프론트엔드 QA, 왜 아직도 이렇게 힘든가
솔직히 말하면, 프론트엔드 버그 수정 프로세스는 2024년이 지나도 여전히 비효율 덩어리입니다. 브라우저에서 padding이 2px 어긋난 걸 발견하면, 그걸 텍스트로 설명해서 → 티켓 만들고 → 개발자가 다시 재현하고 → 수정하는 흐름이 반복됩니다. "두 번째 카드의 세 번째 버튼, 텍스트가 잘려요"라고 설명하는 데 걸리는 시간이 실제 고치는 시간보다 길다는 게 말이 됩니까. 그런데 최근 이 흐름을 통째로 뒤바꾸려는 도구들이 나오기 시작했습니다. 단순한 생산성 도구가 아니라, 프론트엔드 품질 검증 자체를 자동화하는 워크플로우의 등장입니다.
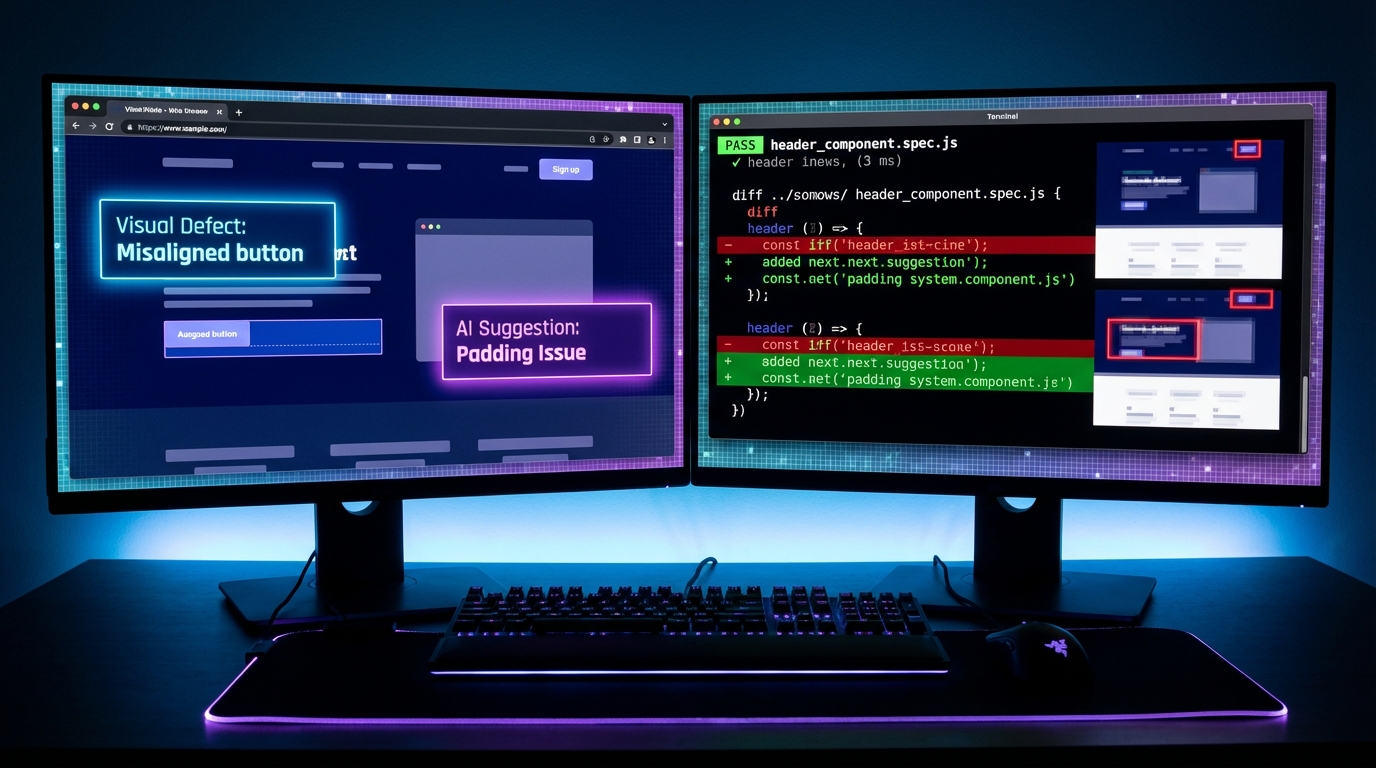
ui-ticket-mcp: "클릭이 곧 버그 리포트"가 되는 세계
dev.to에 공개된 ui-ticket-mcp는 MCP(Model Context Protocol) 서버를 활용해서 브라우저에서 보이는 것과 AI 에이전트가 코드에서 보는 것 사이의 간극을 메웁니다. 작동 방식은 단순합니다. <review-panel> 웹 컴포넌트를 앱에 추가하면 플로팅 패널이 생기고, 여기서 깨진 요소를 클릭해 "padding이 이상해요", "텍스트가 잘려요" 같은 코멘트를 달면 끝입니다.
이때 AI 에이전트에게 전달되는 컨텍스트가 핵심입니다. 단순히 스크린샷을 넘기는 게 아니라 CSS computed styles, DOM 구조, 유니크 CSS 셀렉터, bounding box, 접근성 정보, 형제 요소 컨텍스트까지 함께 전달됩니다. 에이전트는 get_pending_work()를 호출해 리뷰 목록을 가져오고, find_source_file로 소스를 찾아 직접 수정한 뒤 resolve_review로 완료 처리합니다. 사람이 개입하는 지점은 "어디가 이상한지 클릭하는 것" 뿐입니다.
Figma에서 볼 때는 괜찮았는데 실제 브라우저에서 구현하면 미묘하게 어긋나는 그 순간들, 다들 아시잖아요. 그 갭을 메우는 데 이 도구가 꽤 실용적입니다. React, Vue, Svelte, 일반 HTML 모두 지원하는 프레임워크 무관 웹 컴포넌트이고, 리뷰는 SQLite 파일로 저장돼 git에 커밋해 팀과 공유할 수 있습니다.
Playwright 시각적 회귀 테스트: "픽셀이 바뀌면 CI가 터진다"
버그를 사람이 발견해 신고하는 구조를 넘어서, 배포 전에 UI 변화를 자동으로 잡아내는 회귀 테스트 체계도 필요합니다. Playwright에 내장된 toHaveScreenshot()은 이론적으로 훌륭하지만, CI 환경에서는 현실이 다릅니다. macOS는 서브픽셀 안티앨리어싱을 쓰고 Linux 러너는 안 쓰고, 폰트 렌더링이 OS마다 달라서 같은 코드도 픽셀이 다르게 나옵니다. 결과는? 매번 flaky한 테스트.
dev.to에 소개된 접근법은 PageBolt 같은 호스팅 브라우저 API를 활용해 스크린샷을 일관된 환경에서 찍고, pixelmatch로 직접 diff를 계산하는 방식입니다. 베이스라인을 레포에 커밋해두고, PR마다 CI에서 동일한 Chromium 인스턴스로 찍은 스크린샷과 비교합니다. 픽셀 차이가 0.5% 넘으면 빌드 실패, diff 이미지는 아티팩트로 업로드돼 무엇이 바뀌었는지 즉시 확인할 수 있습니다.
특히 selector 파라미터로 특정 컴포넌트만 크롭해서 테스트하는 기능이 인상적입니다. 전체 페이지가 아니라 .pricing-card.pro만 격리해서 테스트하면, 무관한 레이아웃 변화에 테스트가 깨지는 노이즈를 줄일 수 있습니다. 디자인 시스템의 컴포넌트 단위 회귀 테스트에 딱 맞는 접근이에요.
접근성: 체크박스가 아니라 엔지니어링 품질의 문제
UI 품질을 이야기할 때 시각적 버그만 보는 건 절반짜리입니다. dev.to의 접근성 구현 가이드는 이 지점을 정확히 찌릅니다. alt 태그 달고 접근성 완료라고 생각하는 팀이 아직도 많은데, 모달 포커스 트래핑, 키보드 네비게이션, 스크린 리더 라이브 리전, prefers-reduced-motion 대응은 완전히 다른 레벨의 이야기입니다.
실제 코드 예시를 보면 디테일이 보입니다. 모달이 열릴 때 이전 포커스 위치를 저장해두고, 닫힐 때 정확히 그 요소로 포커스를 복원합니다. 이게 없으면 키보드 사용자는 모달 닫은 뒤 페이지 처음부터 탐색해야 합니다. WAI-ARIA tablist 패턴을 구현해서 방향키로 탭 전환이 가능하고, tabIndex={0}은 활성 탭에만 부여해 탭 오더를 깔끔하게 유지합니다.
prefers-reduced-motion에서 transition-duration: 0ms 대신 0.01ms를 쓰는 것도 눈여겨볼 만합니다. 완전히 0으로 설정하면 transitionend 이벤트가 발화하지 않아 JS 콜백이 깨질 수 있기 때문입니다. 이런 엣지 케이스까지 고려한 구현이 Lighthouse 접근성 점수 100점과 실제 사용성 사이의 차이를 만듭니다. focus-visible과 focus를 구분해서 마우스 사용자에게는 아웃라인을 숨기고 키보드 사용자에게만 명확한 인디케이터를 제공하는 것도 마찬가지입니다.
React Query staleTime: 네트워크 요청도 품질 지표다
UI가 아무리 완벽해도 데이터 페칭이 비효율적이면 체감 품질이 떨어집니다. dev.to의 React Query staleTime 가이드는 이 부분을 정리합니다. 기본값 staleTime: 0은 캐시된 데이터를 즉시 stale로 처리해서, 탭을 다시 포커스할 때마다 동일한 데이터를 재요청합니다. 북마크 목록을 1초 전에 불러왔는데 탭 전환 후 돌아오면 또 요청하는 식입니다.
staleTime: 1000 * 60 * 5로 5분을 주면, 그 사이에는 캐시에서 즉시 반환하고 백그라운드 재요청을 건너뜁니다. 사용자 입장에서는 로딩 없이 즉각 반응하는 앱으로 느껴지고, 서버 입장에서는 불필요한 API 호출이 줄어듭니다. staleTime(신선도)과 gcTime(캐시 생존 시간)의 차이를 명확히 이해하는 것도 중요합니다. 전자는 언제 다시 가져올지, 후자는 언제 메모리에서 지울지의 문제입니다. Core Web Vitals의 FID, INP 점수에 직결되는 최적화입니다.
시사점: 자동화가 감각을 대체할 수 있을까
네 가지 도구와 기법을 묶어 보면 하나의 흐름이 보입니다. 프론트엔드 품질 검증이 개인의 감각과 수작업에서 자동화된 파이프라인으로 이동하고 있다는 것입니다. AI 에이전트가 CSS를 직접 수정하고, CI가 픽셀 변화를 감지하고, 컴포넌트 아키텍처 안에 접근성이 내장되고, 캐시 전략이 체감 성능을 결정합니다.
다만 여기서 한 가지는 짚고 넘어가야 합니다. ui-ticket-mcp가 CSS 셀렉터와 computed style을 건네준다고 해서 AI가 항상 의도에 맞는 수정을 한다는 보장은 없습니다. 디자인 토큰 체계가 잡혀 있지 않은 프로젝트에서 AI가 하드코딩 값을 심어버리면, 수정 하나가 디자인 시스템 전체의 일관성을 깨뜨릴 수 있습니다. 시각적 회귀 테스트도 베이스라인 관리가 부실하면 의도한 디자인 변경마다 CI가 터지는 노이즈가 됩니다.
전망: 품질 자동화의 다음 단계
자동화 도구가 성숙할수록 프론트엔드 개발자의 역할은 버그를 직접 찾고 고치는 것에서 자동화 파이프라인을 설계하고 감독하는 것으로 이동할 겁니다. 어떤 요소를 회귀 테스트 대상으로 삼을지, AI 에이전트가 수정한 코드를 어떤 기준으로 검토할지, 접근성 자동 테스트가 잡지 못하는 엣지 케이스를 어떻게 커버할지—이런 판단은 여전히 사람의 영역입니다.
Design Token과 Figma Dev Mode가 디자인-개발 간 번역 비용을 낮추고, MCP 기반 에이전트가 반복적인 수정 작업을 흡수하고, Playwright 회귀 테스트가 배포 안전망이 되는 구조. 그 위에서 개발자는 1px 어긋난 padding을 직접 고치는 대신, 왜 그 padding이 어긋나는 구조적 원인을 분석하고 시스템으로 해결하는 데 집중할 수 있게 됩니다. 솔직히 그 미래, 빨리 오면 좋겠습니다.