"버튼 클릭했는데 숫자가 왜 1밖에 안 올라가요?"
프론트엔드 개발하다 보면 이런 버그, 한 번쯤 마주쳐봤을 거예요. setNumber(number + 1)을 세 줄이나 썼는데 실제로는 1만 증가하는 상황. 디자인 시안에서 margin이 8px인지 9px인지 따지듯, 이 1의 차이가 프로덕션에서 조용히 버그를 만들어냅니다. Velog에 올라온 React state 업데이트 큐 관련 분석을 보면서, 이게 단순한 입문 지식이 아니라 상태 설계 전략의 핵심이라는 걸 다시 한번 느꼈어요.
React Batching: "묶음 처리"가 생각보다 깊다
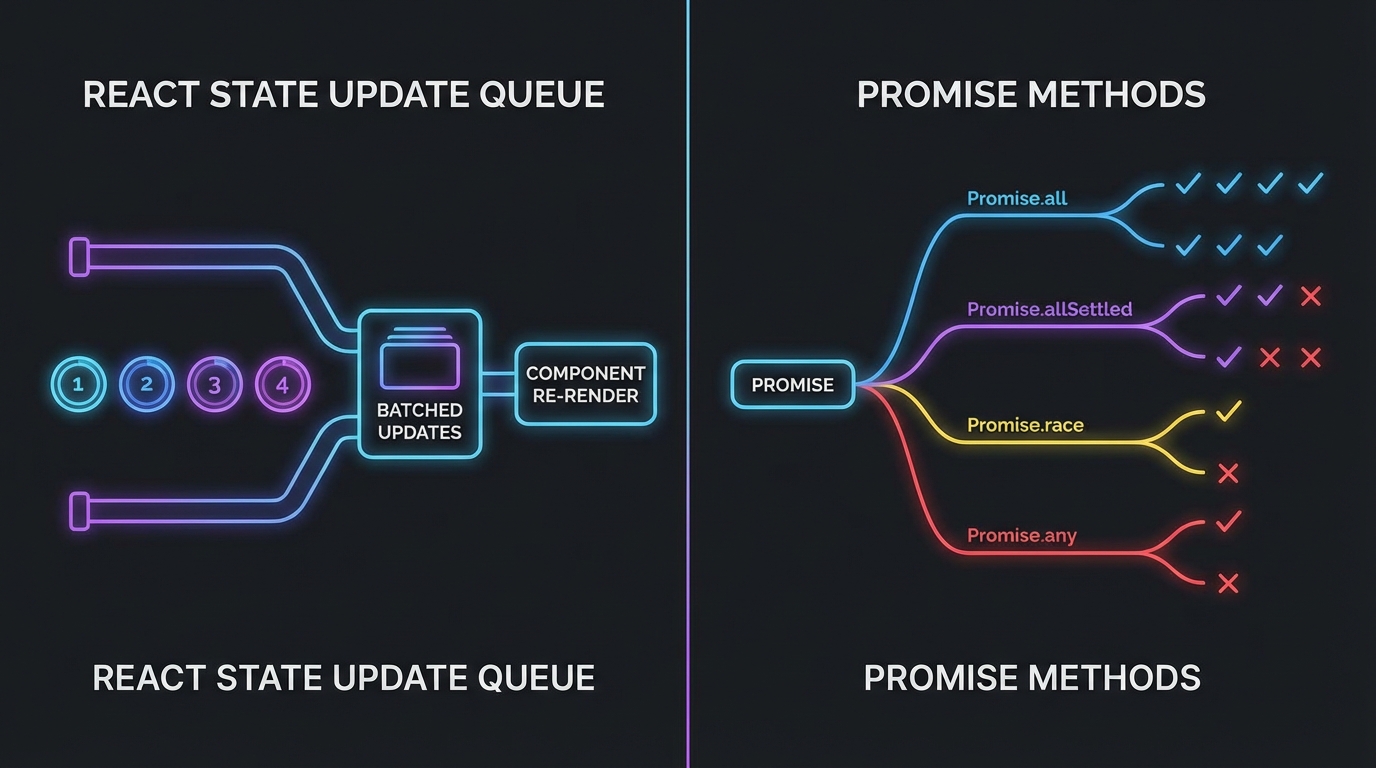
React가 상태 업데이트를 Batching한다는 건 많이들 알고 있죠. 하나의 이벤트 핸들러 안에서 setState를 여러 번 호출해도 리렌더링은 한 번만 일어난다는 것. 근데 여기서 많이들 놓치는 게 있어요. setNumber(number + 1)은 그 렌더링 시점의 고정된 스냅샷 값을 쓰기 때문에, 세 번 호출해도 결국 setNumber(0 + 1) 세 번을 실행하는 셈이라는 거예요.
이걸 해결하는 게 바로 Updater Function 패턴입니다. setNumber(n => n + 1) 형태로 넘기면, React는 이 함수들을 큐에 순서대로 쌓아서 이전 결과를 다음 함수의 인수로 전달합니다. 마치 CSS transform을 여러 개 체이닝할 때 순서가 결과를 바꾸듯, 상태 업데이트도 순서와 방식이 결과를 완전히 바꿔놓아요. Figma에서 볼 때는 당연해 보이던 레이아웃이 실제 구현에서 어긋나는 것처럼, 직관과 실제 동작 사이의 갭이 여기서도 정확히 발생합니다.
상태 관리 vs URL 기반 라우팅: Single Source of Truth의 위치 문제
또 하나의 고질적인 설계 딜레마가 있어요. 모드 전환이나 탭 선택 같은 UI 상태를 useState로 관리할 것인가, React Router의 URL로 관리할 것인가. Velog의 상태관리 vs Router 비교 분석이 이 지점을 잘 짚어줬는데요.
useState로 화면을 전환하면 리렌더링 트리거가 간단하고 코드도 직관적입니다. 하지만 새로고침하면 상태가 날아가고, URL 공유가 불가능해요. 사용자 입장에서는 "방금 보던 페이지를 동료한테 링크로 보내고 싶은" 순간이 반드시 옵니다. 그때 URL에 상태가 없으면 UX가 바로 무너지죠. useParams()로 URL의 :topic_id를 끌어오고, <Outlet />으로 부모 레이아웃을 유지하면서 내용만 교체하는 패턴이 그래서 생긴 겁니다. 어떤 상태가 "공유 가능해야" 하는지를 기획 단계에서 명확히 정의하지 않으면, 개발 막바지에 라우팅 구조를 통째로 갈아엎는 상황이 생겨요. 저는 이게 기획자가 명세서에 꼭 써줘야 할 항목이라고 봅니다.
Promise 메서드 선택: race와 any를 구분 못 하면 프로덕션이 조용히 터진다
Dev.to에 올라온 Promise 메서드 심층 비교 글이 상당히 인상적이었어요. 백엔드 개발자가 Promise.race로 폴백 로직을 짰다가 버그를 낸 사례가 출발점인데, 사실 이건 프론트엔드 개발자들도 자주 틀리는 부분입니다.
핵심만 짚으면:
- Promise.race: 가장 먼저 끝난 것이 이기는데, 실패(reject)도 이길 수 있어요. 타임아웃 구현에 적합.
- Promise.any: 가장 먼저 성공한 것만 이겨요. CDN 폴백, 백업 API 패턴에 써야 할 건 이쪽.
- Promise.all: 전부 성공해야 resolve. 대시보드처럼 모든 API 응답이 필요한 경우.
- Promise.allSettled: 성공이든 실패든 전부 기다린 뒤 결과 배열을 줍니다. 에러 핸들링을 개별적으로 해야 할 때.
사용자 입장에서 보면, 백업 API 패턴을 race로 잘못 구현했을 때 첫 번째 API가 빠르게 실패하면 백업도 없이 에러가 뜨는 최악의 시나리오가 나옵니다. Lighthouse 점수가 아무리 좋아도, 이런 로직 버그 하나가 실제 사용성을 박살냅니다. Promise.all 폴리필에서 result.push(value) 대신 result[index] = value를 써야 입력 순서가 보장된다는 디테일도, 1px 차이처럼 작아 보이지만 결과를 완전히 바꾸는 부분이에요.
TensorFlow.js + React 19 + PWA: 이게 다 엮이는 이유
Dev.to에서 소개된 APOD Mood Gallery 프로젝트가 흥미로운 건, 위에서 말한 모든 개념이 하나의 실제 프로젝트에 응축돼 있기 때문이에요. NASA APOD 이미지를 TensorFlow.js(MobileNet)로 브라우저 안에서 직접 분류하고, 3D 렌더링에 react-three-fiber를 쓰면서, 이미지 픽셀 처리는 Web Workers로 메인 스레드를 보호하는 구조입니다.
여기서 상태 설계가 얼마나 중요한지 다시 드러납니다. TensorFlow 추론 결과를 어디에 담을 것인가, Web Worker의 비동기 응답을 어떻게 React 렌더링 사이클과 연결할 것인가—이 지점에서 Batching과 Updater Function 이해가 없으면 추론 결과가 누락되거나 중복 렌더링이 폭발합니다. React 19의 개선된 배칭 동작(startTransition, Concurrent Features)과 엮이면 더 복잡해지고요. 로딩 스켈레톤 하나 넣는 것도, 비동기 상태 흐름을 정확히 알아야 언제 스켈레톤을 보이고 언제 숨길지 제대로 컨트롤할 수 있어요.
시사점: "작동하는 코드"와 "설계된 코드"의 차이
결국 세 가지 메시지로 정리됩니다.
첫째, 상태의 타이밍과 범위를 명확히 하세요. setState를 값으로 넘길지, 함수로 넘길지는 "이전 값에 의존하느냐"에 달려 있습니다. 의존한다면 항상 Updater Function을 쓰는 게 안전해요.
둘째, URL을 상태로 쓸지 여부는 기획 초기에 결정해야 합니다. 공유 가능성, 뒤로가기, 북마크—이 세 가지 중 하나라도 필요하다면 라우터로 빼야 합니다.
셋째, Promise 메서드는 실패 처리 전략에 따라 골라야 합니다. "하나만 성공하면 되는가(any)