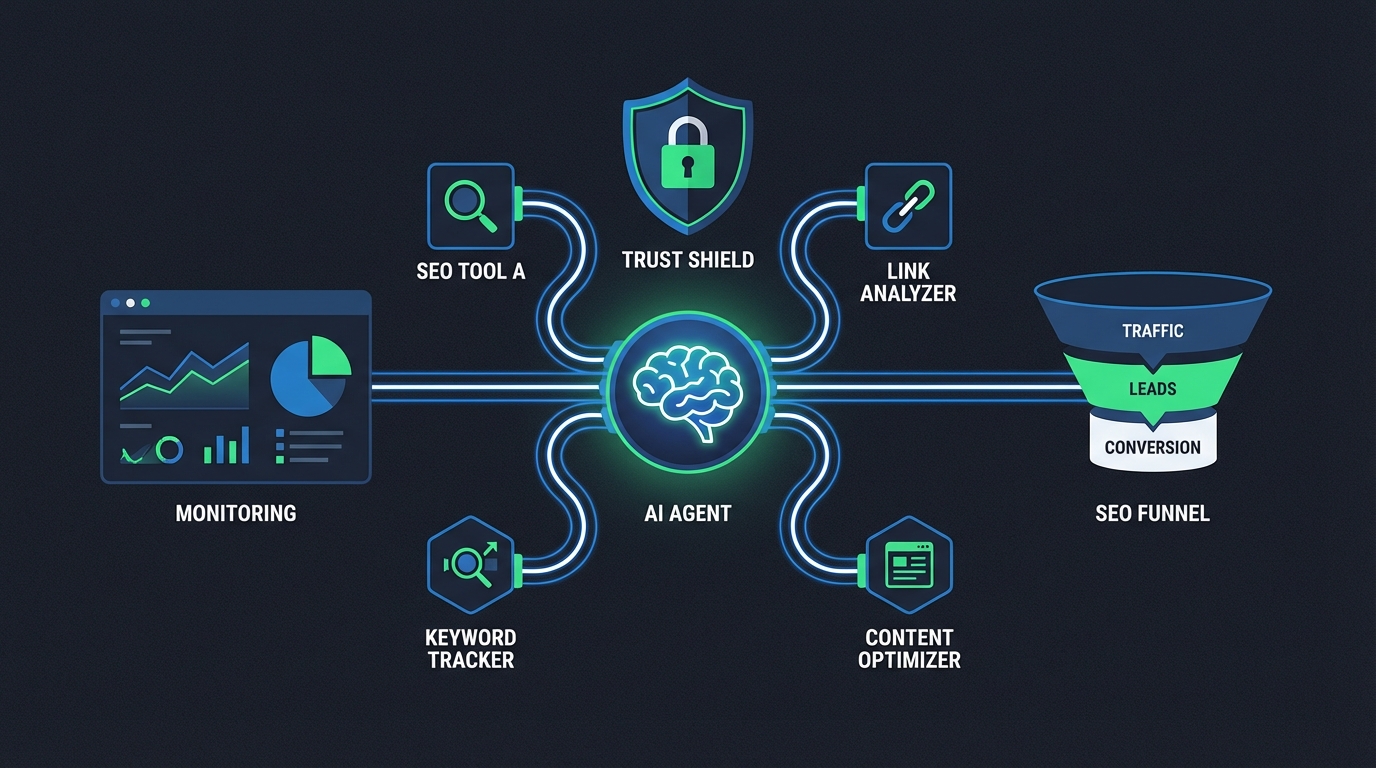
MCP(Model Context Protocol)가 SEO 자동화를 ‘대시보드 클릭 노동’에서 ‘대화형 실행’으로 바꾸고 있습니다. dev.to에 공개된 SearchAtlas MCP 서버 사례처럼, 에이전트가 키워드 조사·기술 SEO 점검·콘텐츠 생성·백링크 탐색까지 16개 도구를 직접 호출하면 반복 작업이 사라지고 실험 속도는 기하급수로 올라갑니다. 문제는 여기서부터입니다. 프로덕션에서 신뢰성이 담보되지 않으면, 자동화는 곧바로 전환율/리텐션 리스크로 바뀝니다.
맥락은 명확합니다. SearchAtlas MCP 서버는 Claude/Cursor/VS Code 등 MCP 클라이언트에서 로컬 프로세스로 실행되고(JSON-RPC over stdio), 필요한 데이터를 API로 가져와 분석·생성을 한 번에 끝냅니다(dev.to: algomachine007). 이 구조는 성장팀에 매력적입니다. “롱테일 키워드 찾고 → 난이도 필터링 → 아웃라인 생성 → 초안 작성 → 내부링크 제안 → 발행 체크리스트 실행” 같은 체인을 ‘플레이북’으로 묶어 하루 수십 번 돌릴 수 있으니까요. 결국 CAC를 낮추는 가장 직접적인 레버(유입 채널 효율, 콘텐츠 공급량, 실험 횟수)를 건드립니다.
하지만 MCP 생태계의 약점도 동시에 커집니다. 또 다른 dev.to 글은 “MCP 서버가 프로덕션급인지 판단할 품질 신호가 없다”고 지적합니다. 스타 수는 바이럴 지표일 뿐, P95/P99 지연, 에러율, 실패 모드, 엣지케이스 대응, 유지보수 상태를 말해주지 않습니다(sampathchanda). 사람이 쓰면 짜증나는 수준이지만, 에이전트가 자율적으로 돌면 더 위험합니다. 실패를 ‘조용히’ 삼키거나, 틀린 결과를 ‘확신 있게’ 내보내도 티가 안 나기 때문입니다. 이때 타격은 트래픽이 아니라 퍼널입니다: 잘못된 키워드 선택→의도 불일치 콘텐츠→SERP 반응 악화→세션 품질 하락→전환율 하락→브랜드 신뢰 하락→재방문 감소.
그래서 핵심은 ‘연결’이 아니라 ‘운영 가능한 신뢰 설계’입니다. 첫째, 자동화 파이프라인을 퍼널 관점으로 쪼개야 합니다. 예를 들어 SEO 자동화의 목적이 “콘텐츠 발행 수”가 아니라 “유입→Activation→전환”이라면, 에이전트 산출물의 품질 게이트를 CTR/체류/스크롤/전환 같은 다운스트림 지표와 연결해 자동 롤백/재생성을 설계해야 합니다. 둘째, 신뢰 문제는 기술이 아니라 규칙으로 줄일 수 있습니다. dev.to의 ‘에스컬레이션 룰(불확실하면 outbox.json에 쓰고 멈춰라)’은 실수 80% 감소를 만들었습니다(askpatrick). SEO 자동화에도 그대로 적용됩니다: (1) 도구 응답 포맷이 예상과 다르면 중단, (2) 난이도/볼륨 임계값을 동시에 만족하는 키워드가 없으면 중단, (3) 브랜드/법무 금칙어 탐지 시 중단, (4) 발행 전 메타/내부링크/중복검사 체크리스트 실패 시 중단. “추측 금지”가 전환율을 지키는 최소 비용의 보험입니다.
시사점은 한 줄로 정리됩니다. MCP SEO 자동화의 승부처는 ‘툴을 몇 개 붙였나’가 아니라, 품질 신호 레이어(관측) + 실패 처리(에스컬레이션) + 실험 루프(학습)를 얼마나 빨리 제품화하느냐입니다. 팀 관점에선 다음이 바로 실행 항목입니다: (a) MCP 서버별 SLO(지연/에러/타임아웃) 로그 수집, (b) 작업 단위로 성공 정의(예: “키워드 리스트”가 아니라 “D7 유입 유지되는 토픽”), (c) outbox 기반 휴먼리뷰 큐와 재시도 정책, (d) 플레이북 실행 결과를 코호트로 묶어 ‘자동화 유입의 질’을 측정.
전망은 양면적입니다. 단기적으로는 MCP가 SEO 운영의 ‘생산성 격차’를 크게 벌릴 겁니다. 60초 셋업처럼 진입장벽이 낮아져, 누구나 에이전트-툴 체인을 만들 수 있으니까요. 동시에 신뢰성 레이어가 없는 자동화는 스케일할수록 독이 됩니다. 결국 시장은 두 부류로 갈립니다: 자동화로 콘텐츠를 찍어내다 퍼널 지표가 무너지는 팀, 그리고 품질 신호·에스컬레이션·측정까지 묶어 CAC를 구조적으로 낮추는 팀. MCP SEO자동화의 ‘신뢰 설계’는 선택이 아니라, 성장의 브레이크가 되지 않기 위한 필수 인프라입니다.