RAG는 원래 할루시네이션을 줄이려고 붙였습니다. 그런데 스케일 단계에서 ‘조용히’ 품질이 붕괴하면(semantic collapse) 더 위험해요. 유저는 답을 받긴 받습니다. 다만 틀린 근거가 섞인 “그럴듯한 답”을 받죠. 이 순간 Activation(첫 성공 경험)이 깨지고, D7/D30 리텐션은 신뢰 이슈로 바로 무너집니다. 비용은? 컨텍스트를 더 넣을수록 토큰이 늘어 COGS가 폭증합니다.
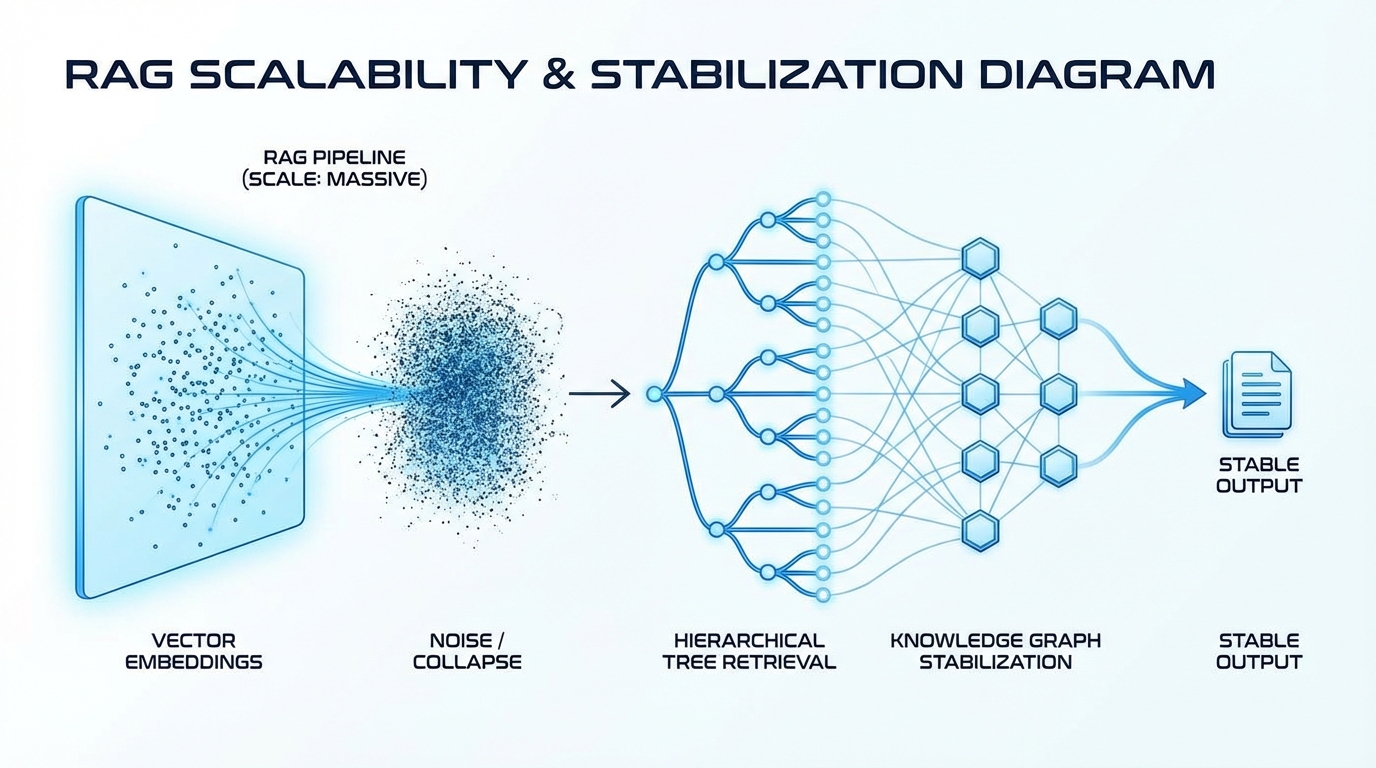
dev.to에서 소개된 Stanford 연구 요지는 냉정합니다. 임베딩 벡터가 고차원으로 갈수록 점들이 “다 비슷해지는” 기하학적 현상(차원의 저주) 때문에, 문서 수가 커질수록 코사인 유사도가 구분력을 잃습니다. 결과적으로 50K+에서 검색 정밀도가 크게 떨어지고, 심지어 키워드 검색보다 못해질 수 있다는 경고가 나왔죠(Stanford 연구 인용, dev.to 정리). 여기서 핵심은 “모델이 나빠서”가 아니라 “구조적으로 이렇게 된다”는 점입니다.
성장 관점으로 번역하면 이겁니다: (1) 검색 실패 → 첫 답변 성공률 하락 → 온보딩 완료율/Activation 감소, (2) 틀린 근거로 인한 재질문·클레임 증가 → 세션당 턴 수 증가 → 토큰/지연 상승 → COGS↑, (3) 신뢰 붕괴 → 재방문 감소 → 리텐션↓, (4) 엔터프라이즈면 “감사/컴플라이언스 리스크”까지 붙어 확장(Scale) 자체가 막힙니다. ‘품질 문제’가 아니라 AARRR 퍼널 전체를 때리는 성장 리스크예요.
그럼 뭘 해야 하냐. Stanford 정리 글(dev.to)은 “평면(Flat) 벡터스토어”에서 빠져나오라고 합니다. 첫 번째 레버는 계층형 검색(Hierarchical Retrieval). 문서 전체를 한 번에 50K와 비교하지 말고, 챕터→섹션→문단처럼 압축 요약을 계층으로 만들어 검색 공간을 단계적으로 줄입니다. 이건 성장팀이 좋아하는 구조예요. ‘탐색 공간’을 줄이는 만큼 (a) 정답률이 올라 Activation이 좋아지고, (b) 불필요한 컨텍스트가 줄어 토큰이 내려가 COGS가 줄고, (c) 답변 일관성이 올라 리텐션이 방어됩니다. “와 이거다!” 싶은, 품질과 비용을 동시에 잡는 레버죠.
두 번째 레버는 그래프 기반 RAG(Graph RAG). 문서 조각을 노드로, 관계를 엣지로 모델링해 “유사도” 대신 “관계 탐색”으로 답을 찾는 방식입니다. 국내 기사에서도 SKAI가 온톨로지/그래프RAG를 공공 AX 데이터 인프라에 적용한다고 언급되는데(서울와이어), 이 흐름이 괜히 나오는 게 아닙니다. 규정·업무·도메인 지식은 ‘관계’가 핵심이라, 스케일이 커질수록 그래프가 오히려 강해져요. 다만 구축 난이도가 높으니, 우선순위는 “고위험/고가치 질문군”부터 그래프화해서 점진 확대가 현실적입니다.
세 번째 레버는 토큰·비용 모니터링을 제품 루프로 올리는 것입니다. dev.to의 다른 글은 디버깅 한 번에 토큰 $27을 태운 사례를 보여줍니다. 이거, 개발자만의 문제가 아니에요. 에이전트가 루프를 돌거나, RAG가 근거를 많이 붙이기 시작하면 “정답률은 안 오르는데 비용만 오르는” 구간이 생깁니다. 그래서 최소한 (1) 요청당 토큰, (2) 세션당 토큰, (3) 답변당 근거 수, (4) retrieval top-k 분포, (5) 재질문율(같은 의도 반복)을 실시간으로 대시보드화해야 합니다. “Conversion rate가 얼마나 오를까요?”를 보기 전에 “COGS가 얼마에 고정되나요?”부터 답이 나와야 스케일이 됩니다.
네 번째 레버는 서버리스 폴백(cheap-first, expensive-fallback) 전략입니다. warrantyAI 사례(dev.to)는 Bedrock를 Lambda로 호출하고, 빠르고 저렴한 모델(Haiku)로 1차 처리 후 신뢰도 낮을 때만 고성능 모델(Sonnet)로 재시도합니다. 이 패턴을 RAG에도 그대로 가져오면 좋아요. 예: (a) 저비용 모델로 ‘질문 분류/라우팅’ → (b) 위험도 높으면 계층 검색+리랭킹까지, 낮으면 간단 검색만 → (c) 답변 품질 점수가 임계치 아래면 고성능 모델로 재생성. “CAC가 너무 높아요”가 아니라 “COGS가 너무 높아요”를 먼저 해결하는 성장 해킹입니다.
즉시 실행 가능한 실험 체크리스트로 마무리하겠습니다. 1) 문서 수를 2배로 늘린 시뮬레이션에서 retrieval precision(또는 human eval)을 측정하세요(Stanford 정리 글이 강조). 2) top-k를 무작정 키우지 말고 ‘계층/그래프’로 후보군을 줄이세요. 3) 토큰을 개발·운영 모두에서 실시간 가시화해, 세션당 비용 상한(guardrail)을 걸어두세요. 4) serverless + 폴백 라우팅으로 “항상 최고 모델”을 버리고, 품질 임계치 기반으로 비용을 쓰세요.
전망은 명확합니다. RAG는 끝나지 않았습니다. 다만 “벡터스토어 하나 붙이면 무한 확장”이라는 환상이 끝났을 뿐이에요. 앞으로의 스케일 전략은 (1) 검색 구조(계층/그래프)로 품질을 방어하고, (2) 토큰/지연을 운영 메트릭으로 끌어올려 COGS를 통제하고, (3) cheap-first 라우팅으로 마진을 지키는 팀이 이깁니다. 빨리 테스트해봐야 돼요. 스케일 붕괴는 ‘언젠가’가 아니라, 문서 10K 넘는 순간 이미 시작됐을 수 있으니까요.