'작동한다'는 말과 '제대로 작동한다'는 말은 다릅니다
LLM 메모리 시스템을 구축할 때 가장 먼저 마주치는 함정은 '일단 돌아가면 된다'는 착각입니다. dev.to에 공개된 한 LLM 메모리 버그 추적 사례(BGE-M3 임베딩 교체 및 하이브리드 정규화)는 이 착각이 얼마나 조용히, 그리고 치명적으로 시스템을 망가뜨리는지를 보여줍니다. 문제는 세 가지였습니다: 데드락(deadlock), 키 불일치(key mismatch), 키 충돌(key collision). 그리고 흥미롭게도, 이 세 가지 모두 임베딩 모델 선택이라는 Feature Engineering 결정 하나에서 비롯되었습니다.
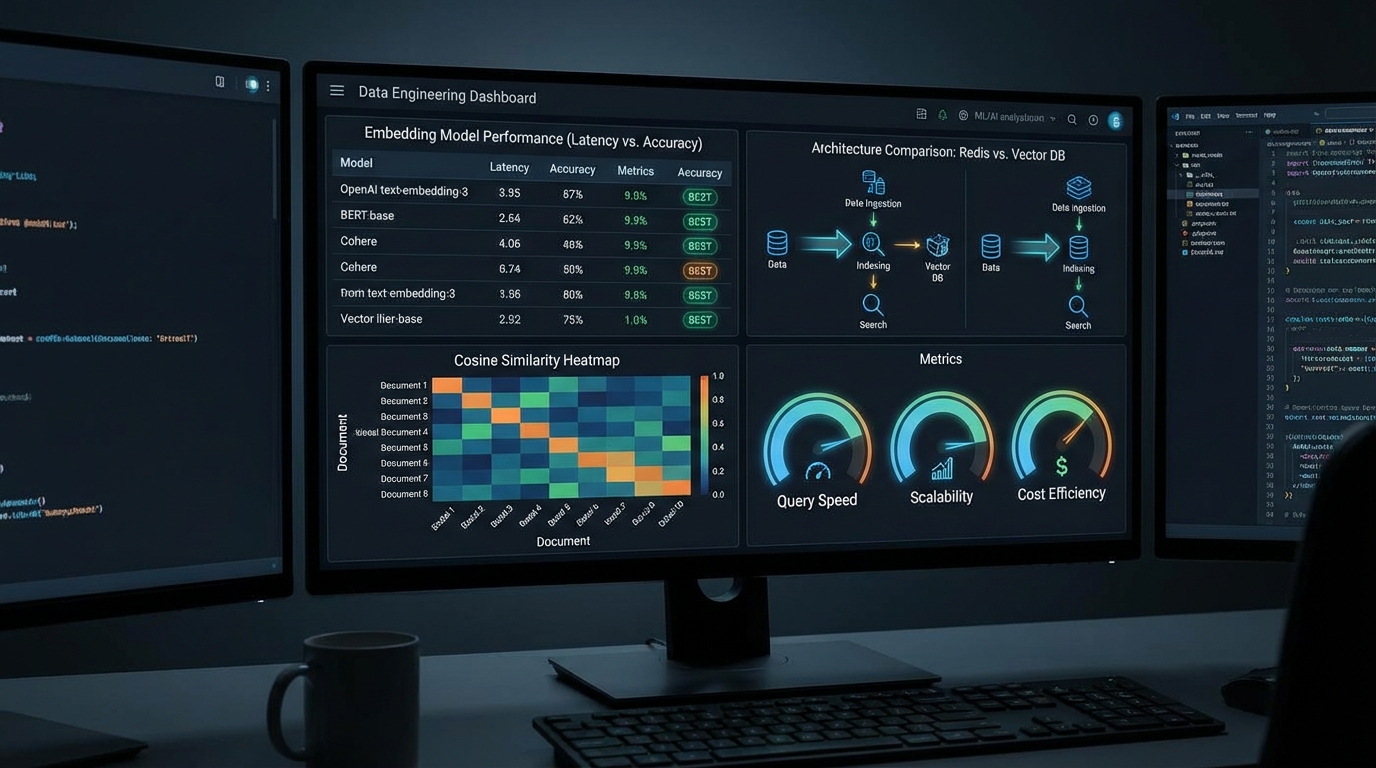
임베딩 모델 비교: 샘플 4개로 결론 내려도 될까요?
해당 사례에서 4개 임베딩 모델(all-minilm, nomic-embed, BGE-M3, Qwen3-Embed)을 비교한 핵심 실험 결과는 이렇습니다:
| 키 쌍 | all-minilm | nomic-embed | BGE-M3 | Qwen3-Embed |
|---|---|---|---|---|
| 취미 ↔ 혈액형 | 1.00 ❌ | 1.00 ❌ | 0.40 ✅ | 0.49 ✅ |
| 고양이 이름 ↔ 개 이름 | 1.00 ❌ | 1.00 ❌ | 0.87 ✅ | 0.91 ❌ |
all-minilm과 nomic-embed는 '취미'와 '혈액형'의 코사인 유사도를 1.0으로 판단했습니다. 의미적으로 전혀 다른 두 개념을 완전히 동일하다고 본 것입니다. 이건 모델 실패가 아니라, 짧은 한국어 키워드에 대한 분포 외 입력(out-of-distribution input) 문제일 가능성이 높습니다. 단, 솔직하게 짚어야 할 것이 있습니다. 이 실험의 테스트 케이스는 단 4~5쌍입니다. '샘플 사이즈가 충분한가요?' 이 질문을 먼저 던져야 합니다. BGE-M3가 더 낫다는 방향성은 타당하지만, 이 결과만으로 프로덕션 임베딩 모델을 교체하기엔 통계적 근거가 부족합니다. 최소한 수백 개의 실제 사용 키 쌍에 대한 Precision/Recall 측정이 필요합니다.
키 충돌 해결책: threshold 0.9는 어디서 나온 숫자인가요?
해당 시스템이 채택한 최종 접근법은 BGE-M3(cosine similarity threshold 0.9) + substring 폴백 하이브리드입니다. 동작 방식은 간단합니다:
- 새 키와 기존 키의 코사인 유사도 ≥ 0.9 → 동일 개념으로 판단, 기존 키에 덮어쓰기
- substring 포함 여부 + 길이 비율 ≥ 60% → 동일 개념으로 판단
그런데 threshold 0.9는 어디서 나온 숫자인가요? ablation study 결과는 어떤가요? 0.85로 낮추면 false positive(다른 개념인데 같다고 판단)가 얼마나 늘어나고, 0.95로 높이면 false negative(같은 개념인데 다르다고 판단)가 얼마나 늘어나는지에 대한 데이터가 없습니다. 10개 시나리오(MC01~MC10) 전부 통과했다는 결과는 인상적이지만, 이건 설계된 테스트 케이스에서의 성능입니다. 실제 운영 환경에서 사용자가 던지는 예측 불가능한 표현들에서도 이 성능이 나올까요? 데이터 드리프트 모니터링 없이는 알 수 없습니다.
Redis vs 벡터 DB: 비용-성능 trade-off의 현실
같은 맥락에서, dev.to의 또 다른 분석('Redis vs Vector Databases in the AI Era')은 인프라 선택의 실용적 프레임을 제공합니다. 핵심 수치를 비교하면:
- Redis: 레이턴시 ~0.1~1ms, 초당 100k+ 연산, 병목은 RAM
- 벡터 DB(Pinecone, Weaviate, Milvus, Qdrant 등): 레이턴시 5~50ms, ANN 설정에 따라 recall@K 조정 가능, 디스크 기반 스케일링
이 숫자들을 보면서 제가 던지는 첫 번째 질문은 '어떤 조건에서 측정한 벤치마크인가요?'입니다. Redis의 0.1ms는 캐시 히트 기준입니다. 캐시 미스 시 벡터 검색 + LLM 호출 전체 파이프라인 레이턴시는 전혀 다른 얘기가 됩니다. 해당 분석이 언급한 핵심 인사이트—'LLM 응답의 60~80%를 캐시하면 추론 비용이 극적으로 감소한다'—는 맞는 방향이지만, 이건 correlation이지 causation이 아닙니다. 캐시 히트율 60~80%가 나오는 워크로드는 질문 패턴이 매우 반복적인 경우에 한정됩니다. 사용자마다 맥락이 다른 개인화 메모리 시스템에서는 캐시 히트율이 훨씬 낮을 수 있습니다.
대규모 퍼지 매칭의 성능 병목: O(n²) 문제를 직시하기
Databricks 환경에서 1,000만 행 퍼지 매칭을 다룬 사례('Fuzzy-match millions of rows in Databricks, 2026')는 스케일 문제를 가장 솔직하게 드러냅니다. 나이브한 전수 비교는 n(n-1)/2 ≈ 5×10¹³ 쌍을 생성합니다. 이건 Spark로도 감당할 수 없는 규모입니다.
해당 사례가 채택한 해결책은 외부 Similarity API 오프로딩입니다. 1M 행을 약 7분에 처리했다고 언급하는데, 베이스라인 대비 얼마나 개선되었나요? LSH/MinHash 방식 대비 recall@K는 어떻게 비교되나요? 외부 API로 데이터를 전송한다는 것은 데이터 프라이버시와 거버넌스 리스크를 함께 수반합니다. 엔터프라이즈 환경에서는 네트워크 egress 정책, 데이터 레지던시 요구사항, 처리 후 데이터 삭제 보장이 모두 검증되어야 합니다. '작동한다'는 것과 '컴플라이언스를 만족한다'는 것은 다른 문제입니다.
자동 문서화 레이어: '70% 초안'의 품질을 어떻게 측정하나요?
Dremio의 자동 문서화 시맨틱 레이어 사례('How a Self-Documenting Semantic Layer Reduces Data Team Toil')는 조금 다른 각도의 데이터 품질 문제를 다룹니다. AI가 컬럼 설명을 자동 생성하고, 거버넌스 레이블을 제안하며, Bronze-Silver-Gold 뷰 체인을 따라 메타데이터를 전파한다는 개념입니다. 문서화 커버리지가 30%에서 80~90%로 향상된다고 주장합니다.
그런데 커버리지와 품질은 다릅니다. cltv 컬럼에 대해 AI가 생성한 설명이 'Customer Lifetime Value in USD'라고 정확히 나오는 사례는 이상적인 케이스입니다. 실제로는 컬럼명이 모호하거나 값 분포가 불규칙할 때 AI 생성 설명의 정확도가 급격히 떨어집니다. '70% 초안'의 오류율은 얼마인가요? 잘못된 설명이 퍼져나가는 메타데이터 드리프트는 없는 설명보다 더 위험할 수 있습니다.
시사점: 세 가지 공통된 패턴
이 세 사례를 관통하는 공통점이 있습니다.
첫째, 임베딩 모델은 Feature Engineering의 핵심 결정입니다. BGE-M3 교체가 키 충돌 문제를 해결한 것처럼, 잘못된 임베딩 모델 선택은 다운스트림 전체 파이프라인을 조용히 오염시킵니다. 모델 교체 전에 실제 프로덕션 키 패턴으로 구성된 평가 세트가 필요합니다.
둘째, 임계값(threshold)은 실험으로 결정해야 합니다. 0.9든 0.85든, 직관이 아니라 Precision-Recall 커브와 F1-score를 기반으로 설정해야 합니다. 특히 false positive(잘못된 덮어쓰기)와 false negative(중복 저장)의 비용이 비대칭적이라면 F-beta 메트릭 설계가 필요합니다.
셋째, 인프라 선택은 워크로드 특성에서 출발해야 합니다. Redis는 반복적인 쿼리 패턴에서 강력하고, 벡터 DB는 의미 검색 정확도가 중요할 때 강력합니다. 벤치마크 숫자보다 '내 워크로드의 쿼리 분포가 어떻게 생겼는가'를 먼저 분석해야 합니다.
전망: MLOps 없는 LLM 메모리 시스템은 시한폭탄
LLM 메모리 인프라는 앞으로 더 복잡해질 것입니다. 개인화 요구가 높아질수록 메모리 시스템의 키 공간은 폭발적으로 늘어나고, 임베딩 모델 업데이트마다 기존 벡터 인덱스를 재구축해야 하는 운영 부담이 생깁니다. 이건 전형적인 데이터 드리프트 + 모델 드리프트 문제입니다.
지금 당장 필요한 것은 화려한 SOTA 수치가 아닙니다. 키 충돌율 모니터링, 캐시 히트율 추적, recall@K 지표 대시보드, 임베딩 모델 버전 관리—이 네 가지가 없는 LLM 메모리 시스템은 언제 터질지 모르는 시한폭탄입니다. '10개 시나리오 모두 통과'는 좋은 시작점이지만, 프로덕션은 설계되지 않은 시나리오에서 항상 터집니다. 근거를 갖춘 인프라 설계, 지금이 시작할 때입니다.