배경: “컨텍스트 창”을 넘는 기억이 왜 어려운가
LLM이 대화나 업무 맥락을 오래 유지하려면 결국 ‘외부 메모리’가 필요합니다. 지금까지는 (1) 단순 대화 로그를 요약해 저장하거나 (2) 벡터DB에 문서를 넣고 RAG로 꺼내 쓰는 방식이 주류였죠. 하지만 이 둘은 관계(relationship)와 시간(temporal) 을 다루는 데 약합니다. “A가 B에서 일한다” 같은 사실도 시간이 지나면 바뀌고, 출처 신뢰도도 달라지는데, 일반 RAG는 ‘문서 조각’ 중심이라 변경 이력과 유효기간을 구조적으로 표현하기 어렵습니다.
GitHub의 gannonh/memento-mcp(Memento MCP)는 이 문제를 지식그래프(knowledge graph) + 벡터 검색(vector search) + 시간 인지(temporal awareness) 로 풀려는 접근입니다. 특히 MCP(Model Context Protocol)를 지원하는 클라이언트(원문에서 Claude Desktop, Cursor, GitHub Copilot 예시 언급)에 “메모리 서버”처럼 붙여서, LLM이 필요할 때 그래프를 조회하고 업데이트할 수 있게 설계합니다.
핵심 분석: Memento MCP가 제안하는 메모리 데이터 모델
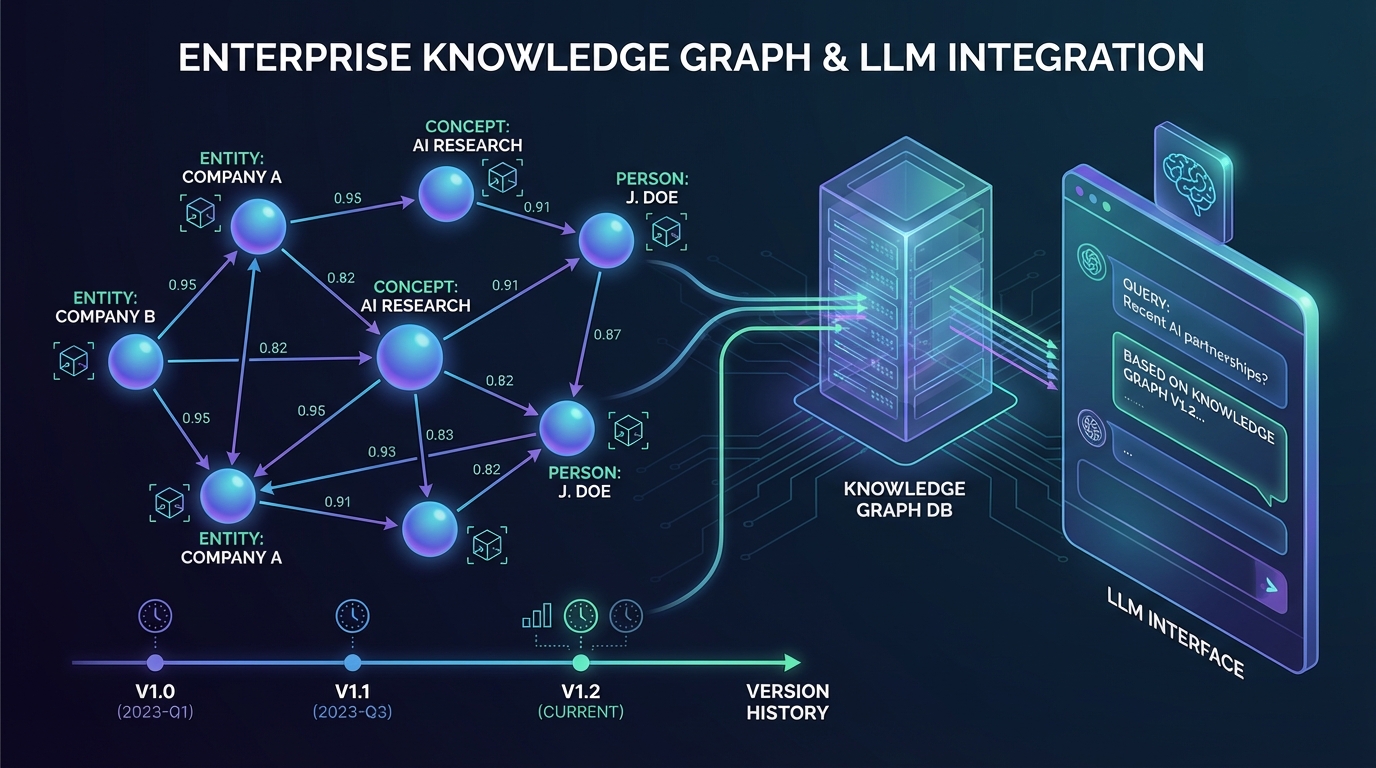
원문 설계의 중심은 Entity(엔티티) 와 Relation(관계) 입니다. 엔티티는 고유 이름(identifier)과 타입(person/org/event 등), 관찰(observations), 임베딩(semantic search용), 그리고 완전한 버전 히스토리(version history) 를 가집니다. 즉 “John_Smith는 스페인어 가능” 같은 사실이 단순 텍스트로만 저장되는 게 아니라, 엔티티에 누적 관찰로 남고, 변경이 있으면 덮어쓰기 대신 새 버전이 생깁니다. 관계는 방향성(from→to)과 타입(works_at 등)을 가지며, 흥미로운 점은 관계에 강도(strength 0~1), 신뢰도(confidence 0~1), 출처·태그·타임스탬프 같은 풍부한 메타데이터 를 기본 전제로 둔다는 겁니다. 더 중요한 건 관계도 버전 히스토리를 갖고, “최근 검증일(last_verified)” 같은 필드까지 포함해 시간에 따라 신뢰도가 감소(decay) 하도록 설계했다는 점입니다.
Neo4j 단일 백엔드: 그래프 저장과 벡터 검색을 한 DB에
Memento MCP는 저장소로 Neo4j 5.13+ 를 요구합니다(원문에서 벡터 검색 기능 때문이라고 명시). 전통적으로는 “그래프DB(관계 질의) + 벡터DB(유사도 검색)” 2개를 붙여 운영하는 경우가 많았는데, 이 프로젝트는 이를 단일 DB로 통합 하려는 선택을 했습니다. 여기서 얻는 효과는 꽤 실무적입니다.
- 아키텍처 단순화: 동기화 파이프라인(그래프↔벡터)과 장애 포인트가 줄어듭니다.
- 쿼리 일관성: “유사한 엔티티를 찾고 → 그 엔티티와 연결된 관계를 탐색” 같은 조합이 한 DB 안에서 끝나므로, 데이터 스냅샷/트랜잭션 관점에서 단순해집니다.
- 대규모 그래프에서의 성능/운영성: 원문은 대규모 지식그래프에서의 성능과 스케일을 장점으로 듭니다. 실무적으로는 인덱스/제약조건/벡터 인덱스 구성이 한곳에 모이니, 운영 플레이북이 단순해지는 효과가 큽니다.
다만 트레이드오프도 있습니다. Neo4j의 벡터 검색이 “전용 벡터DB”의 모든 튜닝/서빙 모델(예: 다양한 ANN 인덱스 전략, 초고성능 분산 서빙)을 완전히 대체하진 못할 수 있습니다. 팀의 요구가 ‘초대규모 벡터 서치’인지, ‘그래프+벡터의 결합 질의’가 핵심인지에 따라 선택이 갈립니다.
검색 전략: 의미 검색 + 키워드의 하이브리드, 그리고 적응형 선택
원문에서 Memento MCP는 엔티티를 임베딩으로 인코딩하고 코사인 유사도를 사용하며, 기본적으로 0.6 유사도 임계값 과 하이브리드 검색 활성화 를 “튜닝된 기본값”으로 제시합니다. 여기서 포인트는 두 가지입니다.
1) 하이브리드 검색(hybrid search): 의미 유사도만으로는 고유명사/정확 키워드 매칭에 약할 수 있고, 키워드만으로는 표현이 다른 유사 개념을 놓칩니다. 두 방식을 결합하면 회수율(recall)과 정밀도(precision) 균형을 잡기 쉽습니다.
2) 적응형 검색(adaptive search): 질의 특성과 데이터 상태(임베딩 존재 여부 등)에 따라 벡터-only/키워드-only/하이브리드를 고르는 전략을 언급합니다. 이건 사용자 경험에 직접 영향을 줍니다. “검색이 갑자기 텅 비는” 실패 모드가 줄어들기 때문입니다.
시간 인지 메모리: ‘그때는 맞고 지금은 틀리다’를 표현하는 방식
장기기억 시스템에서 가장 자주 터지는 문제는 과거 사실의 과잉확신 입니다. Memento MCP는 이를 두 갈래로 잡습니다.
- Point-in-time 그래프 조회: createdAt/updatedAt뿐 아니라 validFrom/validTo 같은 개념을 통해 “특정 시점의 그래프 상태”를 재구성할 수 있게 합니다. 즉, 동일한 질문이라도 “2024년 당시”와 “현재” 답이 다를 수 있다는 걸 시스템 레벨에서 허용합니다.
- 관계 신뢰도 감쇠(confidence decay): 기본 half-life를 30일로 두고, 강화(reinforcement)되면 신뢰도가 회복되는 형태를 제안합니다(원문). 이는 팀 지식이나 개인 프로필 같은 정보가 시간이 지나며 부정확해지는 현실을 반영합니다.
이 설계는 ‘정답률’뿐 아니라 안전성에도 기여합니다. 예를 들어 “A는 아직 그 회사에 재직 중” 같은 민감 정보가 자동으로 낮은 신뢰도로 내려가면, LLM이 단정적으로 말할 확률이 줄어들고, 사용자에게 “최근 검증 필요”를 유도할 수 있습니다.
비교/대조: 단순 RAG, 그래프RAG, 그리고 Memento MCP의 차별점
- 단순 RAG(문서→청크→벡터 검색) 대비: Memento MCP는 ‘문서 조각’이 아니라 엔티티/관계의 구조적 기억이 기본 단위입니다. 덕분에 “사람-조직-프로젝트-결정” 같은 연쇄 맥락을 그래프 탐색으로 뽑아내기 쉬워집니다.
- 일반적인 GraphRAG(그래프 + 별도 벡터DB) 대비: 이 프로젝트는 Neo4j의 벡터 기능을 활용해 단일 백엔드를 지향합니다. 운영 단순화가 강점이지만, 초대규모 벡터 서빙에서 전용 벡터DB만큼의 선택지를 제공하는지는 별도 검증이 필요합니다.
- “메모리 요약 저장” 방식 대비: 요약은 정보 손실이 구조적으로 발생합니다. Memento MCP는 비파괴 업데이트(버전 추가) 를 전제로 해서, 나중에 감사(audit)나 회고(“왜 이 답을 했지?”)에 유리합니다.
시사점: MCP + 지식그래프 메모리가 만드는 제품/팀 변화
원문이 강조하는 MCP 호환성은 단순 연결 편의가 아니라, 클라이언트 생태계에 메모리를 ‘플러그인’처럼 붙인다는 의미가 큽니다. Claude Desktop, Cursor 같은 툴을 쓰는 팀이라면, 개인별/프로젝트별 기억을 외부로 분리해 도구 교체 비용을 낮추는 방향으로도 설계할 수 있습니다.
또 하나는 팀 운영 관점입니다. “관계에 출처·검증일·신뢰도”가 들어가면, 기억은 더 이상 감(感)이 아니라 운영 가능한 데이터가 됩니다. 예를 들어 영업/채용/프로덕트 의사결정에서 “이 정보는 90일 전에 링크드인에서 왔고, 신뢰도 0.42로 떨어졌다” 같은 메타가 있으면, LLM이 ‘결정 지원 시스템’으로 한 단계 올라갈 수 있습니다.
실행 가이드: AI-First 팀에서 Memento MCP를 도입하는 현실적인 순서
1) 도입 목표를 “대화 저장”이 아니라 “결정/관계 기억”으로 정의하세요. 예: 고객사-담당자-니즈-마지막 확인일, 프로젝트-의사결정-근거-변경 이력.
2) Neo4j를 로컬로 빠르게 띄워 PoC: 원문은 Neo4j Desktop 또는 Docker Compose를 가이드합니다. Docker 기준으로는 볼륨 매핑(./neo4j-data:/data)으로 재시작/업그레이드에도 데이터가 유지된다고 명시되어 있어, PoC→파일럿 전환이 수월합니다.
3) 임베딩 차원/모델을 먼저 고정하고, 스키마 재초기화 전략을 마련: 원문에 npm run neo4j:init -- --dimensions 768처럼 차원 변경 옵션이 나옵니다. 운영에서 차원 변경은 재색인/재임베딩 비용을 유발하므로, “초기엔 small로 시작 → 성능 필요 시 large로” 같은 로드맵을 정하세요.
4) 신뢰도/감쇠 정책을 업무 도메인에 맞게 튜닝: half-life 30일은 범용값일 뿐입니다. 채용 후보 정보는 7~14일, 계정 플랜/가격 정책은 90~180일 등, 데이터 성격별로 decay 전략을 다르게 가져가야 ‘오답을 확신하는 모델’을 줄일 수 있습니다.
5) AI 코드리뷰/테스트에 메모리를 연결: AI-First 관점에서 가장 큰 ROI는 “개발자가 과거 결정을 다시 파헤치는 비용”을 줄이는 겁니다. PR 템플릿에 ‘관련 엔티티/관계 갱신’을 체크리스트로 넣고, LLM 리뷰어가 Memento MCP에서 “이 모듈의 과거 설계 의도/트레이드오프”를 자동 리콜하도록 붙이면, 리뷰 품질과 속도가 동시에 올라갑니다.
마무리: ‘기억’이 아니라 ‘검증 가능한 지식’으로의 전환
Memento MCP는 GitHub 원문 설명처럼 지식그래프·벡터 검색·시간 인지·감쇠를 한데 묶어, LLM의 장기기억을 “그럴듯한 요약”이 아니라 변경 이력과 신뢰도를 가진 지식 시스템으로 격상시키려는 시도입니다. MCP를 지원하는 클라이언트가 늘어날수록, 이런 메모리 레이어는 팀의 생산성을 끌어올리는 공통 인프라가 될 가능성이 큽니다.