'AI 도입 후 성능 XX% 향상.' 요즘 개발 블로그와 제품 랜딩 페이지에서 흔히 보이는 문장입니다. 그런데 그 숫자, 실험 설계는 제대로 됐을까요? 베이스라인은 무엇이었고, 샘플 사이즈는 충분했나요? 최근 dev.to에 올라온 두 편의 실험 보고서가 이 질문에 꽤 솔직한 답을 내놓고 있습니다. 하나는 LLM 기반 코드 분석을 정적 분석으로 교체한 사례, 다른 하나는 AI 에이전트용 MCP 도구를 도입했더니 오히려 역효과가 난 사례입니다.
LLM 보안 스캐너의 치명적 결함: 재현 불가능성
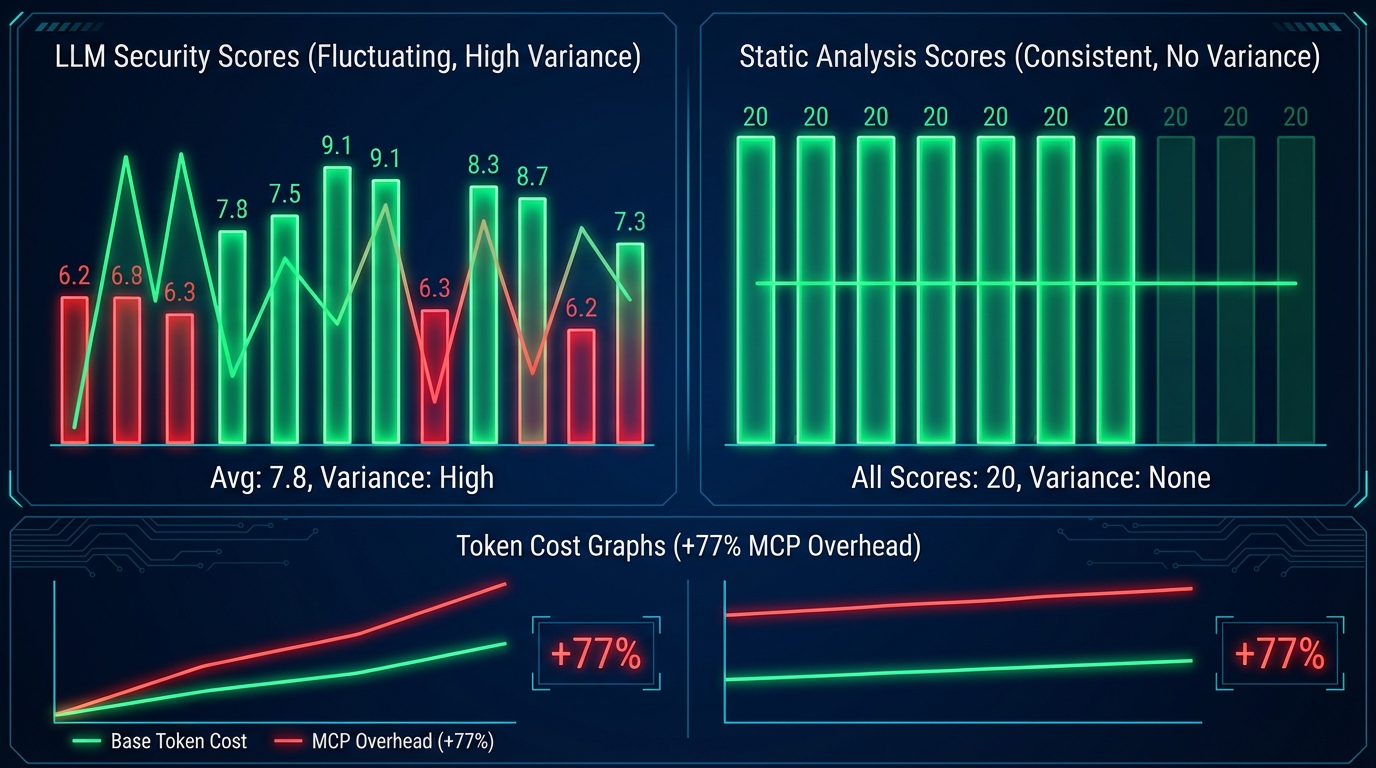
dev.to의 한 개발자(ayame0328)는 AI 생성 코드용 보안 스캐너를 LLM으로 구현했다가 전면 교체한 과정을 공유했습니다. 핵심 문제는 재현 불가능성(reproducibility) 이었습니다. eval(user_input)이라는 동일한 입력을 5회 반복 실행했을 때 심각도 점수는 6.2에서 9.1 사이를 오갔습니다. 이건 보안 도구가 아니라 '의견이 달린 난수 생성기'입니다.
더 체계적인 실험에서는 20개 코드 샘플을 각 5회씩 스캔한 결과, 평균 편차 ±1.8점(10점 척도), 동일 취약점에 대한 카테고리 불일치율 23%, 그리고 특정 실행에서만 SQL 인젝션을 놓치는 간헐적 false negative까지 확인됐습니다. ML 분석가 관점에서 보면 이건 단순한 성능 문제가 아닙니다. 모델의 variance가 너무 높아 confidence interval 자체를 신뢰할 수 없는 상태입니다. ROC-AUC나 F1-score를 계산하기도 전에 측정 도구 자체가 불안정한 것이죠.
정적 분석으로의 전환: 숫자는 명확했다
교체 후 결과는 이렇습니다. 일관성은 ~77%에서 100%로, 스캔 속도는 3~8초에서 15~50ms로(약 200배 향상), 비용은 스캔당 $0.002~0.01에서 $0.00으로, false positive율은 ~12%에서 ~5%로, false negative율은 ~8%에서 ~3%로 개선됐습니다. 93개의 명시적 규칙 기반으로 14개 취약점 카테고리를 커버합니다.
여기서 '근거는 있나요?'라는 질문을 던져야 합니다. 샘플 사이즈가 20개 코드 샘플, 5회 반복이라는 점은 다소 제한적입니다. 3개월 운영 데이터라고 했지만 테스트 셋의 대표성(representativeness)이 명시되지 않았습니다. 그럼에도 불구하고 이 실험의 핵심 주장—결정론적 시스템이 보안 스캐닝에서는 확률론적 LLM보다 구조적으로 우월하다—은 설득력이 있습니다. 이건 correlation이 아니라 시스템 설계의 인과적 차이입니다.
MCP 도입의 역설: +77% 비용, +47% 시간
두 번째 실험은 반대 방향의 교훈을 줍니다. SpecLeft 프로젝트의 개발자(dimwiddle)는 AI 에이전트의 코딩 워크플로우를 개선하기 위해 MCP(Model Context Protocol) 서버를 구현했습니다. 스펙 기반 TDD 워크플로우를 에이전트에게 제공해 반복 횟수를 줄이겠다는 의도였습니다.
실측 결과는 냉혹했습니다. MCP 미적용 대비 총 토큰 사용량 +77% (4.88M → 8.64M), 소요 시간 +47% (30분 → 44분), 컨텍스트 윈도우 점유율 35% → 62%로 거의 두 배 상승. 비용-성능 trade-off 관점에서 보면 현재 상태의 SpecLeft MCP는 negative ROI입니다. 단, output 토큰이 21% 감소한 점은 주목할 만합니다. 에이전트가 스펙 컨텍스트를 받았을 때 덜 장황하게, 더 목표 지향적으로 응답했다는 신호입니다. ablation study 관점에서 보면 'MCP 오버헤드'와 'spec-driven 워크플로우 효과'가 혼재하고 있어, MCP 없이 SKILL.md와 CLI만 사용하는 조건을 별도로 실험해야 진짜 원인을 분리할 수 있습니다.
두 실험이 공유하는 교훈
두 사례 모두 도구 도입 전 명확한 베이스라인 설정의 중요성을 보여줍니다. LLM 스캐너 실험은 베이스라인(일관성 77%, false positive 12%)을 수치화했기에 개선 폭을 정확히 말할 수 있었습니다. SpecLeft 실험은 'Without MCP' 조건을 대조군으로 삼아 오버헤드를 정량화했습니다. 두 실험 모두 '인상적으로 들리는 숫자'가 아니라 '불편한 진실을 드러내는 숫자'를 선택했다는 점에서 신뢰도가 높습니다.
시사점: 'AI 도입'은 가설이고, 측정이 검증이다
AI 도구 도입을 고려하는 팀이라면 이 두 실험에서 실험 설계 템플릿을 가져갈 수 있습니다. 첫째, 재현 가능성 테스트를 먼저 하세요. 동일 입력에 대해 N회 실행했을 때 분산이 허용 가능한 수준인지 확인해야 합니다. 보안처럼 결정론성이 필수인 도메인에서 LLM의 확률론적 특성은 버그가 아니라 설계 결함입니다. 둘째, cost-performance 곡선을 그리세요. MCP 사례에서처럼 '기능이 개선되었는가'와 '그 개선이 오버헤드를 정당화하는가'는 별개의 질문입니다. 개발자 스스로 목표를 '≤+10% 입력 토큰'으로 수치화한 것은 올바른 접근입니다. 측정 가능한 목표만이 달성 가능한 목표입니다.
전망: 'AI 파워드' 마케팅의 역풍이 온다
정적 분석 사례의 저자가 지적한 '불편한 산업의 진실'은 더 넓게 적용됩니다. 많은 제품이 'AI 파워드'를 USP로 내세우지만, 실제 운영 환경에서 determinism, latency, cost 세 가지 제약 조건을 동시에 만족시키는 LLM 기반 솔루션은 생각보다 드뭅니다. 앞으로 성숙한 사용자들은 'AI 도입 전후 수치'를 요구할 것이고, 그 숫자가 어떤 실험 조건에서 나왔는지 물을 것입니다. 그 질문에 답할 준비가 된 팀만이 신뢰를 유지할 수 있습니다. 지금 당신의 팀에서 쓰고 있는 AI 도구—베이스라인 대비 얼마나 개선됐는지, 측정해 보셨나요?