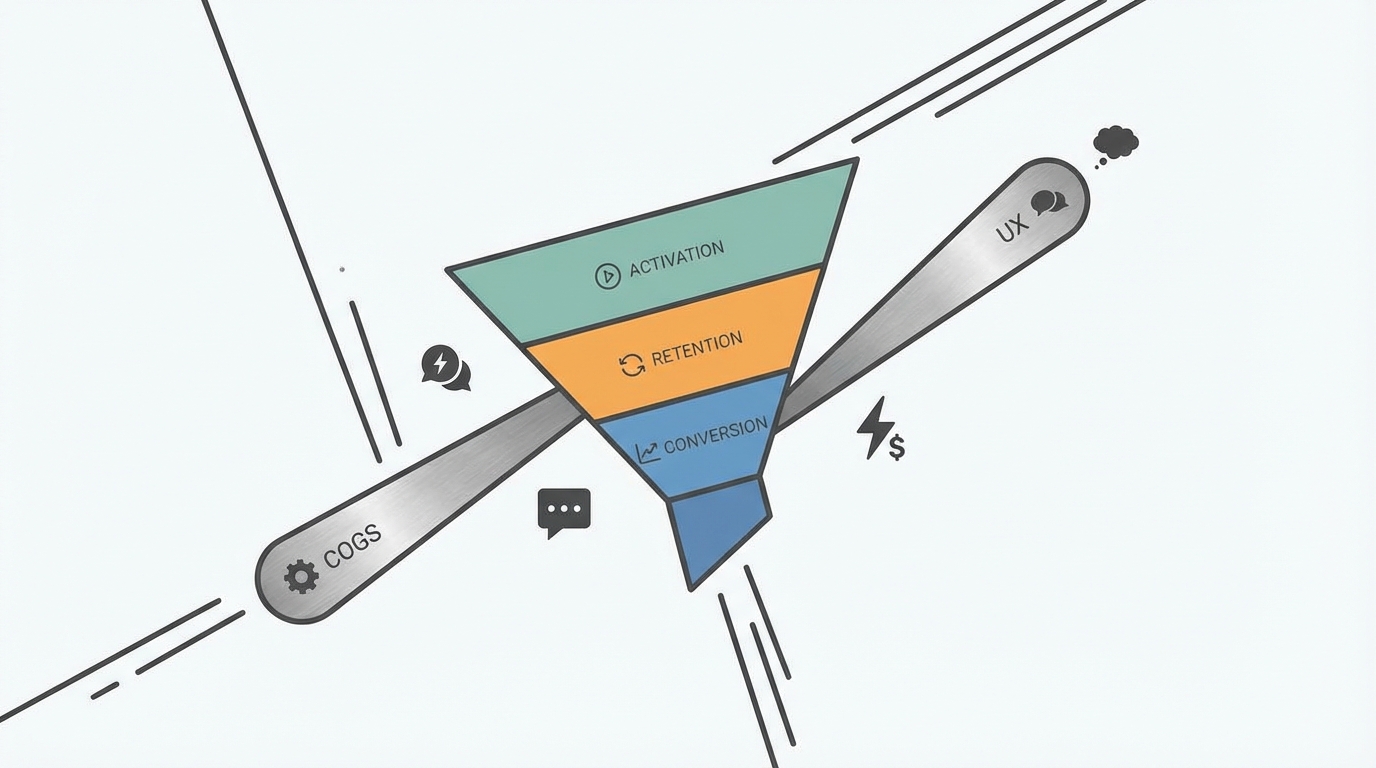
LLM 성능이 상향평준화된 지금, 승부는 더 이상 “벤치마크 1점”이 아닙니다. 진짜는 COGS(토큰 비용)와 UX(대화/검색/속도)가 Activation·Retention·Conversion을 얼마나 끌어올리느냐예요. OpenAI가 GPT-5.3 Instant에서 ‘말투(크린지)·관련성·대화 흐름’을 손본 것(AI타임즈·AI매터스 보도)과, 구글이 Gemini 3.1 Flash-Lite를 ‘초저가·초고속’으로 밀어붙인 것(토큰포스트·디지털투데이 보도)은 같은 방향을 가리킵니다: 퍼널 지표를 움직이는 운영 레버요.
먼저 GPT-5.3 Instant. 이번 업데이트의 핵심은 “더 똑똑해졌다”가 아니라, 유저가 덜 답답해졌다입니다. 웹 검색 결과를 더 맥락 있게 엮고, 질문 의도를 더 빨리 파악해 답변 초반에 핵심을 먼저 주는 구조, 그리고 불필요한 거절/훈계성 톤을 줄인 변화가 포인트죠. 특히 환각 감소 수치(웹 사용 시·미사용 시 각각 감소)도 있지만, 성장 관점에서는 이게 곧 첫 사용 성공률(Activation)과 연결됩니다. 유저가 처음 30초 안에 “아 이거 쓸만하네”를 느끼는 순간이 늘어나니까요.
반대로 Gemini 3.1 Flash-Lite는 완전히 다른 칼을 들고 왔습니다. 입력 100만 토큰 $0.25, 출력 100만 토큰 $1.50 같은 파격 가격과, 첫 토큰 대기시간 단축/전체 생성 속도 개선을 전면에 둔 포지셔닝이죠. 이거, 한 마디로 “대량 트래픽을 감당할 수 있는 단가 구조를 깔아준다”는 뜻입니다. 와 이거다! 스타트업 입장에서 무료 구간을 넓히거나(Activation 확대), 온보딩/체험을 더 공격적으로 열어(CAC↓), 내부 자동화까지 확장해(ARPU↑) 볼 수 있는 판이 열립니다.
여기서 맥락 해석이 중요합니다. GPT-5.3의 UX 개선은 전환을 막던 마찰(Friction) 제거이고, Flash-Lite의 초저가는 실험의 표본을 키우는 비용 구조입니다. 전자는 “유저가 여기서 이탈할 것 같은데…”를 줄여주는 개선이고, 후자는 “빨리 테스트해봐야 돼!”를 가능하게 만드는 인프라예요. 결국 둘 다 퍼널을 위로 미는 힘으로 수렴합니다.
시사점은 명확합니다. 이제 제품팀/그로스팀이 해야 할 일은 ‘최강 모델 올인’이 아니라 모델 라우팅+UX 게이팅+가격 설계를 묶어 실험하는 겁니다. 예를 들면: - 온보딩 3턴은 Flash-Lite(저가·고속)로: 대기시간을 줄여 Activation을 올리고, 핵심 작업에서만 상위 모델로 업그레이드 - 검색 기반 질문만 GPT-5.3(검색 UX·관련성)로: “답을 바로 쓸 수 있다” 체감을 주는 순간에 비용을 쓰기 - 요약/분류/번역은 Lite로 대량 처리하고, 고위험(법률/금융)이나 설득형 카피만 고급 모델로 스위치 이거 바이럴 될 것 같은데? 특히 B2C에서는 ‘빠르고 덜 짜증나는 기본 경험’이 공유를 부르고, 공유는 CAC를 깎습니다.
가격도 단순 구독이 아니라 퍼널형으로 바꿔야 합니다. “Pro로 업셀” 이전에, 유저가 체감하는 단위(속도, 길이, 검색, 정확도, 말투/형식)로 과금 레이어를 나누면 전환율이 더 잘 나옵니다. 예: ‘초고속 답변(기본) + 근거 검색(애드온) + 전문가 모드(프리미엄)’. Conversion rate가 얼마나 오를까요? 최소한 무료→유료 전환의 트리거가 ‘모델 이름’에서 ‘혜택 체감’으로 이동합니다.
전망은 더 선명합니다. LLM은 앞으로도 계속 좋아지겠지만, 시장이 보상하는 건 “모델 성능”이 아니라 운영 가능한 단가와, 유저가 즉시 만족하는 UX가 될 겁니다. GPT-5.3의 톤/검색 개선은 ‘답변 품질’이 아니라 대화 경험 자체가 제품이라는 선언이고, Flash-Lite의 초저가·고속은 LLM을 기능이 아니라 단가 경쟁 가능한 인프라로 바꾸는 신호예요. 다음 분기 그로스 과제는 하나입니다: 라우팅 규칙을 세우고, 퍼널별 KPI(D1/D7·전환·COGS)를 붙여 2주 단위로 실험하세요. 성능은 이미 평균 이상입니다. 이제는 COGS·UX로 퍼널을 올리는 팀이 이깁니다.