GPT-5.4의 핵심은 성능 숫자보다도 ‘제품이 직접 UI를 조작해 일을 끝내는’ 단계로 넘어갔다는 점입니다. 뉴스탭 보도에 따르면 OpenAI는 GPT-5.4에 범용 모델 최초로 computer-use를 기본 탑재했고, 스프레드시트·문서·프레젠테이션 같은 실제 업무 툴을 넘나들며 작업을 수행하는 쪽으로 무게중심을 옮겼습니다. 이 변화는 그로스 관점에서 Activation의 정의를 바꿉니다. 이제 “대화를 몇 번 했는가”가 아니라 “업무 결과물이 생성·반영됐는가”가 첫 가치(Aha)입니다.
맥락을 더 밀어보면, GPT-5.4는 추론+코딩+에이전트를 한 모델로 통합하고, 장시간 계획/검증에 유리한 큰 컨텍스트를 내세웁니다. GDPval에서 83%가 전문가 수준이라는 메시지도 결국 “업무를 맡길 수 있다”는 신호죠. 문제는 여기서부터입니다. 에이전트가 UI를 만지기 시작하면, 사용자는 편해지는 대신 불안해집니다. ‘어디를 클릭했는지’, ‘어떤 데이터에 접근했는지’, ‘실수로 삭제/외부전송은 없었는지’를 알 수 없다면 B2B 구매자는 결재를 못 올립니다. 전환은 성능이 아니라 신뢰에서 막힙니다.
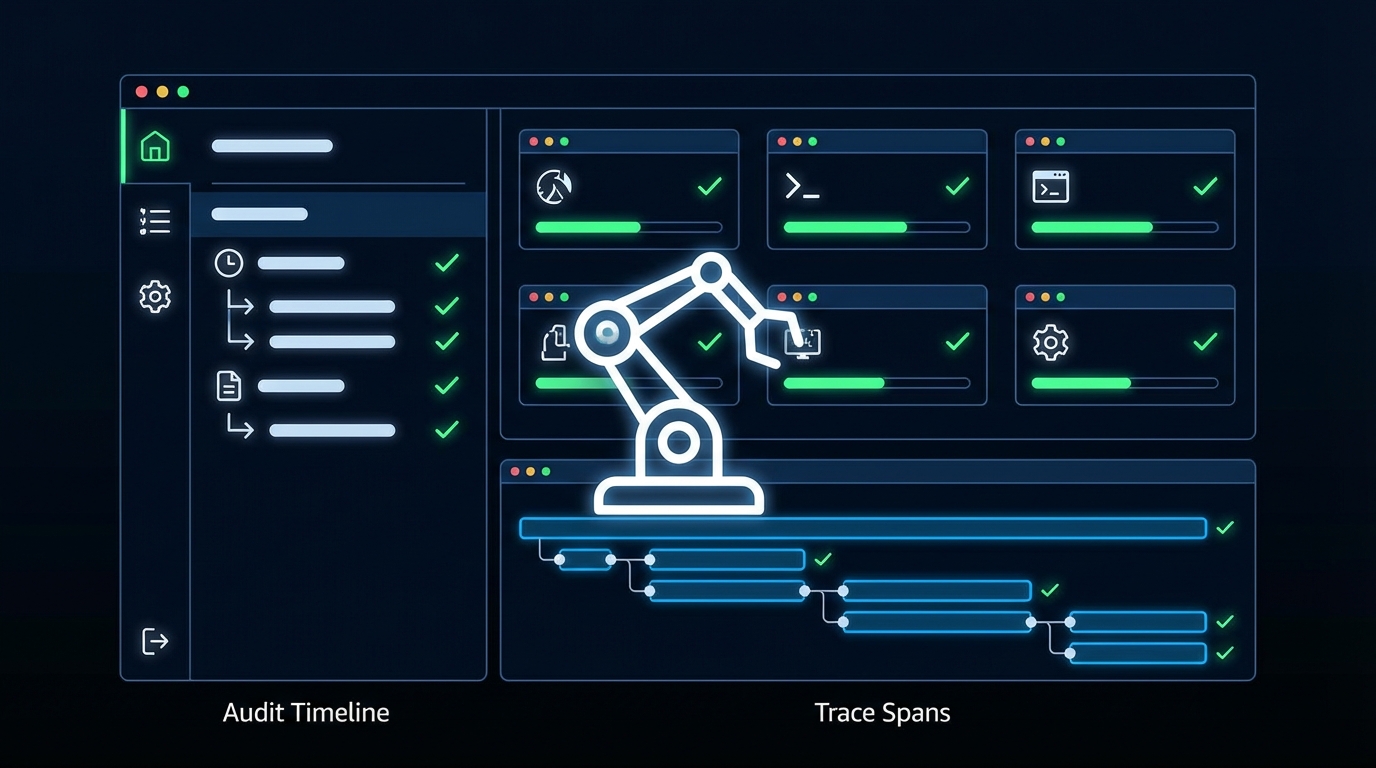
그래서 퍼널 레버가 ‘기능’에서 ‘신뢰 인프라’로 이동합니다. dev.to의 OpenTelemetry 패턴 글이 말하듯, 에이전트 워크플로는 마이크로서비스처럼 분산 추적이 필요합니다. plan → model_call → tool_call → guardrail_hit → error 같은 이벤트 스키마로 실행 상태를 구조화하고(AgentEvent), 토큰/지연/에러를 트레이스에 묶어야 “왜 45초가 걸렸는지, 어디서 비용이 새는지”가 보입니다. 이건 운영 효율만의 문제가 아니라, 세일즈가 들고 갈 수 있는 신뢰 증거입니다.
하지만 텍스트 로그만으로는 부족해지는 지점이 옵니다. 또 다른 dev.to 글은 ‘행동 증거(visual behavioral proof)’를 주장합니다. UI를 조작하는 에이전트에겐 “DB 로그는 있는데 화면에서 뭘 봤는지 없다”가 컴플라이언스 공백이 됩니다. 특히 Slack/CRM/어드민처럼 민감 데이터가 있는 도메인에서는, 스크린 단위의 전후 상태와 단계별 설명이 붙은 감사 아티팩트(예: 영상)가 의사결정을 가속합니다. 즉, Activation을 ‘완료된 결과물’로 재정의하려면, 그 결과물이 만들어진 과정을 감사 가능하게 패키징해야 합니다.
시사점은 명확합니다. 1) 온보딩은 “무엇을 할까요?”가 아니라 “첫 작업을 끝내드렸습니다(증거 포함)”로 바뀌어야 합니다. 2) B2B 전환 경로에는 보안팀·컴플라이언스팀을 위한 트랙이 필요합니다: 추적(OTel) + 민감정보 마스킹/트렁케이션 + 가드레일 이벤트 + 재시도/중복실행 방지 기록. 3) 제품 메트릭도 재설계해야 합니다. Activation을 ‘첫 번째 자동 완료’로 두고, 그 성공률/소요시간/승인(사용자 확인)까지를 코호트로 봐야 D7/D30의 원인을 잡습니다. “에이전트가 일을 했다”가 아니라 “사람이 믿고 승인했다”가 리텐션입니다.
전망: GPT-5.4 같은 computer-use 모델이 확산될수록, 경쟁 우위는 ‘더 똑똑한 모델’보다 ‘더 증명 가능한 실행’으로 이동합니다. 결국 같은 업무 자동화라도 감사추적이 있는 제품이 CAC를 낮추고(보안 검토 기간 단축), 세일즈 사이클을 줄이며, 리텐션을 지킵니다. 다음 분기 그로스 실험의 우선순위는 분명합니다. 에이전트가 만든 결과물에 (1) 실행 타임라인, (2) 툴 호출 로그(PII 안전), (3) 화면/상태 증거, (4) 사용자 승인 CTA를 붙여 “신뢰 → 전환” 루프를 설계하세요. 성능은 상향평준화됩니다. 전환을 만드는 건 신뢰의 제품화입니다.