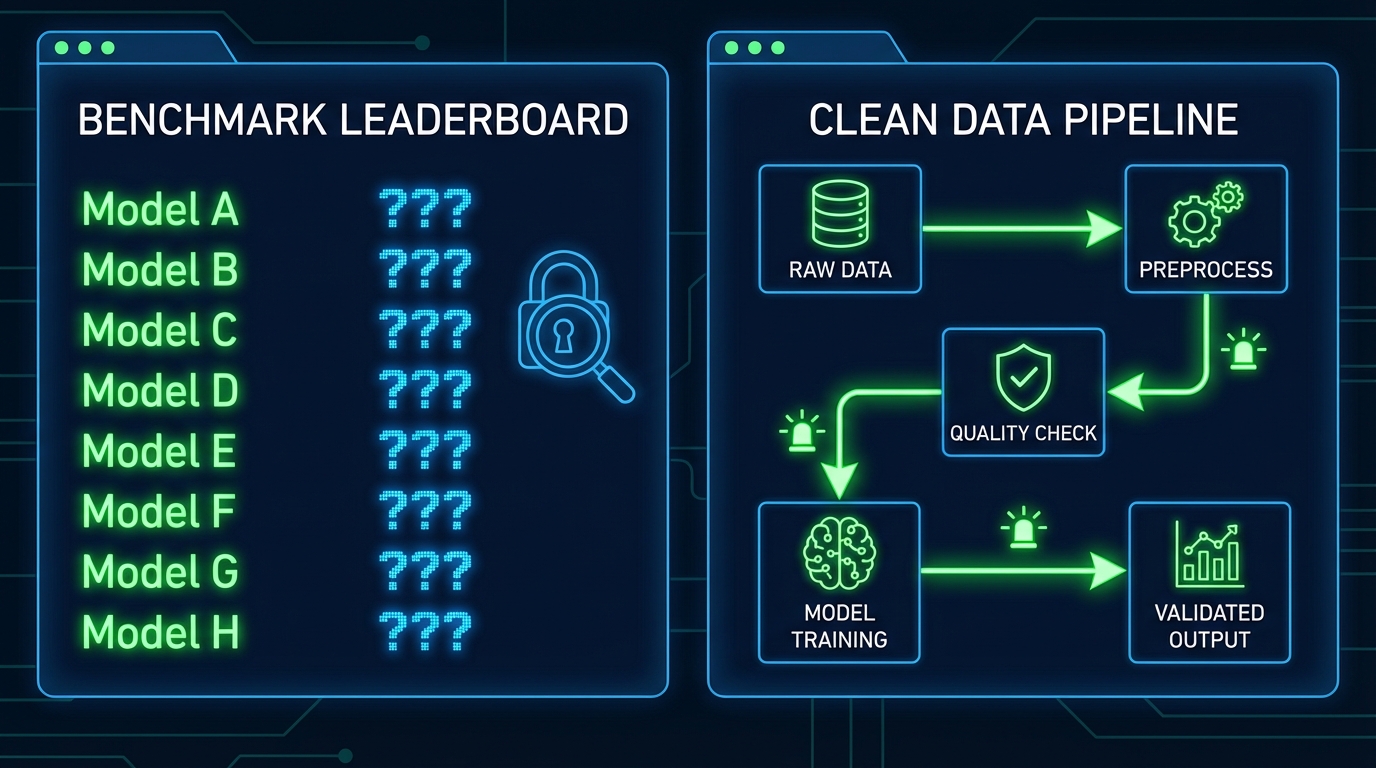
'76.9점'이라는 숫자, 얼마나 믿을 수 있나?
Alibaba가 공개한 Qwen3.5-122B-A10B가 MMMU-Pro 시각 추론 벤치마크에서 76.9점을 기록하며 Claude Sonnet 4.5를 앞질렀다는 소식이 이번 주 ML 커뮤니티를 달궜습니다(출처: dev.to). BFCL-V4 툴 사용 벤치마크에서는 72.2점으로 GPT-5 mini(55.5점) 대비 30% 마진을 주장했고, AIME 2026 수학 추론에서는 85%를 찍었습니다. 소비자용 GPU인 RTX 5080 16GB에서 62.98 tokens/sec, 200K 컨텍스트 윈도우라는 숫자까지 붙었으니 충분히 자극적입니다.
하지만 여기서 잠깐. 샘플 사이즈는 충분했나요? 평가 데이터셋은 모델 사전학습 데이터와 겹치지 않았나요? MMMU-Pro 하나의 점수로 '프론티어 모델 능가'를 선언하는 건 precision이 높고 recall이 낮은 리포트를 '정확도 100%'라고 부르는 것과 다르지 않습니다. 오픈소스 LLM 벤치마크 발표에는 구조적으로 두 가지 편향이 따라붙습니다. 첫째, 데이터 오염(data contamination): 벤치마크 문항이 사전학습 코퍼스에 포함됐을 가능성. 둘째, 선택적 보고(selective reporting): 잘 나온 태스크만 전면에 내세우는 cherry-picking. Ablation study 결과는 공개됐나요? 재현 가능한 코드와 평가 스크립트는 있나요?
MoE 아키텍처가 주는 진짜 시사점
그렇다고 Qwen3.5의 기술적 선택이 무의미하다는 뜻은 아닙니다. 122B 총 파라미터 중 forward pass당 10B만 활성화하는 Mixture-of-Experts(MoE) 설계는 inference latency와 메모리 사용량 사이의 trade-off를 실질적으로 이동시킵니다. 소비자 GPU에서 63 tokens/sec는 인터랙티브 코딩 워크플로우에 충분한 throughput이고, 이는 closed-model API 호출 비용과 self-hosting 비용의 손익분기점을 명백히 앞당깁니다.
핵심은 이것입니다. 이 모델을 내 프로덕션 환경에 올렸을 때 벤치마크 성능이 재현되느냐는 별개의 질문입니다. 분포 이동(distribution shift)이 발생하는 실 운영 데이터, 다국어 혼합 입력, 엣지 케이스 비율—이 조건들이 달라지면 MMMU-Pro 76.9점은 그냥 숫자가 됩니다. 성능 향상의 절대값보다 베이스라인 대비 상대적 개선과 테스트 조건의 일반화 범위를 먼저 확인하는 것이 ML 분석가의 첫 번째 습관이어야 합니다.
데이터 파이프라인: OOM 크래시가 알려주는 것
벤치마크 논쟁과 별개로, 이번 주 TensorFlow.js 커뮤니티에서는 훨씬 실용적인 문제가 다뤄졌습니다(출처: dev.to). 100개 이미지로 시작한 CNN 학습 프로젝트가 1,000개, 10GB 규모로 확장되면서 마주치는 OOM(Out of Memory) 크래시—이 시나리오는 ML 파이프라인 설계의 가장 고전적인 실패 패턴입니다.
해법으로 제시된 것은 JavaScript Generator(function*)를 활용한 Out-of-Core Learning입니다. Lazy evaluation 원리를 데이터 로딩에 적용해, 한 번에 메모리에 올리는 데이터를 단 하나의 샘플로 제한합니다. tf.data.generator()로 파이프라인을 구성하면 .shuffle(), .batch(), .prefetch()를 체인으로 연결해 conveyor belt 방식의 학습이 가능해집니다.
여기서 데이터 품질 관점의 경고가 하나 있습니다. shuffle 버퍼 크기를 잘못 설정하면 편향이 학습에 그대로 반영됩니다. 고양이 1,000장 → 개 1,000장 순으로 정렬된 데이터셋에서 버퍼 크기를 1,000으로 설정하면, 버퍼는 결코 두 클래스를 섞지 않습니다. catastrophic forgetting의 원인이 모델 구조가 아니라 파이프라인 설계 실수인 경우가 생각보다 많습니다. 이건 correlation이 아닌 causation입니다—데이터 순서가 학습 성능을 직접 결정합니다.
커스텀 모델의 진짜 가치: 일반화냐, 특수화냐
Hand Pose 커스텀 모델 구축 사례(출처: dev.to)는 또 다른 질문을 던집니다. Apple Vision 프레임워크의 사전학습 모델로도 손 랜드마크 21개를 추출할 수 있는데, 왜 굳이 CreateML로 커스텀 분류기를 훈련했을까요?
답은 도메인 특화(domain specificity)에 있습니다. 범용 손동작 인식 모델은 일반적인 제스처에 대해 높은 recall을 갖지만, 특정 사용자의 독특한 제스처 패턴—이 사례에서는 반려묘를 추모하는 개인적 맥락의 제스처—에 대해서는 precision이 떨어질 수밖에 없습니다. 21개 랜드마크(x, y, z) 좌표를 63차원 feature vector로 변환하고 손목 위치를 기준으로 정규화하는 전처리 과정은 사실상 도메인 지식 기반 feature engineering입니다.
중요한 시사점은 이것입니다. 샘플 사이즈가 충분한가요? 단일 사용자의 제스처 데이터로 훈련된 모델은 다른 사용자에게 일반화되지 않습니다. 이건 버그가 아니라 설계 의도지만, 모델 카드(model card)에 사용 범위와 한계를 명시하지 않으면 나중에 misuse로 이어집니다. '이 모델은 해석 가능한가요?'—21개 랜드마크 기반 분류기는 적어도 어떤 특징이 결정에 기여하는지 SHAP 값으로 분석할 수 있다는 점에서 블랙박스 딥러닝보다 explainability 측면에서 유리합니다.
세 사례가 수렴하는 지점: 파이프라인 품질의 3축
Qwen3.5 벤치마크, TensorFlow.js 데이터 스트리밍, Hand Pose 커스텀 모델—표면상 무관해 보이는 세 사례는 ML 파이프라인 품질을 평가하는 세 가지 축으로 수렴합니다.
첫째, 평가 신뢰성(Evaluation Reliability). 벤치마크 점수는 측정 조건의 함수입니다. 동일 모델도 평가 프롬프트 포맷, few-shot 예제 수, 온도(temperature) 설정에 따라 ROC-AUC가 수 포인트씩 달라집니다. SOTA 선언보다 재현 가능한 평가 코드가 더 가치 있습니다.
둘째, 데이터 흐름 설계(Data Flow Design). Out-of-Core 학습이 보여주듯, 메모리 한계는 알고리즘이 아니라 파이프라인 아키텍처로 극복합니다. 모델 정확도를 높이기 전에 데이터가 편향 없이, 효율적으로 모델에 도달하는지를 먼저 점검해야 합니다.
셋째, 일반화 범위의 명시(Generalization Scope Documentation). 특수화된 커스텀 모델은 범용 모델보다 좁은 분포에서 더 높은 성능을 냅니다. 중요한 것은 그 범위를 정직하게 문서화하는 것입니다. '이 데이터에는 어떤 편향이 있을까요?'라는 질문을 모델 출시 전에 먼저 던지는 팀이, 출시 후 데이터 드리프트로 당황하는 팀보다 운영 비용이 낮습니다.
전망: 숫자를 읽는 법이 경쟁력이 된다
오픈소스 LLM의 성능이 closed-model과 어깨를 나란히 하는 속도는 예상보다 빠릅니다. 6개월 후 self-hosting 손익분기점이 어디일지 계산해보는 것은 이미 실용적인 작업입니다. 그러나 그 계산의 전제가 되는 벤치마크 숫자를 검증하지 않으면, 잘못된 모델을 잘못된 파이프라인에 올리는 실수를 비용을 들여 반복하게 됩니다.
좋은 ML 파이프라인은 화려한 SOTA 수치가 아니라 측정 가능하고, 재현 가능하고, 운영 환경에서 안정적인 세 가지 조건을 동시에 만족할 때 신뢰를 얻습니다. 벤치마크 발표가 쏟아질수록, 그 숫자 뒤에 있는 샘플 사이즈·평가 조건·데이터 분포를 읽는 능력이 실질적인 차별화 포인트가 됩니다. 숫자보다 맥락을 먼저 보는 습관—그게 지금 ML 파이프라인에서 가장 부족한 품질 지표입니다.