴욕주립대 버팔로 공동 연구(Judging the Judges, arXiv)는 GPT-4o, Claude Sonnet 4, Gemini 2.5 Pro 세 모델에게 미국 초중등 과학 수업 자료 12개 단원을 EQuIP 루브릭(9개 항목, 0~3점)으로 평가하게 하고, 결과 648개를 두 명의 교육 전문가가 검토했습니다.
표면적 숫자만 보면 나쁘지 않습니다. AI 점수에 대한 전문가 평균 동의율 69.6%, 이유 설명 동의율 86.1%. 하지만 ML 데이터 분석가로서 제가 먼저 확인한 건 평가자 간 일치도(inter-rater agreement) 입니다.
물리과학 분야에서 두 인간 전문가의 코헨 카파(Cohen's Kappa)는 약 0.29였습니다. 통계적으로 이건 '미약한 일치(slight to fair agreement)' 구간입니다. 지구과학(~0.49)과 생명과학(~0.47)도 '보통 수준(moderate)'을 겨우 넘는 정도입니다. 즉, 골든 레이블 자체가 흔들립니다. 베이스라인이 노이즈로 가득 차 있는데, AI 채점의 정확도를 그 베이스라인 대비 얼마나 의미 있게 해석할 수 있을까요?
모델별 편향: 이건 correlation이지 calibration이 아닙니다
세 모델의 채점 성향 차이는 데이터에서 뚜렷합니다. Gemini 2.5 Pro는 평균 2.96점(3점 만점), GPT-4o는 2.81점, Claude Sonnet 4는 2.18점을 부여했습니다. 점수 항목 전문가 동의율은 Gemini 87.1%, GPT 84.3%, Claude 37%로 극명하게 갈렸습니다.
이 차이를 연구팀은 각 모델의 설계 철학—멀티모달 통합 인식 vs. Constitutional AI 기반의 규칙 중심 평가—으로 설명합니다. 그런데 저는 여기서 한 발 더 들어가고 싶습니다. 이건 systematic bias입니다. Claude가 일관되게 낮은 점수를 준다면, 이는 모델이 특정 방향으로 calibration이 틀어져 있다는 신호입니다. 흥미로운 건, Claude의 개선 제안 동의율은 81.3%로 다른 두 모델과 비슷했다는 점입니다. 점수(output)는 틀렸지만 근거(reasoning)는 맞는 상황—이건 예측값과 설명 가능성이 서로 다른 방향으로 편향된 전형적인 케이스입니다.
실제 운영 환경에서 Claude 하나만 LLM-as-Judge로 쓴다면, 전체 데이터셋의 품질 분포가 실제보다 낮게 추정됩니다. 이건 단순한 모델 성격 차이가 아니라 평가 파이프라인 설계 오류입니다.
샘플 사이즈와 재현 가능성: 648개면 충분한가요?
648개의 평가 결과물은 12개 단원 × 9개 항목 × 3개 모델 × (점수+이유+제안)에서 나온 수치입니다. 단원 수 기준으로는 n=12입니다. 과학 분야별 분석(생명·물리·지구과학)으로 쪼개면 단원당 n은 더 작아집니다. SOTA 주장을 할 때 흔히 묻는 질문—"이 결과가 도메인 밖에서도 재현되나요?"—을 여기서도 던져야 합니다. 미국 NGSS 기반 고품질 커리큘럼 12개는 distribution이 매우 좁습니다. 일반 교사가 만든 수업 자료, 또는 다른 국가 교육과정에서도 같은 패턴이 나올지는 아직 알 수 없습니다.
AGENTS.md 실험: 컨텍스트 중복이 만드는 20% 비용 오버헤드
같은 맥락의 함정은 LLM 운영 비용 실험에서도 나타납니다. 긱뉴스(GeekNews)가 소개한 ETH Zurich 연구와 ICSE JAWs 2026 발표(Lulla et al.)에 따르면, AI 코딩 에이전트용 컨텍스트 파일(AGENTS.md)을 /init 명령으로 자동 생성하면 작업 성공률이 2~3% 하락하고 비용이 20% 이상 증가했습니다.
이 실험의 설계가 흥미롭습니다. GitHub PR 124개를 대상으로 AGENTS.md 유무만 바꾼 페어드 실험(paired experiment)—이건 confounding variable을 통제하는 올바른 방식입니다. 결론은 명확합니다. LLM이 자동 생성한 컨텍스트의 핵심 문제는 품질이 아니라 중복입니다. Claude Sonnet 4.5 출력의 100%, GPT 출력의 99%가 에이전트가 코드를 읽으면 스스로 발견할 수 있는 정보(디렉토리 구조, 기술 스택)를 포함했습니다. 이미 알고 있는 정보를 다시 주입하면 토큰만 소비되고 'Lost in the Middle' 효과(Liu et al., 2024)로 오히려 주의력이 분산됩니다.
Feature importance 관점에서 보면, 중복 feature는 모델 성능에 기여하지 않고 노이즈만 더합니다. 그리고 CI/CD 파이프라인에서 에이전트를 수천 회 실행한다면, 15~20% 비용 오버헤드는 복리로 누적됩니다. 베이스라인 대비 비용 증가를 명시적으로 측정하지 않으면 이 함정은 보이지 않습니다.
로컬 분류기 벤치마크: 합성 데이터의 함정
dev.to에 소개된 로컬 텍스트 분류기 프로젝트('expressible')는 다른 각도에서 평가 설계의 문제를 보여줍니다. all-MiniLM-L6-v2 임베딩 + 2-layer 신경망으로 50개 레이블 예플로 훈련, 230KB 모델로 오프라인 분류를 구현한 접근법입니다.
제가 벤치마크 테이블을 보고 바로 주목한 건 데이터 출처입니다. Support ticket routing 95.0%, Content moderation 90.0%, News categorization 88.0%—이 세 건은 모두 합성 데이터(Synthetic)입니다. 반면 실제 공개 데이터셋인 AG News에서는 64.0%로 급락합니다. 저자도 솔직하게 인정하고 있지만, 합성 데이터로 측정한 성능은 distribution shift에 취약합니다. 실제 운영 환경의 텍스트는 훈련 데이터와 도메인이 다를 수 있고, 그때 이 성능 수치는 의미를 잃습니다.
또한 sentiment 분류에서 44~50% 정확도—이건 랜덤 베이스라인(50%)과 거의 같습니다. 임베딩이 의미(what it's about)를 포착하지만 평가(how it evaluates)는 포착하지 못한다는 fundamental limitation을 ablation study 없이는 개선하기 어렵습니다.
시사점: LLM 평가 설계가 틀리면 모든 지표가 틀린다
세 실험을 관통하는 공통 메시지는 하나입니다. 평가 설계가 잘못되면 측정값 자체가 신뢰를 잃는다.
- 골든 레이블이 노이즈를 포함하면(코헨 카파 0.29), AI 채점의 동의율 69.6%는 과대평가될 수 있습니다.
- 평가 모델이 systematic bias를 가지면(Claude의 점수 동의율 37%), 단일 LLM-as-Judge는 데이터셋 전체를 왜곡합니다.
- 컨텍스트 중복이 측정되지 않으면, 운영 비용 20% 오버헤드는 아무도 모르는 채로 누적됩니다.
- 합성 데이터로 벤치마크를 구성하면, 실제 환경에서의 generalization 성능은 미지수입니다.
올바른 LLM 평가 파이프라인이라면 최소한 이것들을 명시해야 합니다: 평가자 간 일치도(Cohen's Kappa 또는 Krippendorff's Alpha), 베이스라인 대비 상대적 성능 향상, 평가 모델 자체의 편향 검사, 실제 도메인 데이터 비율, 샘플 사이즈와 통계적 유의성.
전망: 'AI 평가의 평가'가 다음 병목이 됩니다
AI 에이전트가 코드를 쓰고, AI가 수업을 채점하고, AI가 PR을 리뷰하는 세상에서—평가 파이프라인의 신뢰도가 전체 시스템의 신뢰도를 결정합니다. LLM-as-Judge 패턴이 확산될수록 평가자 자신의 calibration, bias, 비용 효율을 측정하는 메타 평가(meta-evaluation) 레이어가 필수가 됩니다.
ACE 프레임워크(ICLR 2026)가 정적 컨텍스트 파일 대신 동적 파이프라인으로 12.3% 성능 향상을 보인 것처럼, 평가 방법론도 정적 루브릭에서 동적·맥락 적응형 설계로 진화해야 합니다. 'AI가 교사보다 공정한 채점자가 될 수 있을까'라는 질문의 답은 아직 모릅니다. 하지만 분명한 건, 그 질문에 답하려면 먼저 평가 도구 자체를 엄밀하게 평가해야 한다는 것입니다.
숫자가 있다고 근거가 되는 건 아닙니다. 그 숫자가 어떻게 만들어졌는지가 더 중요합니다.