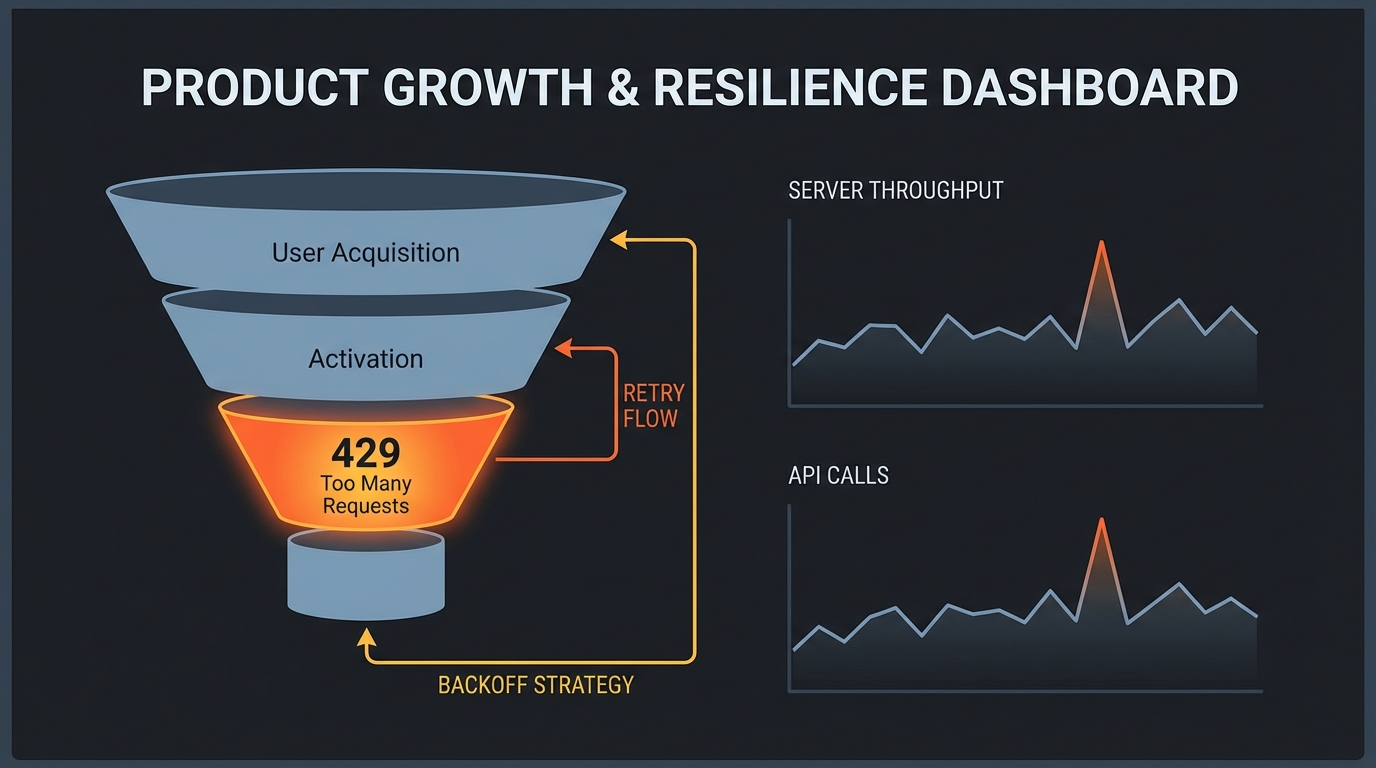
LLM/에이전트 제품에서 유저가 떠나는 순간은 대개 “모델이 멍청해서”가 아닙니다. 피크 타임에 429(Too Many Requests) 터지고, 응답은 느려지고, 재시도는 없거나 UX가 ‘무한 로딩’이면… 그 즉시 퍼널이 무너져요. 벤치마크 1등 모델도 운영 제약(처리량/레이트리밋) 앞에선 그냥 에러 머신이 됩니다. (dev.to의 rate limit/throughput 가이드가 딱 이 지점을 짚습니다.)
맥락을 성장 관점으로 번역해보면 간단합니다. AI 기능은 보통 “첫 사용 경험”에 붙어 있고, 이 구간은 AARRR에서 Activation과 Retention을 동시에 건드립니다. 여기서 실패하면 재방문 이전에 이미 이탈이라 CAC가 그대로 증발해요. 즉, 레이트리밋·처리량은 인프라 지표가 아니라 ‘전환율 지표의 선행변수’입니다. 이거 바이럴 될 것 같은 기능(공유/추천)도, 핵심 기능이 피크에서 죽으면 공유가 안 일어나죠.
dev.to 글이 강조한 포인트는 두 가지예요. 첫째, 처리량(throughput)은 “한 요청이 얼마나 빠르냐(지연시간)”가 아니라 “동시에 얼마나 버티냐(용량)”입니다. TPS(tokens per second)나 분당 토큰/요청 제한에 걸리면, 유저 수가 늘수록 응답이 나빠지고 결국 실패율이 올라갑니다. 둘째, rate limit과 throttling은 다릅니다. rate limit은 ‘하드 캡’이라 예측 가능하지만, throttling은 부하에 따라 ‘서서히 느려짐’이라 더 적응형 로직이 필요합니다.
여기서 “와 이거다!” 싶은 실전 레버는 실패 복구(리트라이) 설계입니다. dev.to의 에이전트 보일러플레이트 글은 429/5xx에 대해 exponential backoff + jitter로 재시도하고, 4xx(400/401/403)는 즉시 실패시키는 패턴을 제시하죠. 이 패턴을 단순 기술 부채가 아니라 ‘이탈 방지 장치’로 보면 됩니다. 유저 입장에서는 “에러”가 아니라 “잠깐 지연 후 정상 처리”로 인지되면 신뢰가 쌓이고, 신뢰는 곧 유료 전환의 바닥을 만듭니다.
시사점은 명확합니다. AI 제품의 퍼널을 깎아먹는 대표적인 friction point는 3가지예요: ① 피크 타임 실패(429) ② 느린 응답(낮은 처리량/동시성 한계) ③ 실패 후 복구 부재(리트라이/재개 불가). 이 세 가지를 줄이면 Activation→핵심가치 도달 시간이 짧아지고, “한 번 더 써볼까?”가 “계속 쓰네”로 바뀝니다. Conversion rate가 얼마나 오를까요? 제품마다 다르지만, 최소한 ‘에러로 끝나는 세션 비율’이 내려가는 만큼 상단 퍼널 누수가 줄어드는 건 확실합니다.
바로 테스트 가능한 실험 아이디어로 쪼개보면 더 선명해요. (1) 레이트리밋 가시화: 429 발생 시 사용자에게 “재시도 중(예상 3~5초)”을 명확히 보여주고, retry-after를 UI/로직에 반영. (2) 큐잉 + 비동기 전환: 대기 시간이 길어지면 즉시 결과를 기다리게 하지 말고 “완료되면 알림/메일/인앱”으로 전환해 세션 이탈을 막기. (3) 동시성 제어: 에이전트의 멀티툴 호출/병렬 실행은 좋지만, concurrent limit을 먼저 때립니다. 내부적으로 세마포어/버킷으로 동시 요청을 제한해 ‘폭발’ 대신 ‘안정적 처리’로.
또 하나의 힌트는 워크플로우 재시도 철학입니다. dev.to의 DolphinScheduler 사례는 실패를 “폐기”가 아니라 “지연 후 재배송”으로 설계하고, 상태 머신으로 재시도 횟수·간격을 통제합니다. 이 사고방식은 에이전트에도 그대로 적용돼요. 예를 들어 “툴 실행 실패→다시 시도→그래도 실패면 다른 경로 제안”을 상태로 관리하면, 유저는 실패를 ‘막힘’이 아니라 ‘진행’으로 느낍니다.
전망: 앞으로 LLM 제품 경쟁은 ‘모델 선택’보다 ‘운영 설계’에서 더 자주 갈릴 겁니다. 모델은 상향 평준화되지만, 레이트리밋/처리량/쿼터 구조는 공급자마다 다르고(티어·사용 이력·프로젝트 쿼터), 그 차이가 곧 제품의 성장 상한선을 결정하거든요. 결론은 하나: 벤치마크 올리기 전에, 피크 트래픽에서 “실패하지 않는 경험”을 먼저 만드세요. 빨리 테스트해봐야 돼요. 이건 인프라 최적화가 아니라, 전환율·리텐션을 직접 올리는 성장 실험입니다.