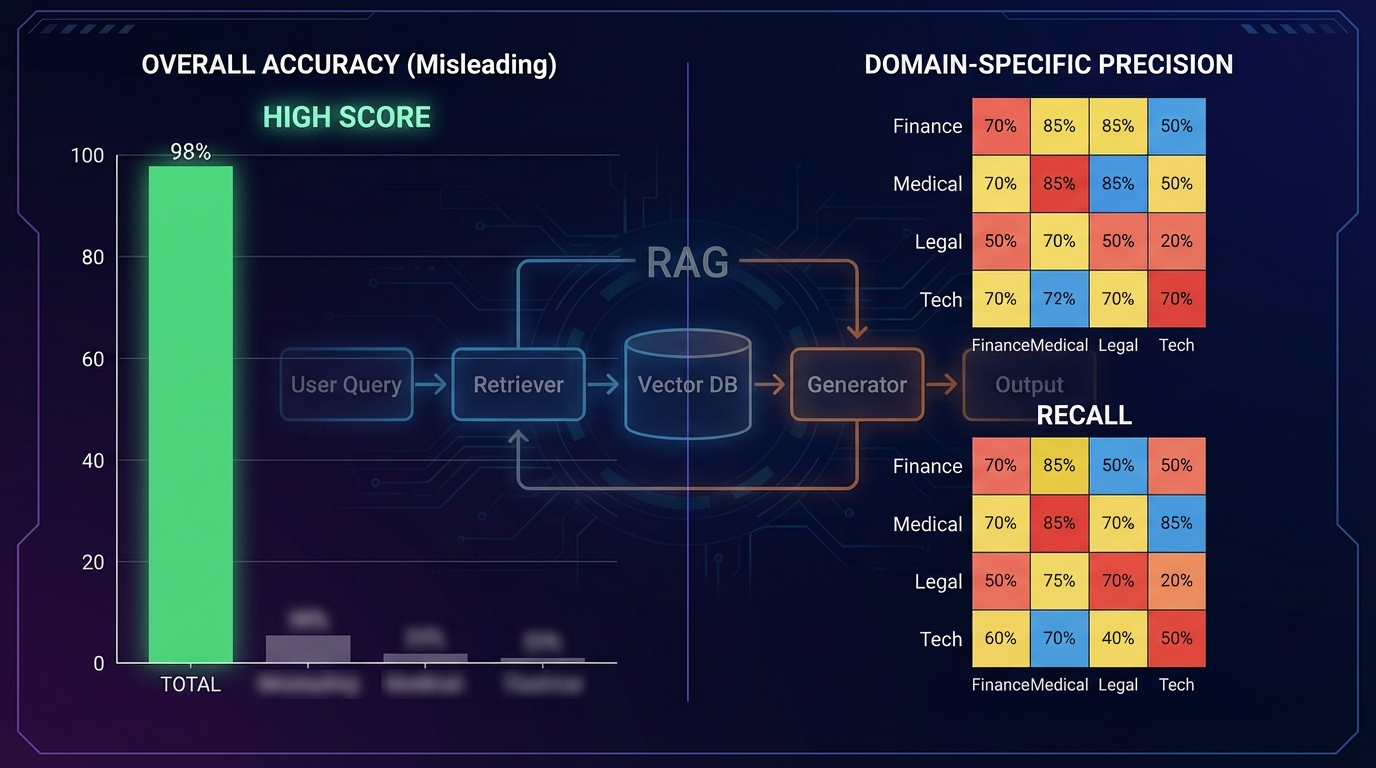
'94% 정확도'라는 숫자, 근거는 있나요?
어떤 RAG 시스템이 '정확도 94%'를 달성했다는 발표를 보면 저는 반사적으로 한 가지를 묻습니다. 그 94%가 어떤 데이터셋에서 측정된 것인가요? dev.to에 공개된 AI 코드 리뷰 도구 평가 분석은 이 질문이 얼마나 중요한지를 날카롭게 보여줍니다. 전체 정확도 95%를 자랑하는 도구가 특정 언어나 프레임워크에서는 취약점의 절반을 놓칠 수 있다는 것, 이건 RAG 시스템에도 그대로 적용되는 이야기입니다.
청킹: 당신의 RAG가 '평균의 함정'에 빠진 이유
RAG를 처음 구현해본 개발자들이 공통으로 마주치는 첫 번째 실패 지점은 청킹(Chunking) 입니다. 60페이지 PDF를 통째로 벡터 DB에 넣으면 어떻게 될까요? 그 벡터는 문서 전체 주제의 평균이 됩니다. 통계적으로 말하자면, 분산이 극도로 높은 데이터를 단일 임베딩으로 압축한 셈입니다—정보 손실이 필연적으로 발생합니다.
dev.to의 RAG 구현 실습 사례에 따르면, 500단어 단위로 청킹하되 50단어의 오버랩을 두는 방식이 실질적으로 검색 품질을 개선합니다. 오버랩 없이 청킹하면 "치료 효과 95% 유효" 같은 핵심 문장이 두 청크의 경계에 걸쳐 잘려, 어느 쪽 청크도 완전한 맥락을 갖지 못하는 상황이 발생합니다. 이건 단순한 구현 디테일이 아닙니다—Recall을 구조적으로 낮추는 설계 결함입니다.
여기서 중요한 질문: 당신의 RAG 평가 지표는 청크 경계에서 잘린 답변을 놓친 경우를 얼마나 포착하고 있나요?
GraphRAG vs 전통 RAG: 73% 개선이라는 숫자의 맥락
AWS dev.to 블로그에서 공개된 GraphRAG 비교 실험은 흥미로운 수치를 제시합니다. RAG-KG-IL(2025) 논문에 따르면, RAG 단독 시스템은 49건의 허구 진술(hallucination)을 생성한 반면 지식 그래프를 통합한 시스템은 35건으로 줄었다—73% 감소라고 표현됩니다.
잠깐, 이 수치를 그대로 받아들이기 전에 몇 가지를 체크해야 합니다.
- 샘플 사이즈가 충분한가요? 300개 호텔 FAQ 문서라는 특정 도메인에서 측정된 결과입니다
- 테스트 케이스 구성은 어떻게 되나요? 집계(aggregation) 쿼리에 특화된 4가지 테스트는 GraphRAG가 유리한 케이스를 선택적으로 테스트한 것일 수 있습니다
- 이건 correlation이지 causation이 아닙니다: 지식 그래프 통합이 환각을 줄인 것인지, 아니면 구조화된 쿼리(Cypher) 방식 자체의 효과인지 ablation study가 필요합니다
실험 자체는 설득력 있습니다. GraphRAG가 "평균 투숙객 평점은?" 같은 집계 쿼리에서 전통 RAG보다 실질적으로 우수하다는 직관은 타당합니다. 벡터 유사도 검색은 상위-k 문서만 보기 때문에 전체 데이터셋에 대한 AVG() 계산이 구조적으로 불가능하기 때문입니다. 하지만 이 결과가 여러분의 도메인에 그대로 일반화되는지는 별개의 문제입니다.
메모리 아키텍처의 레이어별 정밀도: Elasticsearch의 주장 검토
Elasticsearch를 AI 에이전트의 메모리 레이어로 활용하는 아키텍처를 소개한 dev.to 글은 흥미로운 성능 수치를 언급합니다. BBQ(Better Binary Quantization)가 float32 벡터 대비 95% 메모리 감소를 달성하면서도 랭킹 품질을 보존한다는 것, DiskBBQ 알고리즘이 100MB 메모리로 ~15ms 쿼리 레이턴시를 유지한다는 주장입니다.
이 수치들에 대해 물어야 할 것들:
- 15ms 레이턴시는 어떤 인덱스 크기 기준인가요? 페타바이트 규모라고 했지만, 실제 벡터 수와 차원(dimension)이 명시되지 않았습니다
- 랭킹 품질 보존의 기준은 무엇인가요? NDCG@10? MRR? 구체적인 지표 없이 '보존'이라는 표현은 마케팅 언어에 가깝습니다
- 프로덕션 환경에서도 이 성능이 나올까요? 동시 요청(concurrent request) 상황, 인덱스 업데이트가 진행되는 동안의 레이턴시는 별도 측정이 필요합니다
그럼에도 에피소딕-시맨틱-절차적 메모리로 나누는 3레이어 아키텍처는 개념적으로 탄탄합니다. 특히 도메인 밀도 스코어링(domain density scoring) 으로 에이전트가 근거가 부족할 때 스스로 답변을 거부하게 만드는 패턴—이건 false negative를 줄이는 실용적인 접근입니다.
집계 점수가 숨기는 것: 도메인별 F1의 중요성
네 개의 소스 기사를 관통하는 핵심 문제는 하나입니다. 전체(overall) 정확도 점수는 도메인별 실패를 숨깁니다.
AI 코드 리뷰 도구 분석 기사가 제시한 표를 보면:
| 도메인 | AI 성능 |
|---|---|
| 범용 언어(Python, JavaScript) | 높은 커버리지 |
| 프레임워크 특화 취약점 | 불일치 |
| 인증/인가 로직 | 종종 누락 |
| 내부 독점 라이브러리 | 최소 커버리지 |
RAG 시스템에 이 테이블을 그대로 적용할 수 있습니다. 범용 FAQ나 일반적인 지식 검색에서는 전통 RAG가 충분히 작동합니다. 그러나 집계 쿼리, 관계형 추론, 수치 계산이 필요한 도메인에서는 벡터 유사도 기반 검색이 구조적 한계를 드러냅니다. 이 한계가 전체 정확도 점수에는 잘 드러나지 않습니다—다른 쿼리 유형에서의 높은 성능이 평균을 끌어올리기 때문입니다.
Precision과 Recall을 도메인별, 쿼리 유형별로 분해해서 보는 것—이게 RAG 시스템 평가에서 반드시 요구해야 할 첫 번째 조건입니다.
실무자를 위한 RAG 평가 체크리스트
이 모든 논의를 정리하면, RAG 성능 수치를 접할 때 던져야 할 질문 목록이 나옵니다:
데이터 측면 - 청크 크기와 오버랩 설정이 공개되어 있나요? - 테스트셋이 실제 프로덕션 쿼리 분포를 반영하나요? - 도메인별 쿼리 유형(factual vs aggregation vs relational)이 균형 있게 포함되나요?
지표 측면 - Precision/Recall이 쿼리 유형별로 분해되어 있나요? - False negative rate—특히 고위험 도메인에서—를 제시하나요? - Hallucination을 어떻게 정의하고 측정했나요?
일반화 측면 - 벤치마크 데이터셋과 실제 코드베이스/문서의 분포 차이는? - 임베딩 모델이 교체되었을 때 성능 변화(ablation)는? - 프로덕션 트래픽에서의 레이턴시-정확도 trade-off는?
전망: '측정 가능한 RAG'를 향해
RAG는 이제 실험 단계를 넘어 프로덕션 배포가 일상화된 기술입니다. 그런데 아이러니하게도 평가 방법론은 아직 성숙하지 못했습니다. GraphRAG는 집계·관계형 쿼리에서 명확한 우위를 보이지만 구축 비용과 쿼리 복잡도가 높습니다. 전통 RAG는 시맨틱 검색에서 충분히 실용적이지만 한계 쿼리 유형을 정직하게 공개해야 합니다.
앞으로 필요한 것은 "우리 RAG가 95% 정확도" 같은 마케팅 수치가 아니라, 쿼리 유형별 성능 분포, 도메인 커버리지 맵, 그리고 실패 케이스의 체계적 분류입니다. RAGAS, TruLens 같은 RAG 특화 평가 프레임워크가 이 방향으로 발전하고 있지만, 결국 가장 중요한 것은 여러분의 실제 유스케이스로 직접 측정하는 것입니다.
벤치마크 점수는 참고 자료일 뿐입니다. 여러분의 문서, 여러분의 쿼리, 여러분의 사용자로 측정한 Recall이 유일하게 믿을 수 있는 숫자입니다.