베이스라인부터 다시 묻겠습니다: '정확도'가 뭘 측정하고 있나요?
모델 평가 회의에서 가장 많이 듣는 말이 있습니다. "AUC 0.92 나왔어요, 꽤 좋죠?" 그 순간 저는 반사적으로 묻습니다. "베이스라인 대비 얼마나 개선됐나요? 그리고 이 수치, 실제 운영 환경에서도 나올까요?"
dev.to에 게재된 임상 ML 실무 아티클과 Google Research가 arXiv에 공개한 논문 "Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality"—이 두 소스는 서로 다른 도메인을 다루고 있지만, 하나의 불편한 진실을 향해 수렴합니다. 모델은 충분히 '알고' 있을 수 있다. 그러나 그것이 올바른 작동을 보장하지는 않는다.
임상 ML의 5가지 데이터 함정: 지표가 감추는 것들
12년 약사 경력에서 공중보건 데이터사이언스로 전환한 실무자의 관찰은 통계적으로 흥미롭습니다. 그가 지목한 다섯 가지 함정은 모두 "모델이 학습 환경에서는 잘 작동했지만 실제 환경에서는 무너지는" 패턴을 공유합니다.
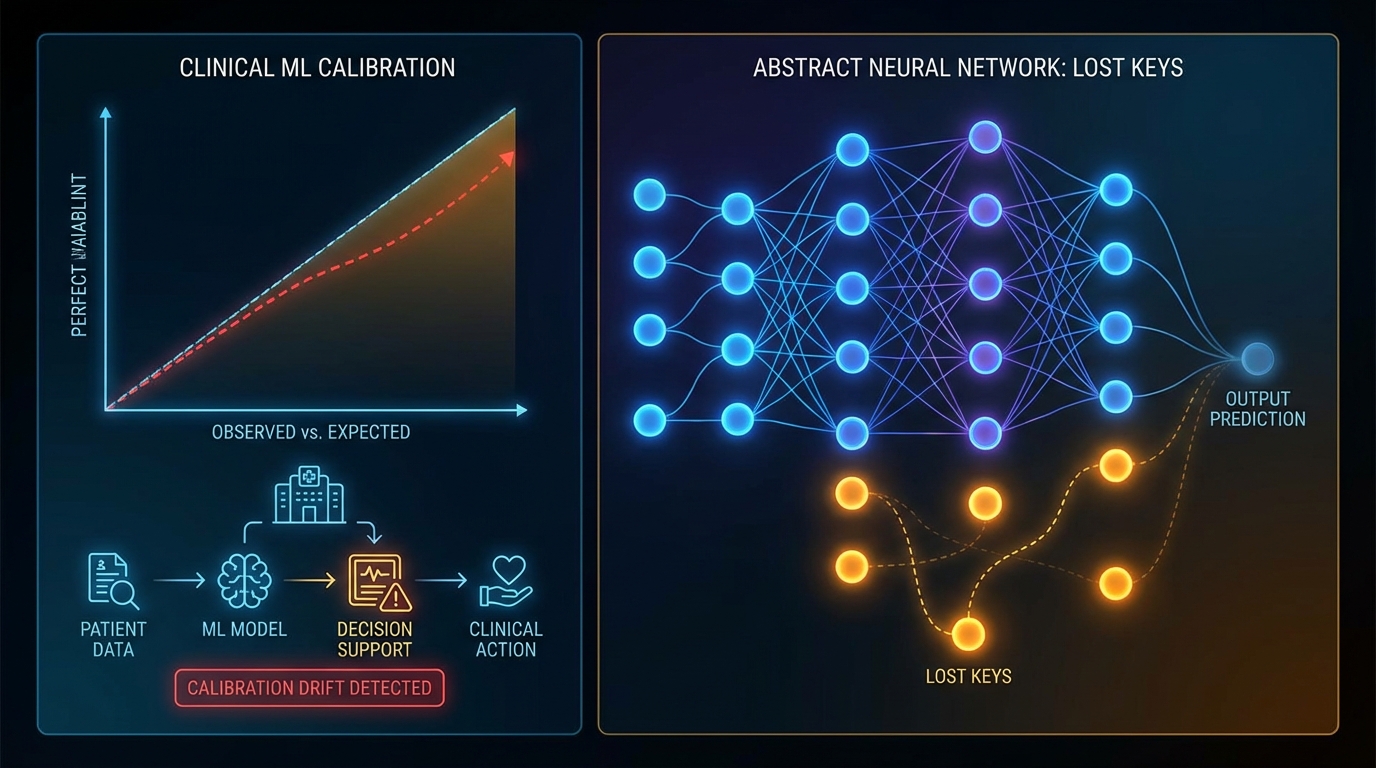
첫째, 시간적 누수(Temporal Leakage). 퇴원 기록으로 재입원을 예측하는 모델을 상상해보세요. 학습 데이터에 미래 정보가 섞이면 F1-score는 아름답게 올라가지만, 이건 correlation이지 causation이 아닙니다. 실제 예측 시점에 존재하지 않는 피처를 쓴 것이니까요. Strict event indexing 없이 나온 AUC는 숫자에 불과합니다.
둘째, 보정(Calibration) 무시. Discrimination(AUC, F1)은 모델의 랭킹 능력만 측정합니다. 보정은 "모델이 70%라고 했을 때 실제로 70%인가"를 측정합니다. 임상 의사결정에서 잘못 보정된 위험 추정치는 과잉치료 또는 과소치료로 직결됩니다. Calibration curve와 Platt Scaling, Isotonic Regression 같은 재보정 방법은 선택이 아니라 필수입니다.
셋째, 결측 데이터를 무작위로 취급하는 오류. 검사 결과가 없는 것이 단순 누락인지, 의사가 판단해서 검사를 안 한 것인지, 리소스 부족인지—이 셋은 데이터 분포 관점에서 완전히 다른 신호입니다. MCAR/MAR/MNAR 메커니즘을 분석하지 않고 mean imputation으로 때워버리면 편향(bias)이 조용히 모델에 스며듭니다.
넷째, 워크플로우 매핑 부재. 누가 예측 결과를 받는지, 어느 시점에 받는지, 그 다음 액션은 무엇인지, 책임 귀속은 어떻게 되는지—이 네 가지가 정의되지 않은 모델은 아무리 Recall이 높아도 학술 실험에 머뭅니다.
다섯째, 모니터링 계획 없음. 의료 시스템은 코딩 체계가 바뀌고, 환자 인구가 이동하고, 정책이 변합니다. 데이터 드리프트와 컨셉 드리프트를 감지할 파이프라인 없이 배포된 모델은 시간이 지날수록 성능이 어디로 가는지조차 파악할 수 없습니다.
GPT-5도 '알면서 틀린다': 저장과 회수는 다른 문제입니다
Google Research의 연구는 LLM 세계에서 동일한 질문을 다른 각도로 던집니다. GPT-5, Gemini-3-Pro 등 최첨단 모델 13개, 약 450만 건 응답 분석—샘플 사이즈만 보면 통계적 유의성은 충분합니다.
결과는 반직관적입니다. GPT-5와 Gemini-3-Pro는 테스트에 등장한 사실의 95~98%를 이미 파라미터에 저장하고 있었습니다. 냉장고는 거의 꽉 차 있었던 겁니다. 그런데도 추가 추론 없이 25~33%의 질문에서 틀렸고, GPT-5.2 기준 오류의 70% 이상이 '몰라서'가 아니라 '꺼내지 못해서' 발생했습니다.
연구팀은 이를 "Empty Shelves(빈 선반)" 대 "Lost Keys(잃어버린 열쇠)"로 구분합니다. 기존 평가 프레임워크는 맞으면 1점, 틀리면 0점이었습니다. 이 방식으로는 왜 틀렸는지—인코딩 실패인지, 출력 실패인지—를 구분할 수 없습니다. 연구팀이 새로 설계한 WikiProfile 벤치마크는 이 두 가지를 분리 측정합니다. 두 AI 채점자 간 98.2% 일치율은 라벨링 품질 관점에서도 신뢰할 만합니다.
특히 흥미로운 건 방향성 비대칭 문제입니다. "오아시스 밴드가 처음 공연한 장소는?"에 82.9% 정답률을 보인 GPT-5가 "보드워크 클럽에서 처음 공연한 밴드는?"으로 질문 방향만 바꾸면 74%로 떨어집니다. 그런데 보기를 주고 고르게 하면 역방향도 정방향만큼 맞힙니다. 알고는 있는데 스스로 꺼내지 못하는 것—이건 모델 크기의 문제가 아닙니다. 스케일업으로는 이 격차가 해소되지 않았다는 점도 함께 확인됐습니다.
'Thinking'은 성능 향상인가, Latency-Accuracy Trade-off인가
연구에 따르면 Chain-of-Thought 방식의 '싱킹(thinking)'은 "저장은 됐지만 바로 꺼내지 못했던" 사실의 40~65%를 추가로 회수합니다. 반면 애초에 저장되지 않은 정보에는 5~20%밖에 효과가 없습니다. Ablation study 관점에서 보면 싱킹의 기여는 "없는 지식 생성"이 아니라 "있는 지식의 회수율 개선"으로 명확히 한정됩니다.
그러나 이건 공짜가 아닙니다. 추가 연산 비용과 latency 증가는 프로덕션 환경에서 throughput과 직접 충돌합니다. 더 중요한 문제는 모델이 스스로 "지금 싱킹이 필요한 순간"을 판단하는 메타인지 능력이 아직 불완전하다는 점입니다. 이건 적응형 추론 전략을 MLOps 파이프라인 수준에서 설계해야 한다는 뜻이기도 합니다.
시사점: 프로덕션 신뢰성은 지표가 아니라 설계에서 나옵니다
두 연구가 수렴하는 지점은 명확합니다. "모델이 정보를 보유하고 있다"는 것과 "모델이 올바르게 작동한다"는 것은 별개의 문제입니다.
임상 ML에서는 시간 축을 존중하지 않은 피처 엔지니어링, 보정되지 않은 확률 추정, 드리프트 감지 없는 배포가 정확도 수치 뒤에 숨어 있습니다. LLM에서는 파라미터에 저장된 지식과 실제 출력 사이의 회수 실패가 신뢰성을 갉아먹습니다.
프로덕션 ML 신뢰성 설계를 위한 체크리스트를 정리하면 이렇습니다:
- 데이터 파이프라인 단계: Temporal leakage 감사, 결측 메커니즘(MCAR/MAR/MNAR) 분석, 분포 시각화
- 모델 평가 단계: AUC/F1 외 Calibration curve 필수, 서브그룹별 성능 분석으로 숨은 편향 탐지
- 배포 전 단계: 워크플로우 매핑—누가, 언제, 어떤 액션을, 어떤 책임 구조 아래 사용하는가
- 운영 단계: 데이터 드리프트 모니터링, 재학습 트리거 조건 명시, 모델 버전 관리
- LLM 특화: 단순 정답률이 아닌 인코딩 실패 vs 출력 실패 분리 측정, thinking 토글의 비용-성능 분기 설계
전망: 평가 프레임워크 자체가 진화해야 합니다
WikiProfile이 기존 벤치마크의 "맞/틀림" 이분법을 넘어 저장과 회수를 분리했듯, 임상 ML의 평가 기준도 AUC 단일 지표 중심에서 벗어나야 합니다. 공정성(Fairness), 보정(Calibration), 워크플로우 통합성, 드리프트 내성—이 모든 차원을 포괄하는 다차원 평가 프레임워크가 표준이 되어야 합니다.
"이 모델은 해석 가능한가?" "실제 운영 환경에서도 이 성능이 나오는가?" "샘플 분포가 배포 환경과 일치하는가?"—이 질문들이 리뷰 프로세스에 구조적으로 포함될 때, 우리는 비로소 정확도 너머의 신뢰성을 논할 수 있습니다.
모델이 안다고 해서 옳게 작동하는 건 아닙니다. 그리고 이건 LLM만의 문제가 아닙니다.