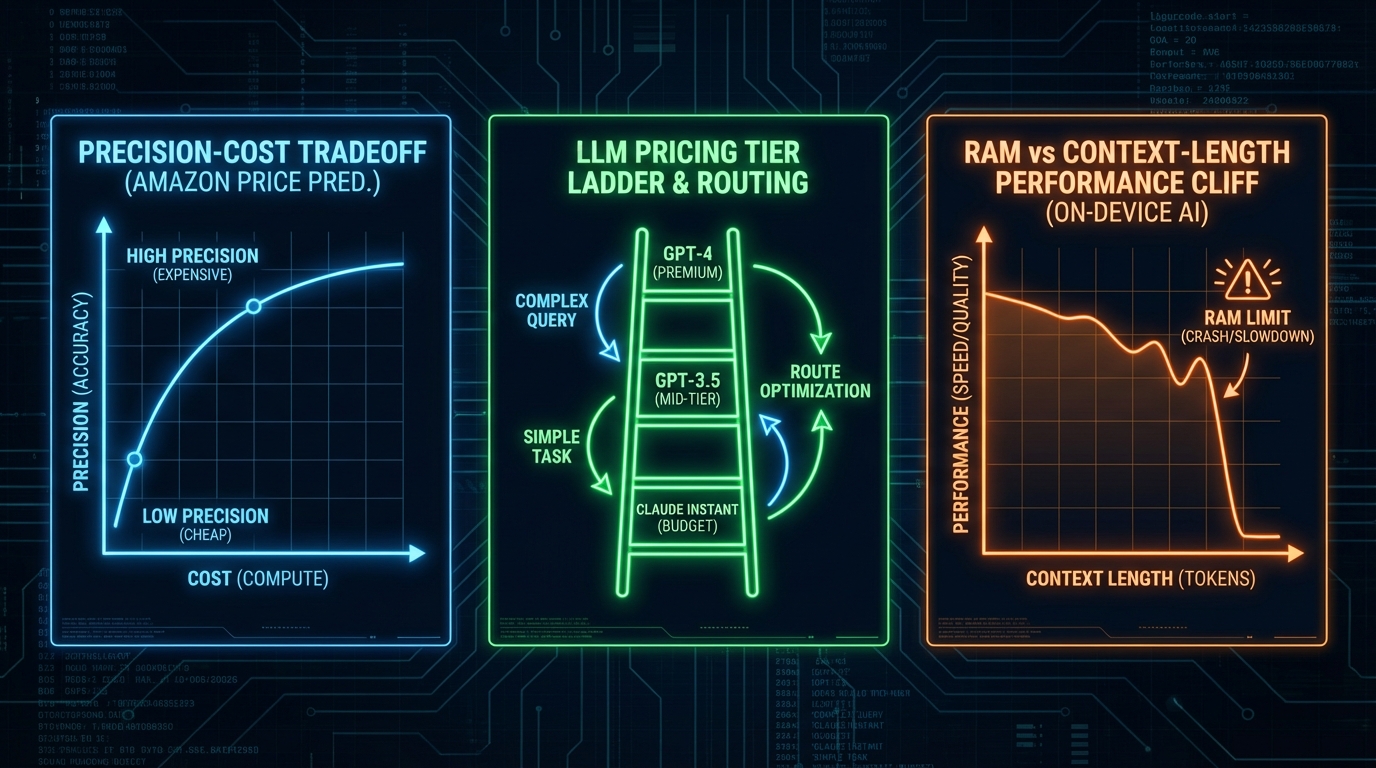
세 개의 숫자가 말하는 것
최근 ML 실무 커뮤니티에서 주목할 만한 숫자 세 개가 나왔습니다. Amazon 가격 예측 83% 정확도, LLM API 최저·최고가 간 600배(정확히는 4,725배) 격차, 그리고 온디바이스 에이전트 AI의 현실적 맥락 한계인 4K 토큰. 각각 따로 보면 흥미로운 케이스 스터디지만, 함께 놓으면 ML 시스템이 직면한 하나의 구조적 트릴레마가 보입니다. 정확도를 올리면 비용이 오르고, 비용을 낮추면 인프라가 발목을 잡으며, 인프라를 엣지로 내리면 정확도가 무너집니다.
83% 정확도—베이스라인 대비 얼마나 의미 있는가?
dev.to에 공개된 Avluz.com의 Amazon 동적 가격 예측 시스템 구축기는 솔직한 실패 로그 덕분에 오히려 신뢰가 갑니다. 6개월, 5만 개 상품, 하루 7.3회 가격 업데이트를 처리하며 최종 83% 정확도에 도달했다고 밝히는데—중요한 건 월별 진화 곡선입니다. 1개월 차 선형 회귀 베이스라인 47%에서 출발해, 시계열 피처 추가로 62%, 경쟁사 가격 피처 통합으로 71%, 수요 시그널 결합으로 78%, 앙상블 전환으로 81%, 하이퍼파라미터 튜닝으로 83%에 도달했습니다.
여기서 먼저 던져야 할 질문은 '83%가 어떤 지표인가'입니다. R² 스코어인지, 방향성 예측 정확도(가격이 오를지 내릴지)인지, RMSE 기반 허용 오차 내 적중률인지 원문은 명확히 구분하지 않습니다. 가격 예측에서 Precision/Recall보다 예측 방향성 정확도와 MAE가 더 실용적 지표인데, 이 부분이 불명확합니다. 또한 흥미로운 실패 사례도 있습니다. LSTM 도입 시 오히려 58%로 하락했고, 경쟁사 10개 사이트 실시간 스크래핑은 정확도 2% 향상에 인프라 비용 4배 증가라는 처참한 비용-성능 트레이드오프를 기록했습니다. 이건 correlation이지 causation이 아니라는 교훈이기도 합니다—경쟁사 가격이 변동과 상관되더라도 인과적 예측력은 제한적이었던 것입니다.
600배 격차—라우팅 분류기의 94% 정확도는 충분한가?
같은 플랫폼에서 LLM 비용 최적화 도구 NadirClaw를 소개한 글은 더 직접적으로 비용-성능 트레이드오프를 파고듭니다. Mistral Nemo $0.02/M 토큰에서 GPT-5.2 Pro $94.50/M까지, 실용적 비교 기준인 Gemini Flash 대 Claude Opus만 해도 60배 격차가 존재합니다. 핵심 주장은 '프롬프트의 70%는 단순 작업이므로 저가 모델로 라우팅하면 비용 60~70% 절감이 가능하다'는 것입니다.
분류기 자체의 성능이 관건입니다. 1만 개 레이블 프롬프트로 훈련한 200줄짜리 그래디언트 부스팅 분류기가 94% 정확도로 복잡도 티어를 분류한다고 주장하는데—샘플 사이즈 1만 개가 도메인 다양성을 충분히 커버하는지, 그리고 94%의 오분류 6%가 어느 방향인지(단순→프리미엄 오분류 vs 복잡→저가 오분류)가 비용 절감 실현 가능성에 결정적 영향을 미칩니다. 오분류가 '복잡한 쿼리를 저가 모델로 보내는' 방향이면 품질 손실이 발생하고, 반대 방향이면 비용 절감 폭이 줄어듭니다. '제로 품질 손실' 주장에는 ablation study가 필요합니다.
그럼에도 전략 자체의 방향성은 데이터가 뒷받침합니다. 500 req/day 규모 개발자 시나리오에서 월 $712 → $220, 1만 유저 챗봇에서 $504 → $225로 계산하는데, 이 숫자들은 라우팅 정확도가 90% 이상 유지된다는 전제 하에서만 성립합니다. 실제 운영 환경에서 데이터 드리프트가 발생하면—유저의 프롬프트 패턴이 시간에 따라 바뀌면—분류기 재학습 파이프라인이 없으면 절감 효과는 빠르게 희석됩니다.
온디바이스 AI—KV 캐시가 모든 것을 먹는다
가장 냉정한 분석은 온디바이스 에이전트 AI의 물리적 한계를 다룬 세 번째 글에서 나옵니다. 결론부터 말하면: 지금 당장 대부분의 소비자 디바이스에서 진짜 에이전트 AI는 불가능합니다. 이유는 두 가지 하드웨어 제약의 중첩입니다.
첫째, RAM 용량 문제. 7B 파라미터 모델(프론티어 대비 여전히 200~500배 작음)은 양자화 상태에서도 약 5GB RAM을 요구합니다. iPhone 17 Pro의 AI 가용 메모리가 약 8GB인데, 모델 로딩만으로 절반이 소진됩니다. 여기에 KV 캐시 문제가 겹칩니다. 에이전트 워크플로우에서 툴 정의만으로도 4K 토큰을 소진하고, 실제 데이터(이메일, 캘린더)를 포함하면 32K+ 컨텍스트가 필수인데, 7B Q4 모델 기준 32K 컨텍스트의 KV 캐시는 8GB RAM을 초과합니다.
둘째, 추론 속도의 컨텍스트 의존성. 소비자 디바이스에서 소형 모델 기준 ~30 tok/s는 체감상 사용 가능한 속도입니다. 그러나 컨텍스트가 16K를 넘어가면 Radeon 9070 XT(304W 데스크톱 GPU)조차 8B 모델에서 10 tok/s 이하로 급락합니다. 폰은 여기에 발열 스로틀링까지 더해집니다. 긴 이메일 한 통 생성에 1분 이상 걸리면, 직접 타이핑이 빠릅니다.
설상가상으로 RAM 가격이 300% 이상 폭등하면서 제조사들이 오히려 메모리를 줄이는 방향으로 움직이고 있습니다. HBM(데이터센터용)과 DDR5(소비자용)가 동일한 DRAM 웨이퍼 생산 라인을 경쟁하기 때문에, AI 인프라 투자가 늘수록 소비자 디바이스의 RAM 확장은 역설적으로 어려워지는 구조입니다.
트릴레마의 핵심: 세 축이 서로를 강화한다
세 사례를 겹쳐보면 패턴이 보입니다. Amazon 가격 예측 시스템은 83% 정확도를 위해 하루 60만 건 스크래핑, MongoDB 시계열 스토리지, AWS Lambda 인프라를 운용합니다—정확도는 인프라 비용의 함수입니다. LLM 라우팅은 이 비용 문제를 분류기 레이어 하나로 공략하지만, 분류기 자체가 새로운 모델 유지보수 부담이 됩니다—비용 최적화는 새로운 복잡도를 낳습니다. 온디바이스 AI는 클라우드 비용과 프라이버시 문제를 동시에 해결하려 하지만, 물리적 메모리 벽과 추론 속도 붕괴 앞에서 현재 기술로는 에이전트 수준의 작업을 감당할 수 없습니다—인프라를 엣지로 내리면 성능이 무너집니다.
시사점: 지금 ML 시스템을 설계하는 팀이 직시해야 할 것
프로덕션 환경 성능 검증을 먼저 하세요. 83%는 학습 데이터 기준 숫자일 가능성이 있습니다. 실제 운영 환경에서 데이터 드리프트가 발생했을 때 모델이 재학습 없이 얼마나 버티는지—모니터링 파이프라인과 재학습 트리거 기준이 정확도 숫자보다 더 중요합니다.
LLM 비용 라우팅은 즉시 도입 가능한 quick win입니다. 다만 분류기의 오분류 방향을 명확히 설정하고, 품질 손실 감지를 위한 샘플링 평가 루프를 병행해야 합니다. '제로 품질 손실'은 검증된 사실이 아니라 설계 목표입니다.
온디바이스 에이전트 AI에 2025~2026년 로드맵을 걸지 마세요. 32GB RAM이 보편화되고 DRAM 공급 제약이 해소되기 전까지, 에이전트 수준의 멀티스텝 추론은 클라우드 인퍼런스가 현실적 선택입니다. 슬라이딩 윈도우 어텐션이나 양자화 KV 캐시 같은 기법들은 완화책이지, 근본 해결책이 아닙니다.
전망: 트릴레마는 해소되는가?
단기적으로는 세 축의 긴장이 완화되기 어렵습니다. 오히려 프리미엄 모델 가격이 올라갈수록(GPT-5.2 Pro $94.50) 라우팅 전략의 경제적 가치는 커지고, 그 분류기의 정확도 유지를 위한 MLOps 부담도 함께 증가합니다. 온디바이스의 경우 아키텍처 혁신(Mamba, RWKV 계열 선형 복잡도 모델)이 KV 캐시 병목을 우회할 가능성은 있지만, 에이전트 수준 멀티홉 추론에서의 재현 성능은 아직 미지수입니다.
결국 ML 시스템 설계자에게 트릴레마는 풀어야 할 방정식이 아니라 관리해야 할 제약 조건입니다. 지금 가장 실용적인 접근은 명확합니다—클라우드에서 라우팅으로 비용을 통제하고, 피처 엔지니어링으로 정확도를 최대화하며, 온디바이스는 4K 토큰 이하의 단순 분류 작업에만 활용하는 것. 숫자가 인상적일수록 그 뒤에 어떤 제약이 숨어 있는지를 더 집요하게 물어야 합니다.