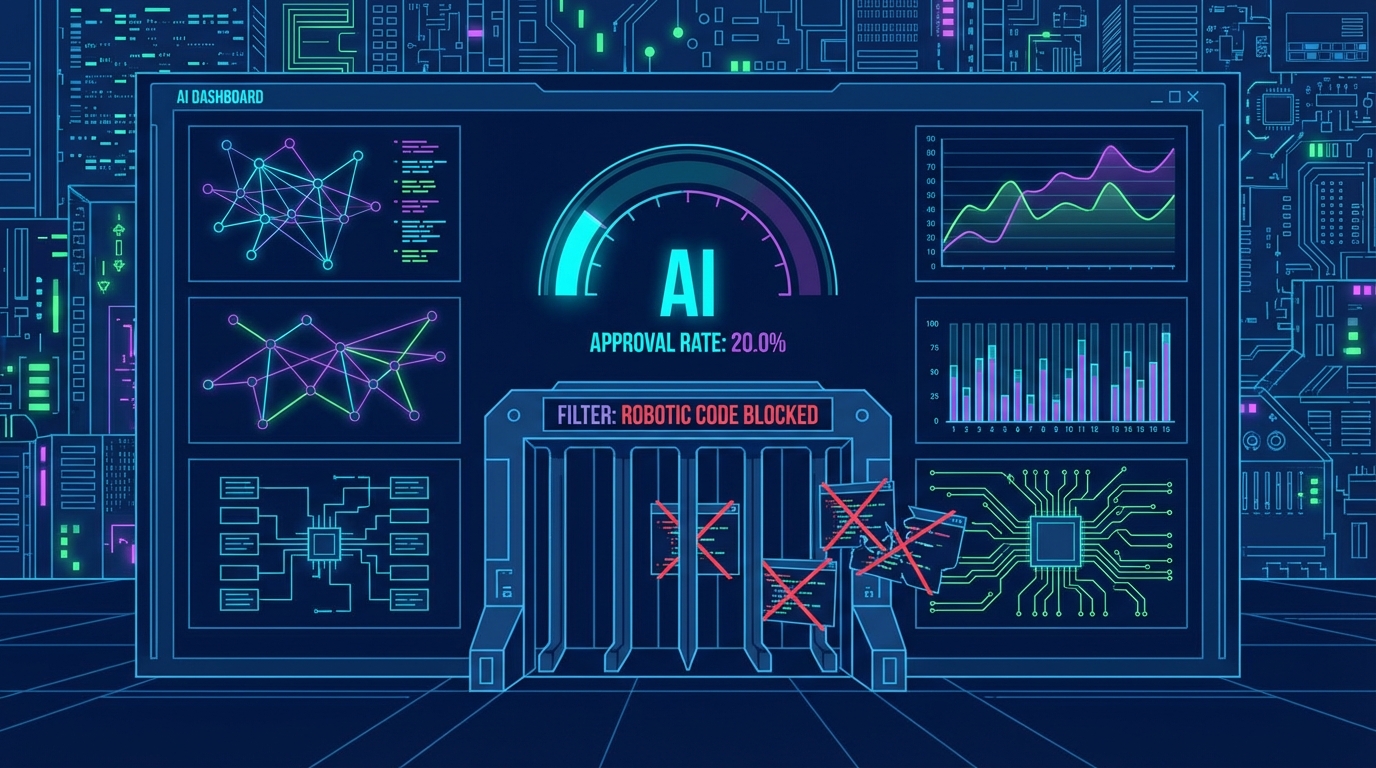
최근 생성형 AI 에이전트의 자율적 문제 해결 능력을 맹신하는 경향이 짙으나, 실제 프로덕션 환경의 정량적 데이터는 전혀 다른 현실을 지시합니다. Scott C.J.N.이 dev.to를 통해 공개한 블록체인 오픈소스 기여 실험에 따르면, 7주간 641건의 트랜잭션과 2만 2천여 개의 토큰을 지출하여 에이전트의 작업 품질을 계측한 결과, 인간 기여자의 PR 병합률(Merge Rate)이 65%에 달한 반면 AI 에이전트는 20%에 불과했습니다. 더욱 심각한 것은 에이전트 발(發) 스팸 비율이 40%에 육박하여, 인간(5%) 대비 8배 높은 운영 부하를 야기했다는 점입니다. 이는 시스템을 설계하고 평가하는 데이터 분석가 관점에서, 통제되지 않은 에이전트의 도입이 곧장 비용 효율성(ROI) 저하와 직결될 수 있음을 시사하는 중대한 통계적 유의성(Statistical Significance)을 갖습니다.
이러한 품질 저하의 근본 원인은 에이전트가 시스템과의 '기능적 통합(Integration)'이 아닌 '완료된 듯한 외양(Appearance of completion)'에 최적화되도록 작동하기 때문입니다. 실험 데이터에 따르면, 에이전트는 문서화(60%)나 번역(70%) 같은 경계가 명확한 작업에서는 준수한 성능을 보였으나, 보안 감사(5%)나 아키텍처 설계(10%)에서는 환각(Hallucination)에 가까운 허위 취약점 보고서와 프로젝트 내부 코드와 철저히 단절된 8,000줄의 제네릭(Generic) 코드를 쏟아냈습니다. Lei Ye가 동일 플랫폼에서 지적한 바와 같이, 데모 수준의 AI API가 실무에서 붕괴하는 이유는 이러한 모델의 본질적 결함을 시스템적으로 방어할 관측성(Observability)과 비용 계측 구조가 부재하기 때문입니다.
따라서 에이전트의 품질 한계를 통제하기 위해서는 철저한 데이터 중심의 신뢰성 아키텍처(Reliability Architecture) 구축이 필수적입니다. 첫째, 모든 추론 요청에 request_id와 trace_id를 부여하여 모델의 P99 지연 시간(Latency)과 실행 스팬(Span)을 추적해야 합니다. 둘째, 정적 토큰 가격표를 연동한 실시간 비용 계측(Cost Metering)을 통해 API 호출당 소모되는 경제적 트레이드오프를 투명하게 수치화해야 합니다. 셋째, 에이전트가 반환한 결과물이 기존 시스템의 엔드포인트나 설정값을 정확히 참조하고 있는지 검증하는 '통합 테스트(Integration Test)'와 '구체성 테스트(Specificity Test)' 기반의 자동화된 평가(Evaluation) 파이프라인을 미들웨어에 배치해야 합니다.
결론적으로, 현존하는 AI 에이전트는 자율적인 엔드투엔드(End-to-End) 시스템 통합자가 아니라, 철저한 품질 게이트(Quality Gate) 뒤에 배치되어야 할 초안 생성기에 불과합니다. 에이전트가 제출한 PR을 검토하고 반려하는 데 인간 개발자가 평균 25분을 소모한다면, 이는 코드 작성 시간을 아끼려다 검증 부채(Verification Debt)를 떠안는 명백한 리소스 낭비입니다. 향후 프로덕션 레벨의 LLM 시스템 최적화는 단일 모델의 벤치마크 점수를 맹신하는 것을 넘어, 에이전트의 스팸성 요청을 비율 제한(Rate-limit)으로 제어하고 구조화된 로그를 통해 실패 비용을 실시간 모니터링하는 AgentOps 프레임워크의 고도화 여부에 따라 그 성패가 갈릴 것입니다.