AI 에이전트/챗봇을 제품에 붙이면 가장 먼저 터지는 건 두 가지입니다. 첫째 COGS(토큰·크롤링·재시도 비용) 폭증, 둘째 실패율(403·CAPTCHA·접속 실패·헛호출)입니다. 유저는 “대답 못하는 봇”을 한 번 겪으면 바로 이탈하고, 우리는 그 이탈을 만들기 위해 돈을 씁니다. 유저가 여기서 이탈할 것 같은데… 이 구간이 딱 온보딩/문의 퍼널의 병목이에요.
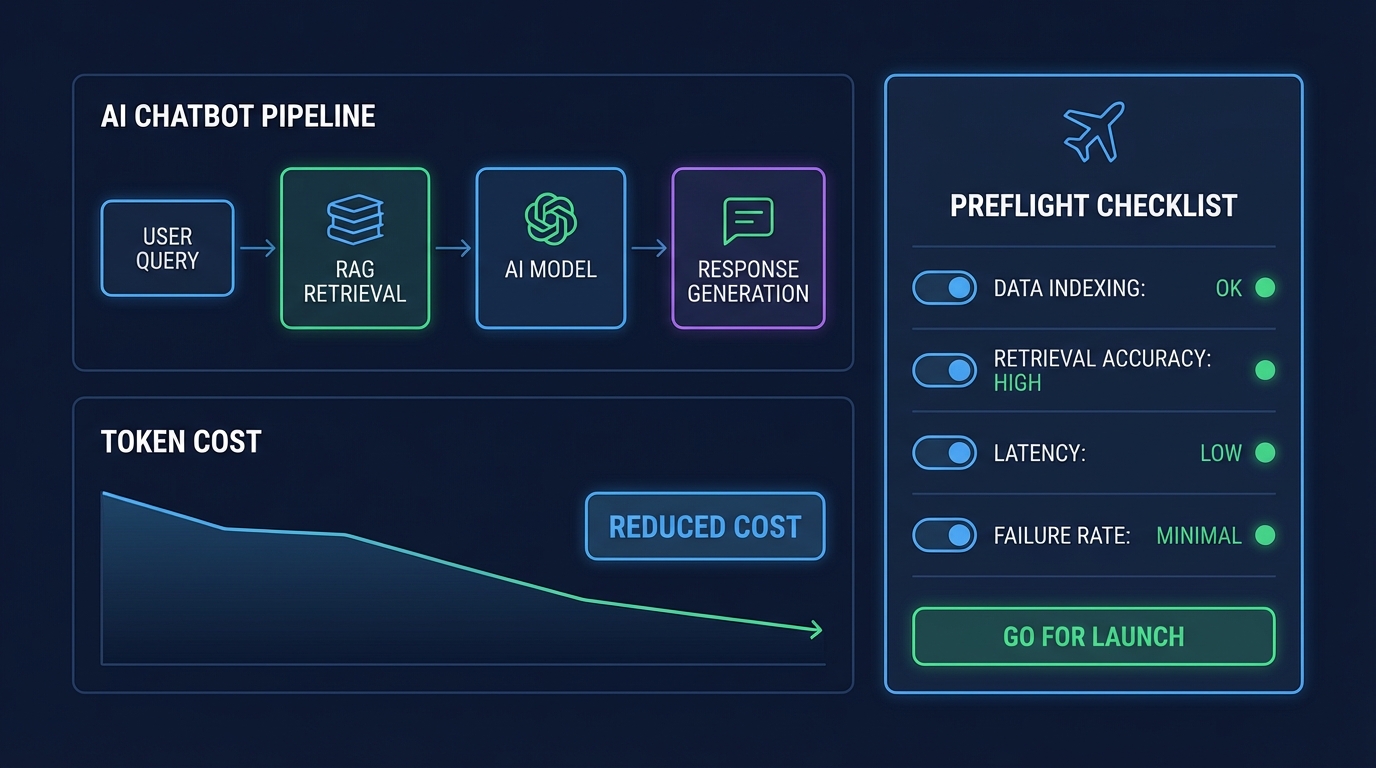
이번 dev.to의 두 글이 이 병목을 정면으로 찌릅니다. 하나는 “주말에 RAG Q&A 봇을 실제로 배포”한 튜토리얼(로컬 벡터DB FAISS + LangChain + Mistral + FastAPI + Docker, 평가엔 RAGAS)이고(Clint Westbrook), 다른 하나는 “에이전트가 사이트에 들어가 보기 전에 협조적인지 미리 점검”하는 프리플라이트 체크 아이디어입니다(Silicon Friendly의 L0~L5 등급 + MCP 서버로 런타임 조회).
맥락을 그로스 관점으로 번역하면 이렇습니다. RAG 튜토리얼이 말하는 핵심은 ‘LLM을 똑똑하게’가 아니라 ‘정답을 찾는 비용을 고정비에서 변동비로, 또 작은 변동비로’ 바꾸는 겁니다. 최신 데이터(공연 일정 같은)가 계속 바뀌는 도메인에서 모델 파인튜닝은 느리고 비싸고 리스크가 큽니다. 반면 FAISS 같은 로컬 인덱스는 쿼리당 검색을 밀리초 단위로 끝내고, LLM에는 “필요한 컨텍스트만” 먹여 토큰을 줄입니다. 이거다! RAG는 품질뿐 아니라 토큰 예산의 통제 장치예요.
반대로 프리플라이트 체크 글은 실패율을 ‘운’이 아니라 ‘측정 가능한 변수’로 만듭니다. 에이전트가 403→재시도→CAPTCHA→JS 덩어리 200KB 파싱으로 4,000토큰 태우는 순간, 그건 단순 에러가 아니라 마진을 깎는 자동화된 낭비입니다. Silicon Friendly가 L0~L5로 “에이전트 친화도”를 점수화하고, MCP로 에이전트가 런타임에 check_agent_friendliness를 호출해 의사결정을 바꾸게 하는 건, 말 그대로 호출 전 안전벨트입니다.
시사점은 실행 조합입니다. (1) 내부 지식/자사 데이터는 RAG로: 크롤링 대신 API/DB에서 가져오고, 정제→청킹→벡터화→검색→생성 파이프라인을 Docker로 고정합니다(dev.to RAG 글의 방식). (2) 외부 의존(결제, 이메일, 지도, 크롤링 대상)은 프리플라이트로: L3 이상만 기본 채택, L2 이하면 우회(공식 API/파트너/대체 서비스), L0/L1이면 처음부터 “안 하는” 정책을 둡니다(dev.to 프리플라이트 글의 Silicon Friendly 등급). 이거 바이럴 될 것 같은데? “우리 봇은 실패를 줄여 답변 성공률이 높다”는 메시지는 B2B 데모에서 전환 포인트가 됩니다.
그로스 지표로 연결하면 더 선명합니다. 프리플라이트로 실패 재시도를 줄이면 쿼리당 비용(COGS/query)이 내려가고, 답변 성공률이 올라가면 문의/탐색 퍼널의 전환율이 오릅니다. 예를 들어 ‘첫 질문에서 유효 답변 제공’ 비율이 올라가면 D1 리텐션이 같이 움직여요. 결국 LTV가 올라가고 CAC 회수 기간이 짧아집니다. 빨리 테스트해봐야 돼! 추천 실험은 2주짜리로: (A) 프리플라이트 ON/OFF, (B) RAG 컨텍스트 길이(청크 크기·TopK) 조정, KPI는 “답변 성공률, 평균 토큰, 외부 호출 실패율, 첫 세션 이탈률”로 잡으면 됩니다.
전망은 명확합니다. RAG는 이제 ‘성능 올리는 기술’이라기보다 원가를 통제하는 제품화 표준이 되고, 에이전트는 ‘똑똑한 자동화’보다 실패를 설계 단계에서 제거하는 운영 시스템으로 진화합니다. 결국 남는 팀은 “모델이 뭘 할 수 있나”가 아니라 “어디서 돈이 새는가, 어디서 유저가 떠나는가”를 먼저 보는 팀입니다. 비용과 실패율을 동시에 잡는 순간, 챗봇은 장식이 아니라 성장 레버가 됩니다.