생성형 AI 시스템이 텍스트를 넘어 멀티모달 환경으로 확장됨에 따라, 프로덕션 레벨의 가장 큰 병목은 ‘연산량(FLOPs)과 해상도(Resolution) 간의 트레이드오프’로 귀결되고 있다. Velog 기술 블로그에 소개된 DeepSeek-VL의 시각 정보 압축 전략과 Diffusion Transformer(DiT)의 아키텍처 전환 사례는, 단순히 생성 품질을 높이는 것을 넘어 시스템의 연산 효율성을 극대화하기 위한 정량적 접근의 정수를 보여준다. 이는 제한된 VRAM 환경에서 P99 지연 시간(Latency)을 통제해야 하는 ML 시스템 설계자들에게 중요한 레퍼런스가 된다.
DeepSeek-VL 아키텍처의 핵심은 하이브리드 비전 인코더를 통한 극단적인 토큰 효율성(Token Efficiency) 최적화다. 1024×1024 고해상도 이미지를 단일 인코더로 처리할 경우 발생하는 연산량의 기하급수적 증가를 막기 위해, 저해상도(384×384)의 SigLIP-L과 고해상도의 SAM-B를 병렬 배치했다. 특히 주목할 점은 비전-언어 어댑터(VL Adaptor)의 차원 변환 메커니즘이다. SAM-B에서 추출된 피처 맵을 2-Layer Hybrid MLP 구조를 통해 최종적으로 단 576개의 시각 토큰(2048차원)으로 압축해낸다. 이는 LLM의 컨텍스트 윈도우 부담을 획기적으로 낮춰 서빙 환경의 지연 시간을 방어하는 동시에, 디테일한 정보 손실을 최소화하는 정교한 엔지니어링의 결과다.
학습 파이프라인의 데이터 효율성 지표도 시사하는 바가 크다. DeepSeek 연구팀의 1단계 어댑터 웜업(Warm-up) 실험 결과, 학습 데이터 스텝을 2K에서 80K로 무작정 늘렸을 때 MMB 벤치마크 점수가 오히려 59.0에서 58.1로 하락하는 현상이 관측되었다. 이는 파라미터 용량이 제한된 어댑터 단독 학습 모델에서 발생하는 과적합(Overfitting)과 일반화 성능 저하를 통계적으로 증명한 사례다. 데이터의 절대적인 양보다 각 학습 단계(Stage)에 맞는 파라미터 동결 해제(Unfreezing) 전략이 모델 성능에 직접적인 인과관계를 가짐을 명확히 보여준다.
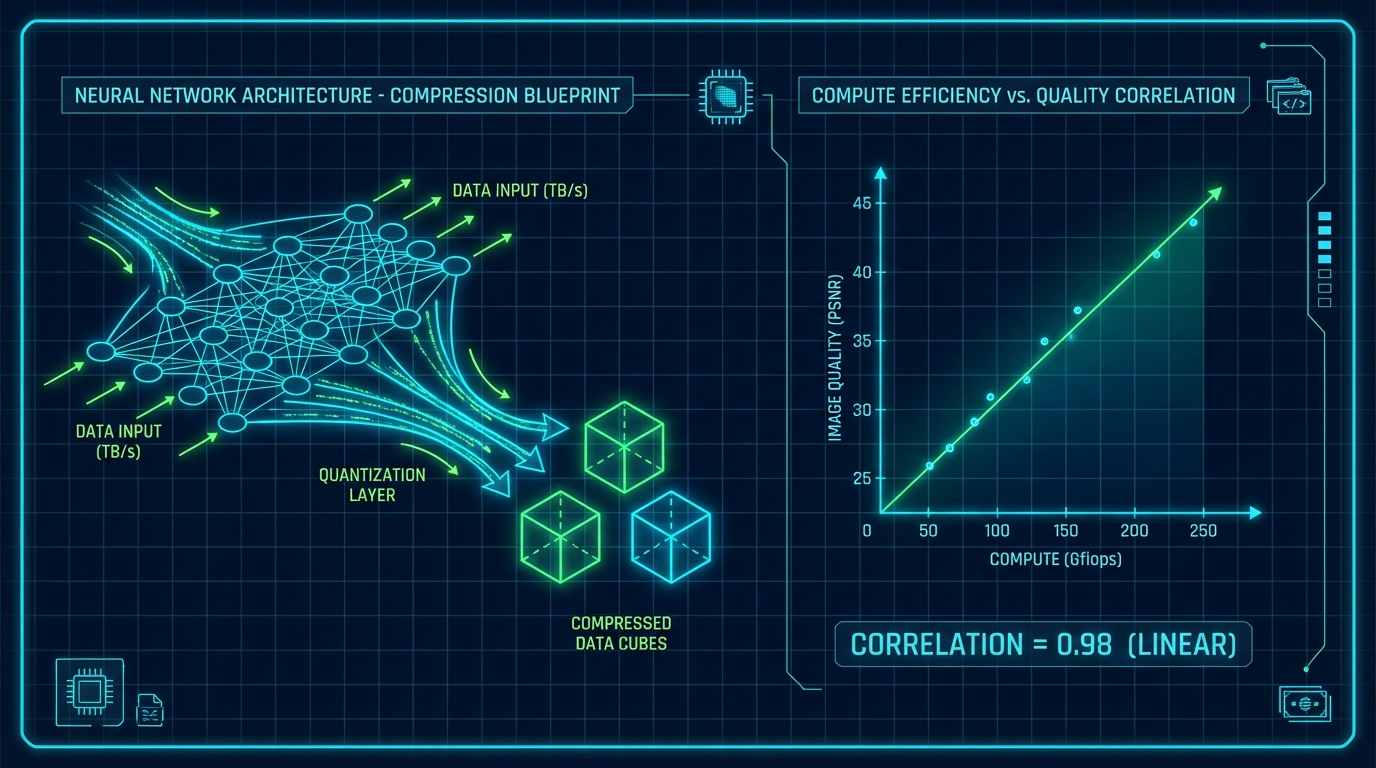
한편 이미지 생성 영역에서는 DiT가 기존 U-Net의 귀납적 편향(Inductive Bias)을 제거하고 표준화된 트랜스포머 아키텍처를 도입하며 연산 스케일링의 새로운 기준을 제시했다. 앞선 분석 기사에서 강조된 DiT의 본질적 가치는 연산 복잡도(Gflops)와 생성 품질(FID 점수) 간의 강력하고 일관된 상관관계를 입증했다는 데 있다. 모델의 순방향 패스(Forward Pass) 연산량이 증가할수록 FID 점수가 선형적으로 개선되는 현상은, 비전 생성 모델 역시 자연어 처리의 '확장 법칙(Scaling Laws)'을 따를 수 있음을 시사한다. 이는 A/B 테스트나 프로덕션 배포 시, 투입되는 컴퓨팅 비용 대비 성능 개선율을 수학적으로 예측 가능하게 만든다.
결론적으로 멀티모달 연산 최적화의 미래는 ‘토큰 압축률의 극대화’와 ‘예측 가능한 스케일링’이라는 두 축으로 수렴하고 있다. DeepSeek-VL의 이기종(Heterogeneous) 인코더 결합 패턴은 RAG나 멀티 에이전트 시스템에서 다중 모달리티를 처리할 때 참조할 수 있는 최적의 라우팅 구조다. 동시에 DiT의 아키텍처는 리소스 투입에 따른 산출을 정량적으로 타겟팅할 수 있는 프레임워크를 제공한다. 향후 AI 엔지니어들은 맹목적인 파라미터 확장이 아닌, 단위 연산당 정보 압축 효율과 아키텍처의 재현성(Reproducibility)을 우선시하는 데이터 중심 파이프라인 설계에 집중해야 할 것이다.