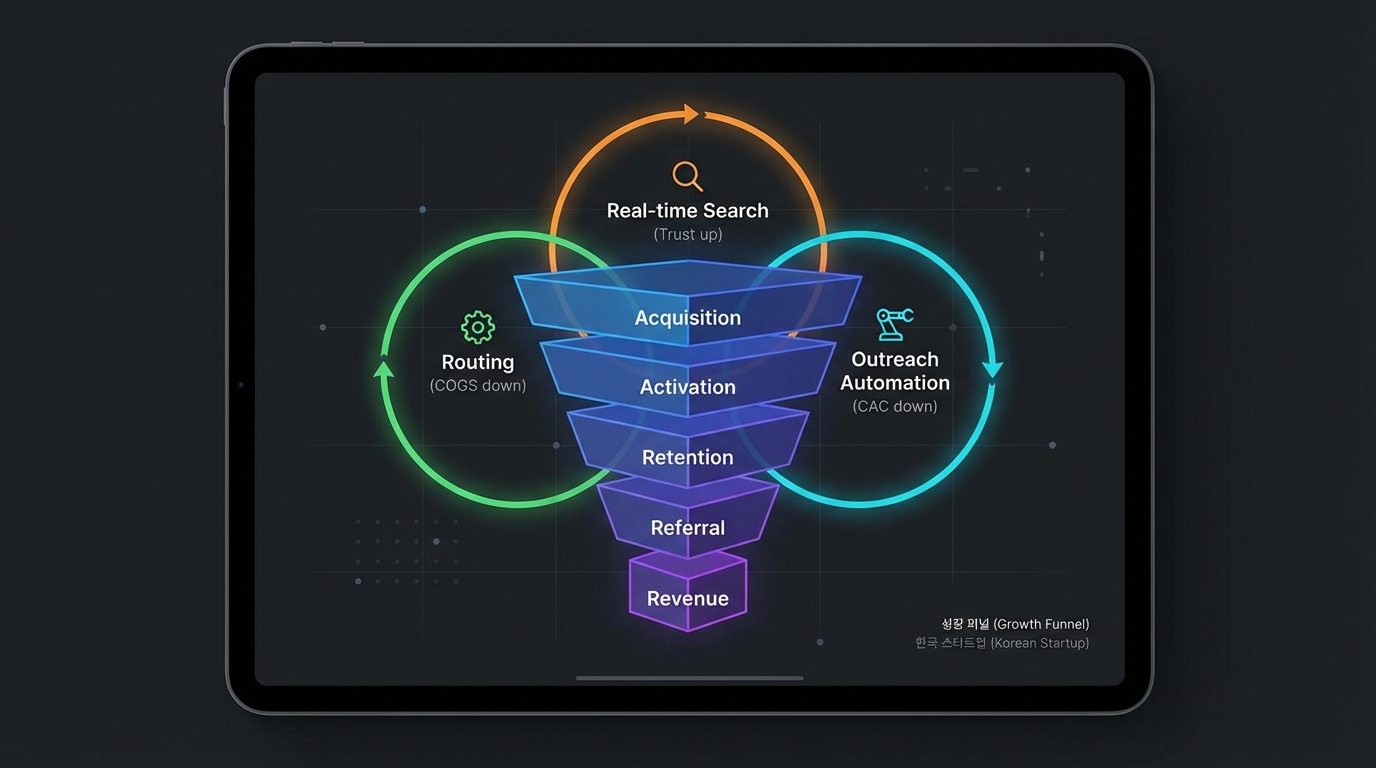
LLM 제품의 CAC가 왜 안 내려갈까요? 기능은 비슷해졌고 광고 단가는 오르는데, 유저는 “이 답 믿어도 돼?”에서 망설입니다. 이제 승부는 모델 점수보다 퍼널을 흔드는 운영 레버(비용·온보딩·신뢰)에서 납니다. 재밌는 건, 이 레버들이 서로 연결되면 CAC 절감 루프가 생긴다는 점이에요.
첫 번째 레버는 COGS(추론 비용) 절감 → 가격/프리티어 확장입니다. dev.to의 NadirClaw는 오픈소스 LLM 라우터로, 프롬프트를 “단순/복잡”으로 분류해 저가 모델과 고급 모델로 자동 라우팅해서 API 비용을 40~70%까지 낮춘다고 주장합니다. 중요한 포인트는 ‘제로 코드 변경’과 OpenAI 호환 프록시라는 점. 즉, 비용 최적화가 엔지니어링 대공사가 아니라 실험 가능한 그로스 레버가 됩니다.
이거 바이럴 될 것 같은데? 비용이 내려가면 곧바로 할 수 있는 실험이 열립니다. 예를 들어 Free tier를 키우거나(Activation↑), 체험 기간을 늘리거나, 팀 플랜에 seat를 더 얹는 식으로 초기 마찰을 줄일 수 있어요. 비용을 절감한 만큼 획득 채널을 확장해도 손익이 덜 망가지니, CAC 상한선이 올라가며 퍼널 상단 실험 폭이 커집니다.
두 번째 레버는 신뢰(Trust) → 전환율(CVR) 상승입니다. 또 다른 dev.to 글에서 MIAPI는 실시간 웹 검색으로 근거를 붙인 답변을 제공하고, 인용(citation)까지 포함한 “grounded answer”를 전면에 둡니다. 핵심은 할루시네이션을 기술적으로 줄이는 게 아니라, 유저가 결제 직전에 묻는 질문—“이거 출처 있어?”—를 제품 경험으로 해결한다는 것. 전환율이 0.5%p만 올라가도 CAC는 체감상 다른 세상이 됩니다.
세 번째 레버는 아웃바운드의 자동화 → 채널 CAC 절감입니다. 인플루언서 아웃리치를 Node.js 파이프라인으로 자동화해 리드를 수집하고(해시태그 기반), 이메일을 추출하고(Regex), CSV로 내보내 콜드메일 툴에 붙이는 방식이 소개됩니다(dev.to). 여기서 포인트는 “마케팅 인력 시간”이 가장 큰 숨은 CAC라는 점. 리스트업과 리치아웃을 자동화하면, 같은 예산으로 접촉 수를 늘리고 개인화 품질도 올릴 수 있어요.
세 레버를 합치면 루프가 됩니다. (1) 라우팅으로 COGS↓ → 더 공격적인 체험/온보딩 제공 → Activation↑, (2) 실시간 검색+인용으로 신뢰↑ → CVR↑, (3) 아웃리치 자동화로 접촉 단가↓ → 상단 유입↑. 여기서 끝이 아니라, 비용이 줄어든 만큼 “근거 검색” 같은 신뢰 기능에 재투자해도 마진이 방어되고, 신뢰가 올라가면 추천/공유가 늘어 바이럴 계수도 건드릴 여지가 생깁니다. 빨리 테스트해봐야 돼요.
시사점은 명확합니다. AARRR 관점에서 보면 라우팅은 Revenue(마진)와 Retention(품질 유지하면서 응답 속도/비용 안정)에, 검색 기반 근거는 Activation/Revenue(CVR)에, 아웃리치 자동화는 Acquisition(CAC)에 직결됩니다. 즉, “모델 고도화”처럼 긴 개발 사이클이 아니라, 1~2주 단위 실험으로도 KPI를 흔들 수 있는 조합이에요.
전망은 더 흥미롭습니다. LLM 시대엔 콘텐츠/트래픽의 보상 구조가 흔들리고(LLM이 답을 가져가 클릭이 줄어드는 문제를 dev.to의 ‘Dual-version web’ 글이 지적), 결국 제품은 직접 획득 채널과 신뢰 프로토콜을 더 강하게 내장해야 합니다. 그래서 앞으로의 AI 제품 팀은 “모델 선택”보다 라우팅·근거·아웃리치·계측을 하나의 운영 시스템으로 묶는 팀이 더 빠르게 스케일할 가능성이 큽니다. CAC가 너무 높다면, 성능 튜닝보다 먼저 이 루프부터 붙여보는 게 정답에 가깝습니다.