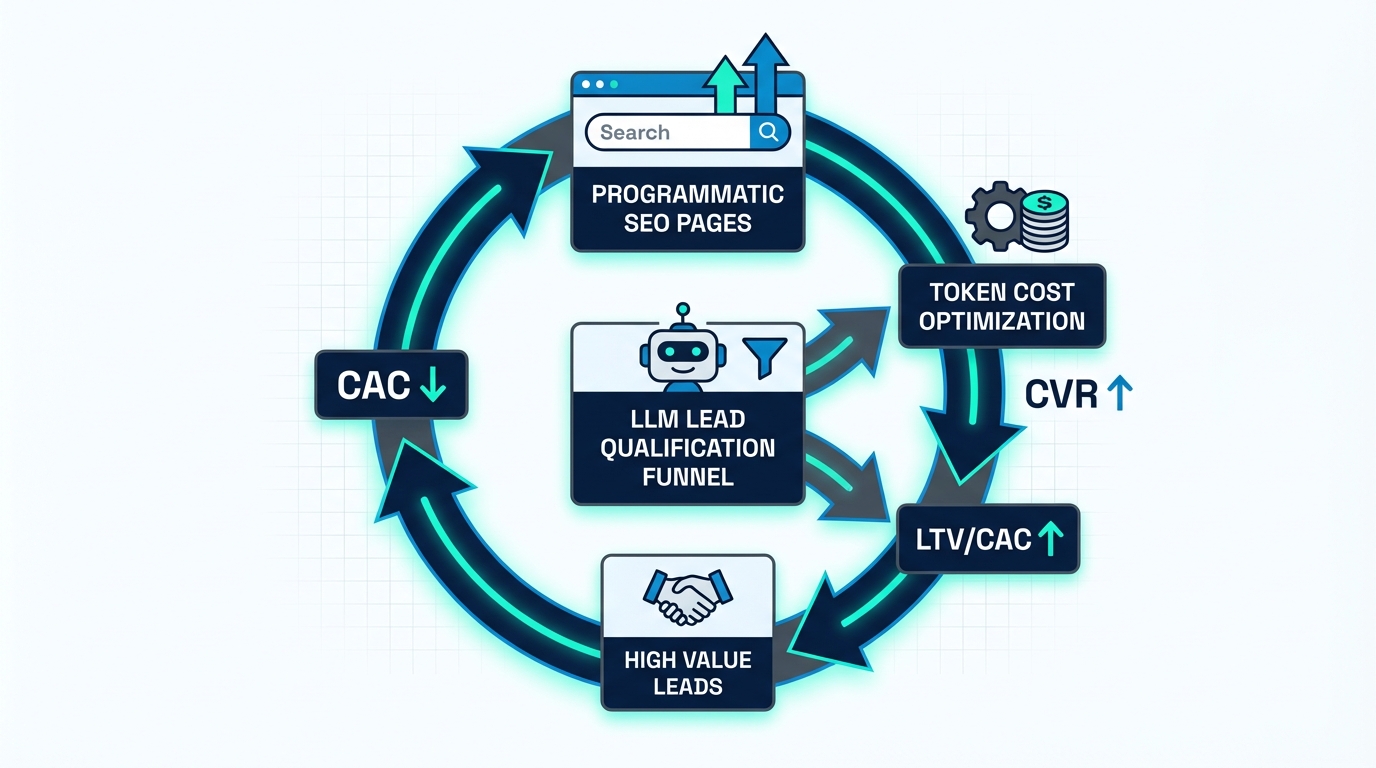
유저 획득이 막히면 다 막힙니다. 그런데 요즘 “와 이거다!” 싶은 조합이 보입니다: Programmatic SEO로 롱테일 랜딩을 대량 생성해 자연유입을 만들고, 들어온 리드를 LLM이 실시간으로 선별해 세일즈/CRM로 라우팅하고, 마지막으로 토큰·API 비용을 깎아 유닛 이코노믹스를 완성하는 루프. 기술 구현이 곧바로 CAC·CVR·마진으로 직결되는 게 핵심입니다.
이 조합의 첫 단추는 ‘페이지 수’가 아니라 ‘검색 의도에 정확히 맞는 도구형 랜딩’입니다. dev.to의 Timerjoy 사례는 Next.js 16 SSG로 1,182개 페이지를 정적으로 찍어내고(카테고리 37개), 각 페이지에 고유 메타데이터·JSON-LD·캐노니컬·사이트맵을 붙여 검색 엔진이 “각 페이지가 별개의 답”이라고 이해하게 설계했습니다. 게다가 평균 로드가 200ms 이하라면, 유입 후 이탈률부터 내려갈 확률이 큽니다. “이거 바이럴 될 것 같은데?”의 출발점이 사실 웹 성능과 무마찰 UX(팝업/가입 없음)인 셈이죠. (출처: dev.to Timerjoy 빌드 글)
맥락은 명확합니다. Programmatic SEO는 ‘콘텐츠 공장’이 아니라 ‘검색 쿼리 클러스터를 제품 기능으로 매핑’하는 전략입니다. 5분 타이머, 도시별 일출/일몰, 월령처럼 의도가 뾰족한 쿼리를 페이지-툴로 대응하면, 같은 도메인에서 내부 링크로 연쇄 탐색이 일어나고(세션 증가), 구글 인덱싱이 진행될수록 노출이 복리로 쌓입니다. Timerjoy가 첫 주부터 2.79만 노출이 찍힌 건, 양보다 “기술 SEO 인프라+도구 효용”이 만든 초기 신호로 읽을 만합니다.
하지만 유입만으로는 성장 루프가 닫히지 않습니다. 여기서 LLM 리드 퀄리피케이션이 퍼널의 ‘중간 누수’를 막습니다. dev.to의 프로덕션 가이드는 BANT(Budget/Authority/Need/Timeline) 신호를 대화에서 구조화 추출→스코어링→HOT/WARM/COLD로 티어링해, 세일즈가 고확률 리드에만 시간을 쓰게 만듭니다. 특히 2단계(추출과 점수 산정 분리)로 설계하면 프롬프트가 흔들려도 스코어 로직은 안정적으로 유지돼요. “유저가 여기서 이탈할 것 같은데...”를 사람이 감으로 막는 대신, 자동 분류로 SLA를 걸 수 있습니다. (출처: dev.to LLM lead qualification 글)
그로스 관점에서 이건 Conversion rate를 ‘사람 수’가 아니라 ‘응답 속도’로 올리는 해킹입니다. HOT 리드를 1시간 내 콜로 묶는 순간, 동일 리드 볼륨에서도 SQO/매출 전환이 바뀝니다. 게다가 하이쿠(저비용)로 1차 트리아지 후 오퍼스(고성능)로 재검증하는 하이브리드 비용 구조는, 퍼널 중간에서 CAC를 다시 한 번 깎는 방식이기도 합니다. 평균 리드당 비용을 0.006달러 수준으로 맞춘 접근은 “빨리 테스트해봐야 돼!”에 딱 맞는 비용대입니다.
마지막 퍼즐은 LTV/CAC를 좌우하는 ‘토큰 단가’입니다. 많은 팀이 프롬프트만 깎다가 놓치는 게, 실제로는 API가 뿌리는 장황한 JSON이 토큰을 태운다는 점이죠. dev.to의 사례는 엔터프라이즈 API 응답을 LLM 친화 포맷(LEAN)으로 무손실 인코딩해 약 46% 토큰을 줄였습니다. 이건 단순 절약이 아니라, 같은 예산으로 더 많은 리드 대화를 처리하거나 더 비싼 모델을 “중요한 순간에만” 쓸 수 있게 만드는 스케일 레버입니다. (출처: dev.to 토큰 절감/LEAN 인코더 글)
정리하면 성장 루프는 이렇게 닫힙니다. ① Programmatic SEO로 롱테일 유입을 값싸게 만든다(CAC↓). ② 랜딩/툴 안에서 리드 캡처를 유도하고, 대화·폼 데이터를 LLM이 즉시 구조화해 티어링한다(CVR↑, 세일즈 효율↑). ③ 데이터 페이로드/컨텍스트를 압축·정규화해 토큰 비용을 낮춘다(마진↑, LTV/CAC↑). 여기서 중요한 건 각 단계가 독립 기능이 아니라, AARRR 퍼널의 Acquisition→Activation→Revenue를 한 줄로 잇는다는 점입니다.
시사점은 세 가지입니다. 첫째, Programmatic SEO의 승패는 ‘인덱싱 가능한 품질’에 있습니다. 고유 메타·구조화 데이터·캐노니컬·사이트맵·내부링크는 선택이 아니라 필수이고, 무엇보다 페이지가 “진짜로 작동하는 도구”여야 얇은 콘텐츠 판정을 피할 확률이 큽니다. 둘째, LLM 퀄리피케이션은 CRM 라우팅까지 붙여야 전환이 납니다. 점수만 뽑고 아무도 안 보면 지표가 안 움직여요. 셋째, 토큰 최적화는 비용 절감이 아니라 ‘실험 속도’입니다. 토큰이 싸지면 A/B 테스트(프롬프트/라우팅/모델)를 더 자주 돌릴 수 있고, 그게 곧 성장 속도입니다.
전망을 한 문장으로 말하면: SEO가 다시 ‘자동화 가능한 퍼포먼스 채널’로 변하고 있습니다. 대량 생성(Next.js SSG 같은 빌드 파이프라인) + 자동 선별(LLM 구조화 추출/스코어링) + 비용 최적화(토큰/페이로드 압축)가 결합되면, 초기에는 작은 사이드프로젝트처럼 시작해도 인덱싱이 누적되는 순간부터 트래픽과 리드가 복리로 쌓입니다. 지금 할 일은 거창한 플랫폼이 아니라, “한 카테고리”로 MVP를 만들고 D7 리텐션/리드 전환율/리드당 토큰 비용 3개 지표로 바로 검증하는 것. 이 조합, 진짜 스케일 납니다.