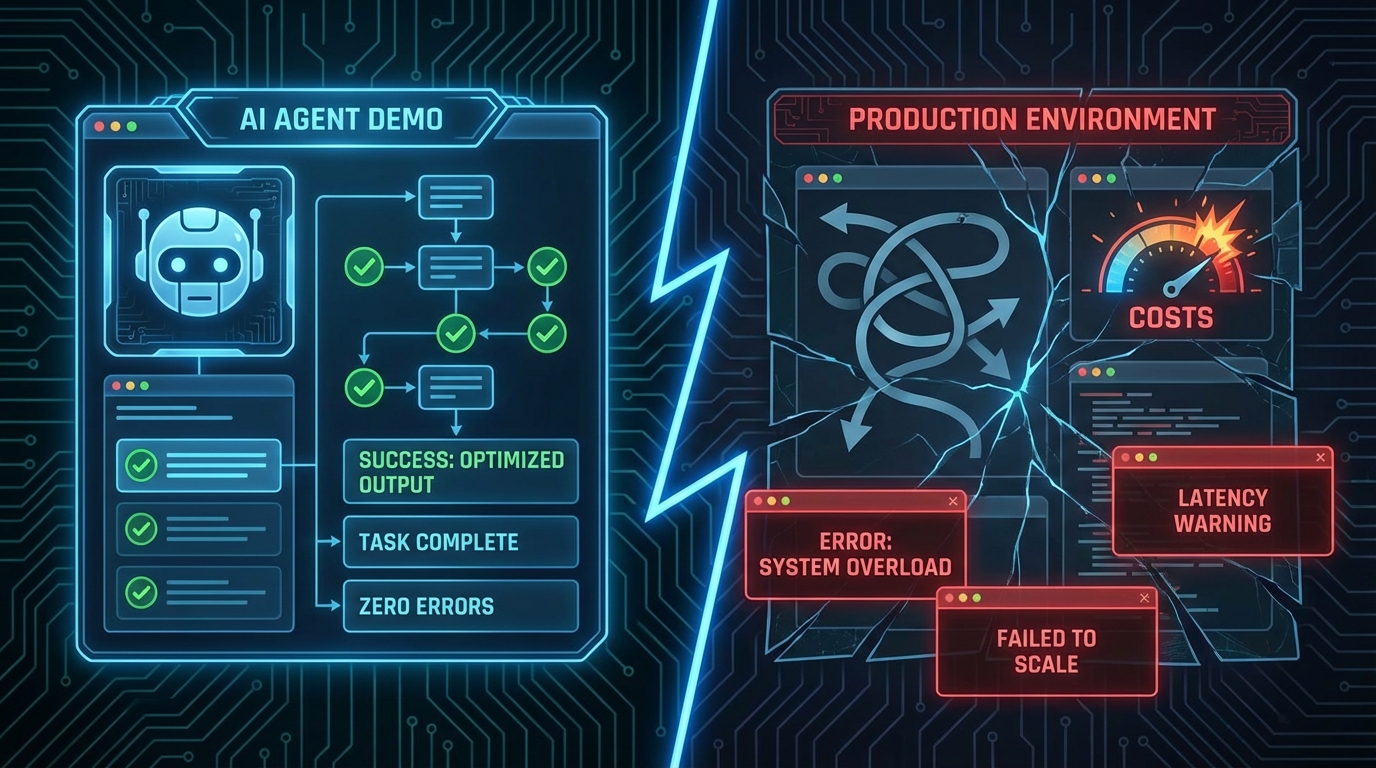
데모는 마법 쇼다
"이거 Claude한테 프로토타입 만들어달라고 했더니 진짜 잘 나왔어요." 팀에서 AI 에이전트 데모를 보여줄 때마다 늘 이 말이 나옵니다. 해피 패스를 따라 흐르고, LLM이 툴 콜을 정확히 날리고, 출력이 깔끔하게 떨어지면 모두가 고개를 끄덕입니다. 그리고 배포합니다.
그 다음에 프로덕션이 찾아옵니다.
에이전트가 애매한 입력에서 루프를 돕니다. 스키마 유효성 검사는 통과했지만 다운스트림에서 쓰레기를 뱉는 환각 파라미터가 나타납니다. $0.12짜리 작업에 $40 API 비용이 청구됩니다. 93%는 완벽하게 동작하고, 나머지 7%는 지원 티켓을 만들거나—더 나쁜 경우—완전한 확신을 가지고 틀린 액션을 실행합니다. dev.to에서 AgentProbe 개발자가 정리한 내용인데, 팀에 AI 에이전트를 도입하는 테크 리드 입장에서 읽으면서 등골이 서늘했습니다.
이건 프롬프트 문제가 아닙니다. 평가(Evaluation) 문제입니다.
아무도 테스트하지 않는 5가지 실패 모드
1. 자신감 넘치는 오답 (The Confident Wrong Turn)
가장 위험한 패턴입니다. 에이전트가 툴을 선택하고, 유효한 파라미터를 넘기고, 정상 응답을 받습니다. 그런데 완전히 엉뚱한 툴이었습니다. 로그는 깨끗합니다. 스키마 검증도 통과했습니다. 에이전트가 그냥... 틀린 일을 했을 뿐입니다. 당당하게.
단일 턴에서는 안 잡힙니다. 멀티스텝 워크플로우에서 문제는 대부분 "에이전트가 올바른 툴을 못 부른다"가 아니라, 이전 스텝의 맥락 추론 없이 그럴듯한 툴을 선택한다는 점입니다. 해결책은 개별 툴 콜이 아닌 전체 결정 체인을 테스트하는 것입니다. 예상 툴 시퀀스를 정의하고, 최종 출력이 아니라 경로 자체를 assertion 하세요.
2. 보이지 않는 비용 폭발 (The Invisible Cost Explosion)
작업은 올바르게 완료됐고, 출력도 훌륭합니다. 그런데 비용이 47배 나왔습니다. 에이전트가 리즈닝 루프에 빠져서—문제를 재서술하고, 컨텍스트를 다시 읽고, 툴을 중복 호출하고, 품질 향상 없이 토큰만 태우는 중간 chain-of-thought를 생성합니다. 개발 중엔 아무도 지출을 보고 있지 않기 때문에 안 잡힙니다.
"품질 없이 비용 인식은 데모 지표다, 프로덕션 지표가 아니다." AgentProbe 저자의 말이 정확합니다. 작업 클래스별로 코스트·토큰 예산을 설정하고, 초과를 테스트 실패로 처리하세요. 배포 전 게이트로 만들어야 합니다.
3. 컨텍스트 오염 (The State Bleed)
멀티 에이전트 시스템의 글로벌 변수 버그입니다. 에이전트 A가 사용자 1의 요청을 처리하고 유지한 컨텍스트가 사용자 2의 처리에 흘러들어갑니다. 또는 서브 에이전트가 오케스트레이터가 의도하지 않은 방식으로 부모 컨텍스트를 상속받습니다.
유닛 테스트에선 멀쩡합니다. 동시 사용자나 멀티 에이전트 파이프라인 통합 테스트에서 미묘하게 틀린 출력이 나옵니다. 컨커런트 부하에서 동일 입력에 동일 출력이 나오는지 격리 테스트가 필수입니다. 멀티 에이전트 시스템을 만들고 있다면, 컨커런시 하에서 컨텍스트 격리 테스트를 안 하는 건 데이터 누출을 배포하는 겁니다.
4. 우아하지 않은 실패 (The Graceful Degradation Failure)
다운스트림 툴이 타임아웃되거나, API가 500을 반환하거나, 레이트 리밋이 걸렸을 때 에이전트가 무한히 걸려있거나, 예산을 다 태울 때까지 재시도하거나, 사용자에게 날것의 에러 트레이스를 뱉습니다. 최악의 버전은 에이전트가 툴 실패를 인정하는 대신 응답을 환각하는 겁니다. 날씨 API 호출이 실패했는데 "맑고 72도입니다"라고 답하는 것. 신뢰를 파괴하는 실패입니다. 툴 레이어에 장애를 주입하고 복구 동작을 assertion 하세요.
5. 모르고 배포한 회귀 (The Regression You Didn't Know You Shipped)
시스템 프롬프트를 업데이트하거나, 모델 버전을 교체하거나, 툴 스키마를 변경했습니다. 기존 테스트는 다 통과합니다. 그런데 테스트가 커버하지 않는 동작—사용자들이 발견하고 의존하게 된 창발적 행동—이 조용히 깨집니다. 프로덕션 인터랙션을 골든 데이터셋으로 기록하고, 모든 변경 후 리플레이하는 행동 회귀 테스트가 필요합니다.
4가지 장애 허용 패턴: 실패를 전제로 설계하라
또 다른 dev.to 글에서 실제 14팀 멀티 에이전트 시스템을 운영하다 첫 주에 3팀이 크래시한 경험을 공유했습니다. 로직이 틀려서가 아니라, 시스템에 우아하게 실패하는 방법을 아무도 설계하지 않았기 때문입니다.
패턴 1: 지수 백오프 재시도 정책. 고정 간격 재시도는 서비스가 복구될 때 동시 요청 스파이크를 만들어 계단식 실패를 유발합니다. LangGraph의 RetryPolicy처럼 지터가 있는 지수 백오프로 재시도를 시간 전반에 분산시키세요.
패턴 2: 모델 폴백 체인. 프라이머리 모델이 다운되면 전체 에이전트가 멈춥니다. 미들웨어 레이어로 자동 모델 전환을 구성하되, 폴백보다 재시도를 먼저 시도하도록 순서를 설계하세요. 프라이머리 모델이 회복됐을 때 불필요하게 저렴하거나 느린 모델을 쓰는 걸 방지합니다.
패턴 3: 에러 분류와 차별적 라우팅. 모든 에러를 같은 방식으로 처리하는 것—재시도하고 기도하기—이 대부분 에이전트 실패의 근본 원인입니다. 트랜지언트 에러(네트워크, 레이트 리밋)는 재시도, LLM이 복구 가능한 에러(툴 실패, 파싱 이슈)는 에러를 상태에 저장하고 에이전트에게 다시 넘겨 재구성하게 하세요. 툴이 실패하면 같은 호출을 재시도하는 게 아니라, 에러를 LLM에게 보여줘서 쿼리를 재구성하게 하는 것이 핵심입니다. 사용자가 고쳐야 하는 에러는 인터럽트, 버그는 버블업. 그리고 반드시 시도 횟수 상한을 설정하세요.
패턴 4: 체크포인트 기반 복구. 50개 아이템 중 47개를 처리하고 48번에서 크래시해서 처음부터 재시작하는 건 가장 비싼 실패입니다. 노드 경계마다 상태를 저장하는 체크포인팅으로 중간에서 재개할 수 있도록 설계하세요.
"절대 건드리지 마"—AI 코딩 에이전트가 무시할 때
에이전트 실패가 인프라 레벨에 있다면, AI 코딩 에이전트 문제는 더 가까운 곳에 있습니다. 실제로 SaaS 앱을 Bolt.new에서 개발하다 "다크 테마 추가해줘"라고 했더니 다크 테마가 추가되고 인증 시스템이 재작성되고 DB 쿼리가 바뀌고 건드리지 말라던 3개 페이지가 깨졌다는 경험담이 공유됐습니다.
이건 낯설지 않습니다. Claude Code가 auto-memory를 가지고, Cursor에 Memory Bank가 있고, .cursorrules와 AGENTS.md가 존재합니다. 하지만 메모리와 강제(enforcement)는 다른 것입니다.
통계가 이걸 뒷받침합니다. Stack Overflow 2025 데이터에 따르면 개발자의 66%가 AI가 "거의 맞지만 완전히 맞지는 않은" 솔루션을 준다고 답했고, Georgetown CSET 분석에서는 AI 생성 코드의 45%에 보안 취약점이 포함됩니다. Cursor 자체 포럼에도 "The Vicious Circle of Agent Context Loss", "Cursor가 .mdc 지침을 자주 무시한다" 같은 스레드가 올라옵니다.
기억하는 것과 존중하는 것은 다릅니다.
.cursorrules와 AGENTS.md가 실패하는 이유는 그것들이 제안이기 때문입니다. AI가 읽고 나서 자기 판단대로 행동합니다. LLM은 확률적으로 동작하고, 현재 요청과 저장된 제약이 충돌할 때 현재 요청 쪽으로 해결하는 경향이 있습니다. LLM은 도움이 되도록 최적화되어 있지, 경계를 존중하도록 최적화되어 있지 않습니다.
SpecLock이라는 오픈소스 제약 엔진이 이 문제를 3개 레이어로 접근합니다. package.json에 락을 임베드해 모든 AI 툴이 세션 시작 시 제약을 읽게 하고, 제안된 액션과 락을 시맨틱 레벨에서 비교해 충돌을 탐지하며, 락된 파일에 경고 헤더를 주입해 AI가 파일을 열어 편집하려 할 때 물리적으로 마주치게 합니다. "질문은 허락이 아니다. unlock만이 허락이다." 이 원칙이 핵심입니다.
산업 인프라도 같은 방향으로 움직이고 있다
이 두 문제—에이전트의 프로덕션 안정성과 AI 코딩 에이전트의 제약 강제—는 사실 같은 뿌리에서 나옵니다. AI 에이전트가 무상태(stateless)로 설계되어 있다는 것입니다.
AI타임스 보도에 따르면, OpenAI와 Amazon이 발표한 파트너십의 기술 핵심도 바로 이 지점입니다. AWS Bedrock에서 구축될 상태 저장 런타임 환경(Stateful Runtime Environment)은 에이전트가 메모리, 대화 기록, 툴 사용 현황, 워크플로 진행 상태, 실행 환경, 신원과 권한 범위를 세션에 걸쳐 유지할 수 있게 합니다. 개발팀이 직접 오케스트레이션 레이어를 만들고 상태 저장 로직을 짜야 했던 부담을 인프라 레벨에서 흡수하는 방향입니다.
기존 Microsoft Azure의 무상태 API와 달리, 이 환경에서는 에이전트가 지속적인 맥락과 정체성을 유지합니다. 수주, 수개월에 걸친 복잡한 워크플로우를 중단 없이 처리하는 'AI 동료'에 적합한 구조입니다. 각 에이전트에 고유 ID가 부여되고 명확한 권한 범위가 설정되는 것도 주목할 점입니다.
테크 리드가 지금 당장 해야 할 것
"AI로 이거 어떻게 하면 좋을까요?"를 먼저 묻는 팀 문화를 만들려면, 동시에 "AI가 이걸 망가뜨리면 어떻게 할까요?"를 시스템 레벨에서 답해놔야 합니다. 세 가지 소스를 읽으면서 정리한 실천 항목입니다.
평가 파이프라인을 배포 파이프라인만큼 진지하게 만드세요. 툴 시퀀스 검증, 비용 예산 게이트, 컨텍스트 격리 테스트, 장애 주입, 골든 데이터셋 회귀 테스트—이 다섯 가지가 없는 AI 에이전트는 데모 상태입니다.
장애를 전제로 설계하세요. 지수 백오프, 모델 폴백, 에러 분류 라우팅, 체크포인팅. 이 네 패턴은 선택이 아니라 프로덕션 요구사항입니다. AI 에이전트가 실패하는 게 문제가 아니라, 실패를 어떻게 다루느냐가 시스템의 신뢰도를 결정합니다.
AI 코딩 에이전트에는 메모리가 아니라 강제가 필요합니다. .cursorrules 파일에 "auth 건드리지 마세요"라고 써놓는 것만으로는 부족합니다. 팀 차원에서 어떤 파일, 어떤 영역을 락할지 명시적으로 합의하고, 강제하는 레이어를 추가하세요. SpecLock 같은 도구가 그 선택지가 될 수 있습니다.
상태 저장 런타임 환경이 인프라 레벨에서 이 문제들을 점차 흡수해갈 겁니다. OpenAI-Amazon 파트너십이 현실화되면 오케스트레이션 부담이 크게 줄어들 것입니다. 하지만 그게 출시될 때까지, 그리고 그 이후에도 팀이 AI 에이전트를 안전하게 운영하는 역량 자체는 테크 리드가 만들어야 합니다.
AI가 생성해준 코드와 에이전트 플로우를 기반으로 우리가 다듬는 협업 모델—그 '다듬는 과정'에 평가, 장애 허용, 제약 강제가 들어가야 합니다. 데모에서 프로덕션으로 넘어가는 그 간극을 메우는 것, 그게 지금 AI-First 팀의 진짜 엔지니어링 과제입니다.