AI 앱 시장에서 제일 무서운 건 ‘기술 격차’가 아니라 ‘신뢰 붕괴→집단 이탈’입니다. 최근 이 흐름이 한 번에 모였습니다. OpenAI가 미 국방부(펜타곤) 계약을 수주한 뒤 ChatGPT 삭제율이 전일 대비 295% 급등, 다운로드도 연속 하락했다는 보도(AI넷)는 “브랜드 파워가 있어도 윤리 포지셔닝 한 방에 리텐션이 꺾인다”는 걸 보여줍니다.
흥미로운 건 반사이익이 즉시 경쟁으로 전이됐다는 점입니다. Anthropic이 계약을 거절하며 감시·무기화 우려를 공개적으로 선을 긋자, Claude 다운로드가 미국에서 이틀 연속 폭증(37%→51%)했고 앱스토어 1위를 찍었습니다(AI넷). 이거 바이럴 될 것 같은데? ‘정치/윤리 이슈’는 논쟁을 부르지만, 동시에 스위칭 트리거를 만들어 냅니다. 즉, CAC를 낮추는 “이벤트성 유입”이 생기고, 그 다음은 온보딩이 아니라 ‘신뢰 확인’이 Activation을 좌우합니다.
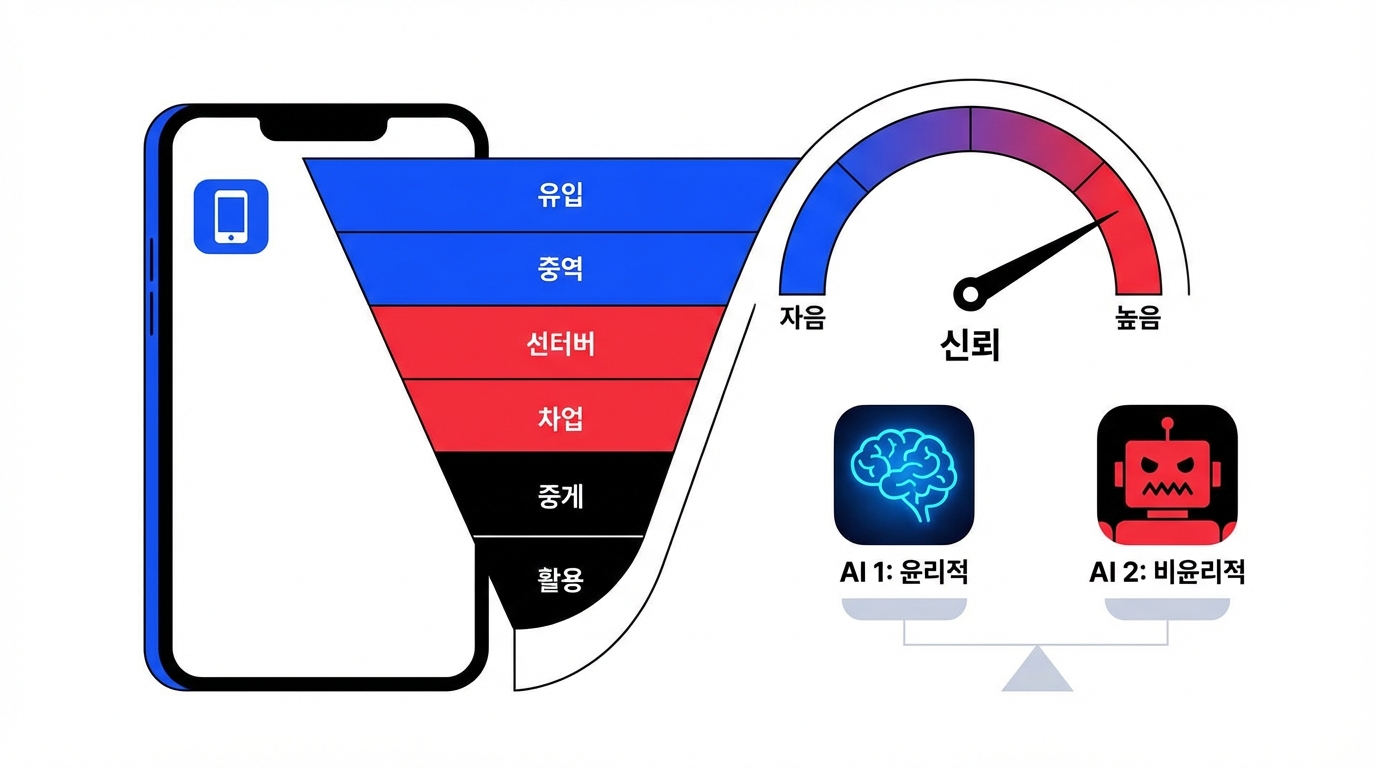
여기에 두 번째 축: “정직성(할루시네이션)”이 제품 선택을 가르는 기준으로 굳어지고 있습니다. dev.to의 BullshitBench v2 분석은, 추론을 많이 돌릴수록 오히려 헛소리를 더 그럴듯하게 합리화하는 ‘Reasoning Paradox’를 지적합니다. 특히 Claude 4.6 Sonnet이 거짓 탐지 91%, “확신하고 틀리는 비율” 3%로 상위권을 독주한다는 데이터는(벤치마크 자체의 한계는 감안하더라도) 시장이 ‘도움됨(helpfulness)’에서 ‘거절/검증/겸손(honesty)’으로 KPI를 바꾸고 있음을 시사합니다. Conversion rate가 얼마나 오를까요? 고위험(법률/의료/금융) 세그먼트에선 “정답률”보다 “확신 오류 감소”가 환불·이탈을 더 직접 줄입니다.
하지만 신뢰는 모델 출력만의 문제가 아닙니다. GeekNews에선 Claude Desktop의 Cowork 기능이 macOS에서 경고 없이 10GB VM 번들을 만들고 성능 저하를 유발했다는 불만이 커졌습니다. 여기서 유저가 느끼는 배신감 포인트는 ‘VM이 무겁다’가 아니라 ‘고지 없이 자원을 쓴다/삭제해도 다시 생긴다’는 투명성 결함입니다. 유저가 여기서 이탈할 것 같은데… 이건 기능 QA 이슈가 아니라 “권한·리소스·데이터 사용에 대한 신뢰”를 깎아 D30을 흔드는 타입의 사건입니다.
정리하면, AI 앱 리텐션을 좌우하는 신뢰는 3층 구조로 굳어집니다. (1) 윤리 포지셔닝(누구와 계약/무엇에 쓰나), (2) 출력 정직성(모르면 모른다/근거 제시), (3) 제품 투명성(리소스·권한·데이터 사용 고지). 셋 중 하나라도 무너지면, “삭제 운동” 같은 네트워크 효과가 역방향 바이럴로 번지고 CAC가 폭증합니다.
시사점은 실행 프레임으로 떨어집니다. 빨리 테스트해봐야 돼! - Trust Onboarding A/B: 첫 실행에 ‘사용 목적/제약/거절 원칙/데이터 사용/로컬 리소스’ 5줄을 명시하고, (A) 짧게 vs (B) 상세하게 vs (C) 선택형(토글)로 나눠 D1/D7 차이를 보세요. - Honesty UX 실험: “근거 링크/인용”, “불확실도 배지”, “대안 질문 리프레이밍”을 넣고 ‘재질문율’과 ‘세션 길이’가 아니라 환각 신고율·취소율·재방문율로 평가해야 합니다. - 투명성 알림의 타이밍: Cowork 사례처럼 리소스가 큰 기능은 설치/첫 실행/기능 활성화 중 어디에서 고지해야 이탈이 최소인지 실험 가능합니다(고지=마찰이 아니라 신뢰=리텐션이라는 가설).
전망: 2026년 AI 경쟁은 “더 똑똑함”이 아니라 “더 믿을 만함”으로 이동 중입니다. 윤리 논란은 한 번 터지면 회복이 느리고, 할루시네이션은 ‘1회 사고’가 B2B 확장(보안/컴플라이언스)을 막습니다. 반대로 신뢰를 정교하게 설계한 팀은, 역바이럴(추천/대체재 이동)을 타고 CAC를 낮추며 리텐션을 잠글 수 있습니다. 결국 승부처는 모델이 아니라 신뢰 프로토콜을 제품화하는 속도입니다.