생성형 AI 에이전트를 프로덕션 환경에 배포할 때 가장 흔히 범하는 치명적인 오류는 '자율성(Autonomy)'을 '방치'로 오인하는 것입니다. 시스템이 알아서 작동한다는 환상은 곧 통제되지 않은 API 호출 빈도와 문맥 없는(context-less) 재시도 루프를 낳고, 이는 필연적으로 기하급수적인 비용 누수와 P99 지연 시간(Latency)의 붕괴로 이어집니다. 최근 dev.to에 공유된 두 건의 실제 운영 사례는, 에이전트 시스템의 비용과 성능 트레이드오프를 최적화하기 위해 우리가 모니터링해야 할 지표가 무엇인지 정량적으로 증명하고 있습니다. 핵심은 에이전트의 실행 주기(Cadence)에 대한 엄격한 비용 할당(Cost Attribution)과, 기계 친화적(Agent-native)인 백엔드 컨텍스트 설계입니다.
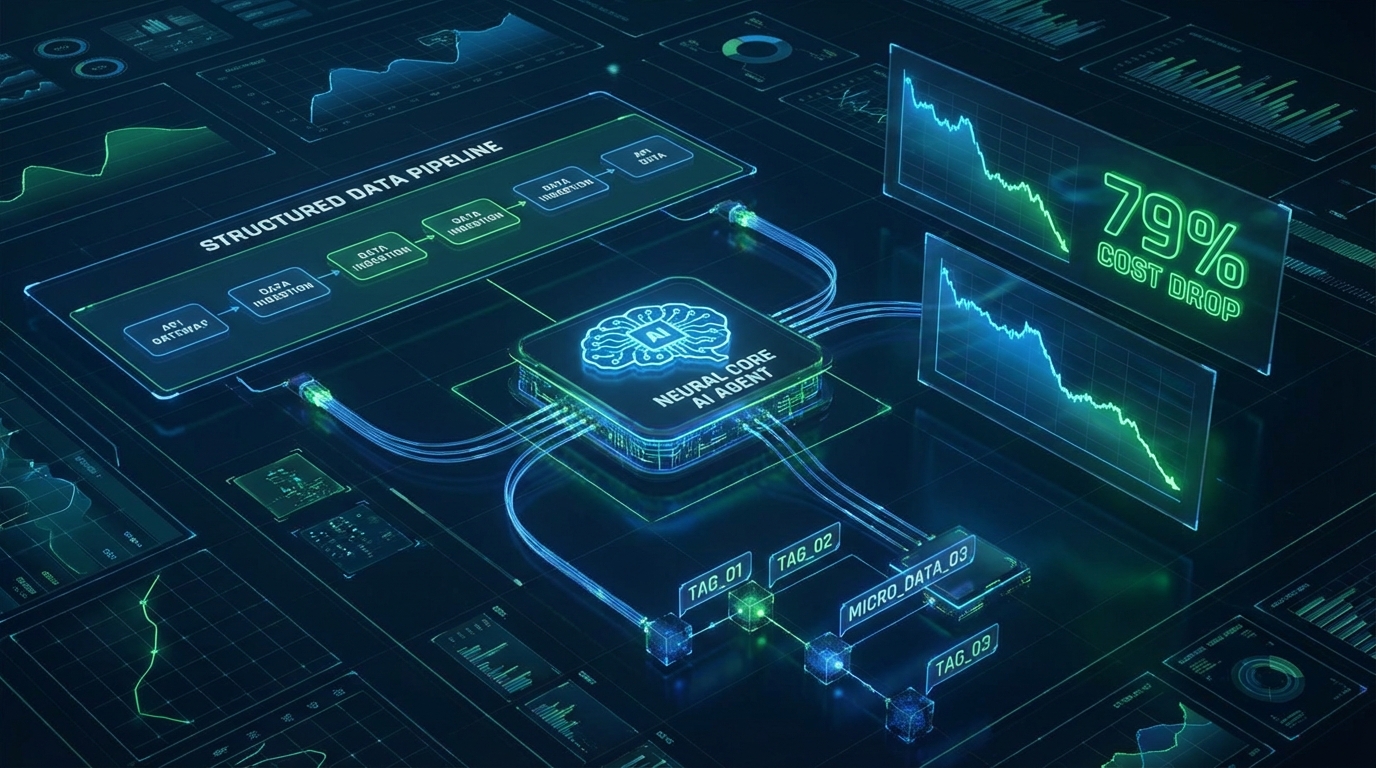
첫 번째 이슈는 관측성(Observability)이 결여된 에이전트 루프가 유발하는 재무적 병목입니다. 'askpatrick'의 사례에 따르면, 개발팀은 월 198달러라는 예상치 못한 API 청구서를 마주한 후 원인을 분석했습니다. 범인은 고비용의 복잡한 LLM 추론이 아니라, '60초 주기로 4개의 외부 툴을 호출하는 단일 에이전트 루프'였습니다. 이를 정량화하면 하루 5,760건, 월 172,800건의 무의미한 툴 호출이 발생한 것입니다. 저는 이를 전형적인 'AgentOps 계측 실패'로 진단합니다. 다중 에이전트 환경에서는 API 비용이 하나의 풀(pool)로 묶이게 되며, 개별 에이전트나 특정 루프 단위의 토큰 소모량을 추적하지 못하면 비용 최적화는 불가능합니다.
이 문제를 해결하기 위해 도입된 '3단계 비용 할당 패턴'은 실무적으로 매우 우수한 접근법입니다. 모든 LLM API 호출 메타데이터에 {"agent": "suki", "loop": "content-loop", "task": "draft-tweet"}와 같은 태깅을 강제화하여 로그를 적재하고, 타이머 기반이 아닌 이벤트 기반(Event-driven)으로 루프 주기를 재설정했습니다. 그 결과, 모델의 성능(Generation Quality)을 전혀 타협하지 않고도 월 API 비용을 42달러로 79% 절감했습니다. 이는 A/B 테스트나 모델 스위칭 이전에, 아키텍처 수준의 로깅과 실행 주기 통제만으로도 압도적인 ROI를 달성할 수 있음을 통계적으로 보여줍니다.
두 번째 이슈는 에이전트가 백엔드 작업을 수행할 때 발생하는 '컨텍스트 결핍으로 인한 토큰 낭비와 실패'입니다. 'astrodevil'의 MCP(Model Context Protocol) 분석 기사는 현재 Supabase나 Postgres의 MCP 서버가 지닌 근본적인 설계 결함을 지적합니다. 현재의 백엔드 플랫폼들은 대시보드를 눈으로 확인하는 '인간 작업자'를 가정하고 설계되었습니다. 따라서 에이전트가 list_tables를 호출하면 레코드 수나 RLS(Row Level Security) 상태, 정책 정의가 누락된 단순 테이블 이름만 반환됩니다. 시각적 단서(UI)가 없는 에이전트에게 이는 치명적인 '스키마 맹점(Schema Blindness)'을 유발합니다.
이러한 정보의 결핍은 에이전트의 환각(Hallucination)이나 무한 재시도(Retry) 루프로 직결됩니다. 예를 들어 MCPMark의 RLS 구현 벤치마크를 보면, 에이전트가 RLS 활성화 여부를 몰라 상태 확인과 검증을 위해 23번의 추가 턴(Turns)을 소비하고 581,000개의 토큰을 낭비하는 현상이 관측되었습니다. 이는 에이전트의 추론 능력이 부족해서가 아니라, 인풋 데이터(Context)의 해상도가 낮아 발생한 구조적 에러입니다. 상태가 비결정론적인 환경에서 에이전트는 정보를 얻기 위해 '추측성 쿼리'를 남발하게 되며, 이는 데이터베이스 병목과 비용 증가의 주범이 됩니다.
이를 해결하는 방법은 처음부터 에이전트를 위해 설계된(Agent-native) 백엔드 MCP를 도입하는 것입니다. InsForge와 같은 Context-First 설계는 단 두 번의 툴 호출만으로 실시간 레코드 수와 RLS 상태 등 깊은 컨텍스트를 에이전트에게 제공합니다. MCPMark 21개 태스크 벤치마크 결과, 이러한 구조는 기존 설계 대비 47.6%의 통과 정확도(Pass Accuracy)를 기록했으며, 토큰 사용량은 30% 감소하고 실행 속도는 1.6배 향상되었습니다. Retrieval의 정확도(Context Precision)가 Generation의 품질을 결정짓는 RAG의 원리와 동일하게, 백엔드 자동화에서도 도구가 반환하는 페이로드(Payload)의 완결성이 에이전트의 성공률을 좌우하는 것입니다.
결론적으로, 프로덕션 레벨의 에이전트 시스템을 평가할 때는 LLM 자체의 벤치마크(Perplexity 등)에 집착하기보다 파이프라인 전체의 효율성을 측정해야 합니다. 모든 툴 호출과 루프에 식별자를 부여하여 비용의 인과관계를 추적(Cost Attribution)하고, 에이전트가 단일 호출로 확정적(Deterministic)인 상태 정보를 얻을 수 있도록 MCP 응답 스키마를 최적화해야 합니다. 통제되지 않은 자율성은 시스템의 부채일 뿐이며, 정밀하게 계측된 컨텍스트와 실행 주기만이 AI 시스템의 진정한 확장성(Scalability)을 보장합니다.