엔지니어 75%가 AI 코딩 도구를 매일 쓴다. 그런데 대부분의 조직은 측정 가능한 생산성 향상을 보지 못한다. Faros AI가 이 역설을 한 문장으로 정리했다. "영리한 프롬프트는 인상적인 데모를 만들고, 엔지니어링된 컨텍스트는 출시 가능한 소프트웨어를 만든다." 도구를 쓰는 것과 도구를 제대로 심는 것은 다른 문제다.
프롬프트 엔지니어링의 시대는 끝났다
'컨텍스트 엔지니어링'이라는 말이 '프롬프트 엔지니어링'을 빠르게 대체하고 있다. Martin Fowler는 이를 "모델이 보는 것을 큐레이션해서 더 나은 결과를 얻는 것"이라고 정의한다. 프롬프트 엔지니어링이 일회성 행위라면, 컨텍스트 엔지니어링은 시스템이다. AI 에이전트가 접근할 수 있는 정보 환경 전체—프로젝트 컨벤션, 아키텍처 패턴, 팀 표준, 툴 정의, 문서—를 인프라처럼 설계하는 작업이다.
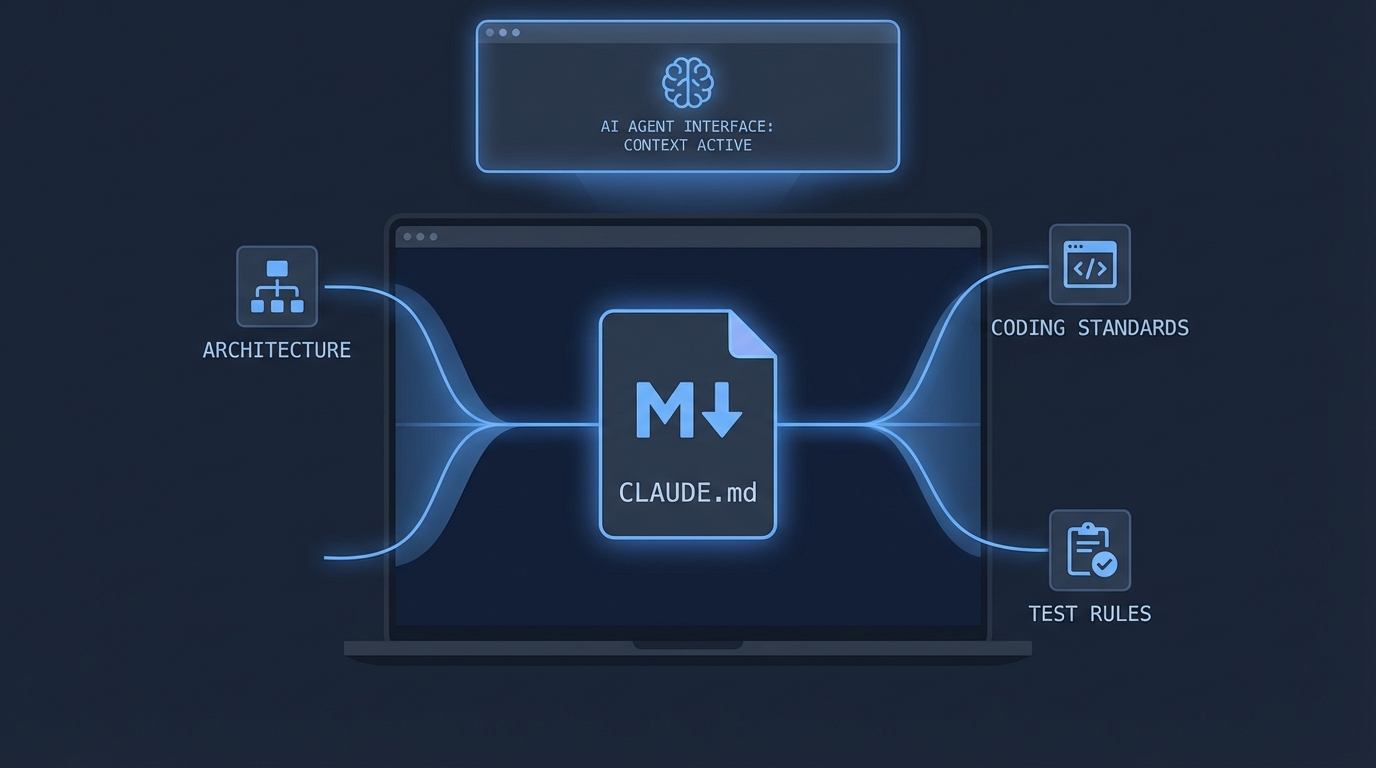
이 공간을 지배하는 도구가 바로 CLAUDE.md다. Claude Code 사용자라면 프로젝트 루트에 이 파일 하나를 두는 것으로 모든 세션이 프로젝트 맥락을 자동으로 주입받는다. Cursor 사용자라면 .cursor/rules/ 안의 .mdc 파일들이 같은 역할을 한다. 둘 다 핵심 아이디어는 동일하다: 한 번 설정하면 이후 모든 세션이 이를 상속한다.
CLAUDE.md, 실제로 어떻게 구성하나
dev.to의 실전 가이드(Context Engineering: CLAUDE.md and .cursorrules)에서 제안하는 구조는 간결하다. 다섯 섹션, 각 15줄 이하, 전체 500토큰(약 400단어) 이내.
- 프로젝트 정체성 — 이름, 목적, 기술 스택 세 줄
- 아키텍처 컨벤션 — 어디에 뭐가 있는지 한 단락
- 코딩 표준 — 린터가 못 잡는 것들: 네이밍, 타입 규칙, 선호·기피 패턴
- 손대지 말아야 할 영역 — 마이그레이션 파일, 생성 코드, 벤더 라이브러리
- 테스트 요구사항 — 어떤 테스트를, 어떤 명령으로, 언제 실행할지
특히 4번 섹션이 중요하다. 에이전트가 prisma/migrations/나 src/generated/ 같은 파일을 지시 없이 건드리는 사고는 이 한 섹션으로 대부분 막힌다. 이 섹션 하나가 가장 값비싼 에이전트 오류를 방지한다는 게 실전 경험의 공통된 결론이다.
한 가지 반직관적인 사실이 있다. Stanford·UC Berkeley 연구에 따르면 모델 정확도는 32,000토큰 부근에서 떨어지기 시작한다—모델이 광고하는 컨텍스트 윈도우 크기와 무관하게. '잃어버린 중간(lost-in-the-middle)' 효과다. CLAUDE.md를 500토큰 이하로 유지해야 하는 이유가 여기 있다. 컨텍스트 품질은 컨텍스트 양과 비례하지 않는다. 정밀도가 볼륨을 이긴다.
컨텍스트 순서도 중요하다. 모델은 컨텍스트 윈도우의 앞과 뒤에 더 주목한다. 핵심 제약사항은 상단에, 즉각적인 태스크 컨텍스트와 예시는 하단에 배치해야 한다. 3,000토큰짜리 CLAUDE.md 중간에 묻혀 있는 중요 지시사항은 에이전트에게 무시당한다.
CLAUDE.md를 AI OS의 기반으로 확장하기
Claude Code는 CLAUDE.md 하나로 끝나지 않는다. 실제로는 네 가지 컨텍스트 메커니즘이 층위별로 작동한다.
- CLAUDE.md — 항상 로드, 프로젝트 전체 컨벤션
- Rules — 경로 스코프 지침 (
*.test.ts에만 적용되는 규칙 등) - Skills — 태스크가 매칭될 때 에이전트가 트리거하는 지연 로드 리소스
- Hooks — 파일 저장이나 커밋 같은 라이프사이클 이벤트에 실행되는 결정론적 스크립트
dev.to의 또 다른 실전 글(Claude Code to AI OS Blueprint)은 이 구조를 'AI 운영체제'로 확장하는 청사진을 제시한다. Skills로 반복 작업을 자동 트리거하고, Hooks로 배포 완료 시 Telegram 알림을 보내고, MCP 서버로 GitHub·Postgres·Notion을 에이전트에 직접 연결한다. CLAUDE.md는 이 전체 시스템의 부팅 이미지—가장 먼저 로드되고 모든 것의 맥락이 되는 핵심이다.
컨텍스트 엔지니어링이 해결 못하는 것
여기서 냉정하게 짚어야 할 부분이 있다. 컨텍스트 엔지니어링은 신뢰성을 높이지, 결과를 보장하지 않는다. Martin Fowler가 명시했듯 결과는 여전히 LLM 해석에 달려 있고, 확률론적 사고가 필요하다. 인간 리뷰는 컨텍스트 품질과 무관하게 필수다.
Cognitive Debt 연구(Cognitive Debt: The Real Cost of AI-Generated Code)가 지적하는 문제가 이 지점과 교차한다. AI 코딩 도구에 대한 개발자 신뢰도는 18개월 만에 43%에서 29%로 떨어졌지만 사용률은 84%로 올랐다. 코드는 빠르게 나오지만 그 코드를 이해하는 속도는 따라가지 못한다. 팀이 코드를 소유하는 게 아니라 코드가 팀을 소유하게 되는 역전 현상이다.
좋은 CLAUDE.md는 에이전트가 네이밍 컨벤션을 따르게 하고, 금지 영역을 건드리지 않게 막는다. 하지만 개발자가 커밋 전에 함수를 읽고, 설계 결정의 이유를 문서화하고, 직접 코딩하는 시간을 유지하는 것—그것은 CLAUDE.md가 대신할 수 없다.
시니어의 역할 재정의와 컨텍스트의 관계
'시니어 개발자의 정의가 무너지고 있다(The Old Seniority Definition Is Collapsing)'는 분석은 컨텍스트 엔지니어링의 맥락에서 다르게 읽힌다. AI가 1차 구현의 비용을 낮추면서 '빠르게 코드를 많이 쓰는 능력'은 더 이상 시니어의 신호가 되지 못한다. 대신 가치가 올라가는 것은 시스템의 컨텍스트를 구조화하는 능력이다.
CLAUDE.md를 잘 쓰는 사람은 누구인가? 프로젝트의 아키텍처 결정을 이해하고, 어떤 파일이 왜 손대면 안 되는지 알고, 테스트 전략의 의도를 설명할 수 있는 사람이다. 다시 말해 도메인과 시스템에 대한 깊은 맥락을 가진 사람이 좋은 컨텍스트 파일을 쓸 수 있다. 컨텍스트 엔지니어링은 결국 시스템 이해력의 외현화다.
팀 차원에서 실천하는 법
CLAUDE.md를 팀 워크플로우에 제대로 심으려면 몇 가지를 챙겨야 한다.
파일 유효성 유지: CLAUDE.md는 썩는다. Express 코드베이스 기준으로 작성된 파일이 Fastify 마이그레이션 후에도 남아 있으면 없는 것보다 나쁘다. PR 템플릿에 "CLAUDE.md 업데이트했나요?" 한 줄을 추가하는 데 10초가 걸린다. 그 10초가 다음 달 누군가의 반나절을 아낀다.
검증 루틴: CLAUDE.md가 실제로 작동하는지 확인하는 가장 빠른 방법은 같은 태스크를 파일 없이, 그리고 파일과 함께 두 번 실행해보는 것이다. 프롬프트에 명시하지 않았는데도 에이전트가 네이밍 컨벤션을 따른다면, 컨텍스트 파일이 제 역할을 하고 있는 거다.
태스크 명세 품질: Faros AI 연구가 강조한 것처럼, 컨텍스트 품질과 태스크 명세 품질은 서로 보완하지 대체하지 않는다. 엔지니어링된 컨텍스트가 출시 가능한 소프트웨어를 만드는 건, 태스크가 에이전트에게 무엇을 만들지 알려줄 때만이다.
지금 당장 할 수 있는 것
이 모든 논의의 실용적 결론은 단순하다. 오늘 프로젝트 루트에 CLAUDE.md 파일을 만들어라. 다섯 섹션, 30줄 이하. 다음 Claude Code 세션에서 첫 시도 정확도의 차이를 직접 확인하라. 모델이 바뀌는 게 아니다. 모델이 프로젝트에 대해 아는 것이 바뀐다.
이거 Claude한테 처음 물어봤을 때, 매번 컨벤션 설명에 쓰던 시간이 없어진 걸 바로 느꼈다. 팀 전체가 같은 컨텍스트 파일을 공유하면 효과는 개인이 아니라 팀 단위로 복리가 된다. 컨텍스트 엔지니어링은 화려한 기술이 아니다. 마크다운 파일 하나다. 그 차이가 생각보다 크다.