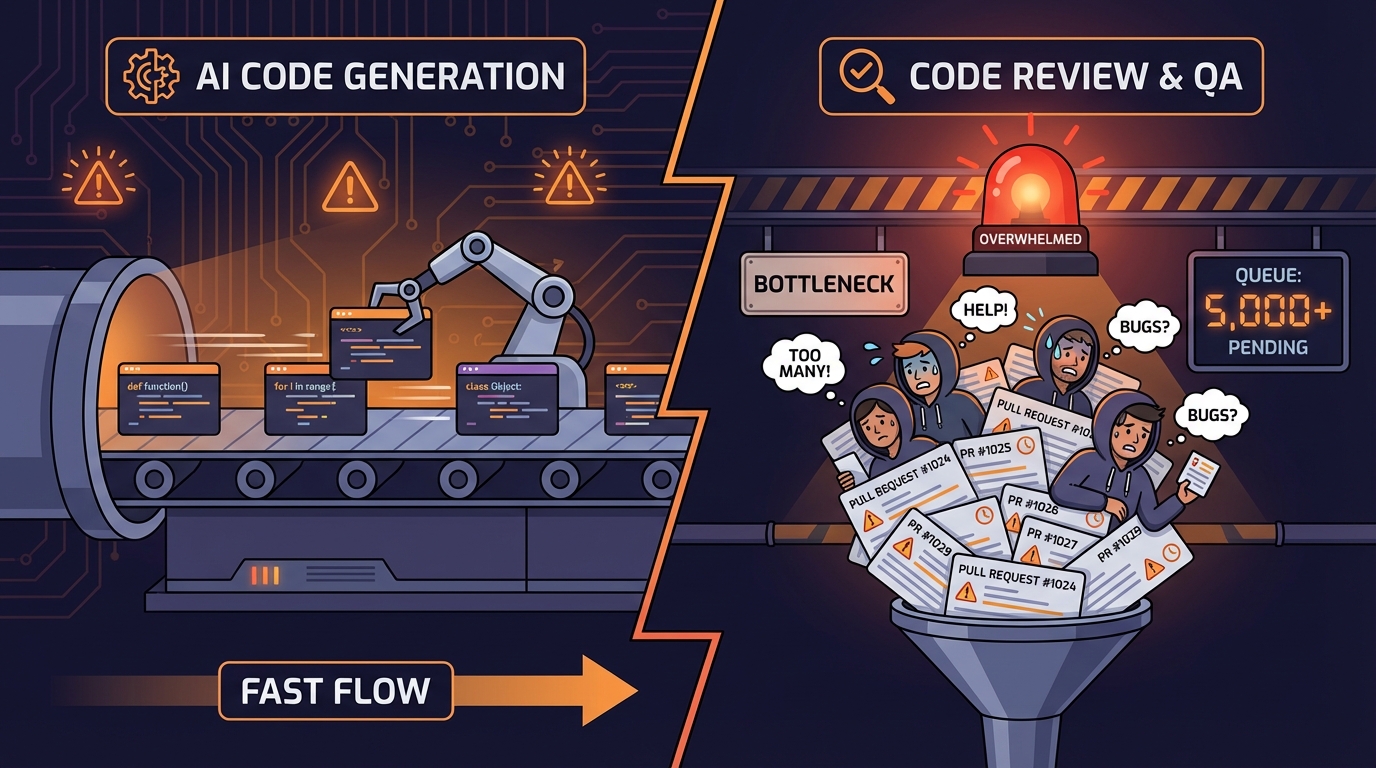
Anthropic이 자사 엔지니어 132명을 대상으로 Claude Code 사용 데이터를 조사했을 때, 숫자는 인상적이었다. 개인당 PR 병합 수 67% 증가, 일일 업무 중 AI 도구 활용 비율 28%→59%, 자기보고 생산성 향상 20~50%. 그런데 조직 대시보드를 열자 배포 주기, 리드 타임, 변경 실패율—DORA 핵심 지표 전부가 제자리였다. 같은 기간 코드 리뷰 시간은 91% 증가했다.
이 숫자들의 간극이 말해주는 것은 단순하다. AI 코딩 도구는 파이프라인 전체를 빠르게 만드는 게 아니라, 특정 단계만 빠르게 만든다. 코드 생성 속도는 올랐지만, 그 코드가 팀을 통과해 프로덕션에 닿기까지의 설계·리뷰·QA·배포 단계는 그대로다. 한 단계만 가속되면 파이프라인 전체에 병목이 생긴다—다음 단계에 물이 쌓이는 것처럼.
dev.to에 실린 The Claude Code Productivity Paradox 분석은 이 구조를 태스크 유형별로 해부한다. 보일러플레이트·스캐폴딩은 약 10배 빨라졌고, 복잡한 로직·디버깅은 약 2배, 아키텍처·설계는 거의 개선이 없었다. 기계적인 작업은 극적으로 빨라졌지만 판단이 필요한 작업은 그대로다. 즉 AI가 가속한 부분은 정확히 리뷰어와 QA가 검토해야 할 코드 양을 늘리는 부분이다. PR이 쌓이는 속도는 빨라지는데, 그걸 소화하는 속도는 그대로면 어디서 막히는지는 자명하다.
리뷰 병목이 심화되면 또 다른 문제가 나온다. 단일 AI 리뷰어로 이 물량을 처리하려는 시도다. Spencer Marx가 공개한 Open Code Review 프로젝트는 이 접근의 구조적 한계를 정면으로 지적한다. 하나의 모델이 diff를 한 번 훑는 방식은 "경쟁 없는 의견"에 불과하다. 실제 고성능 리뷰 문화는 서로 다른 시각을 가진 리뷰어들이 동일한 코드를 보고 논쟁하는 과정에서 만들어진다. 보안 담당자가 플래그를 세우면 아키텍트가 맥락을 붙이고, 품질 담당자가 두 의견 사이의 에러 핸들링 공백을 짚는 식이다. 이 '담론' 단계를 거친 리뷰 결과는 단일 패스보다 훨씬 높은 신호 대 잡음비를 갖는다—검증되지 않은 의견보다 경합을 거친 의견이 더 신뢰할 수 있다는 원리는 AI에도 똑같이 적용된다.
리뷰 병목보다 더 근본적인 문제가 있다. AI가 작성한 코드를 같은 AI로 검증하는 구조, 즉 '자기 축하 기계(self-congratulation machine)'다. claudecodecamp.com이 공개한 TDD 기반 에이전트 검증 파이프라인 분석은 이 문제를 100명 이상의 엔지니어를 대상으로 한 워크숍 경험에서 확인했다. Claude를 일상 PR에 활용하는 팀들은 주당 PR 병합량이 10개에서 40~50개로 늘었고, 코드 리뷰에 훨씬 더 많은 시간을 쏟고 있었다. 자율 에이전트가 밤새 코드를 생성하면, 팀은 diff를 리뷰하는 대신 배포를 지켜보며 오류가 없기를 바라는 구조로 흘러간다. 이건 속도 문제가 아니라 신뢰 문제다.
이 분석이 제안하는 해법은 TDD 원칙의 재해석이다. 코드를 작성하기 전에 '완료'의 정의를 먼저 명확히 하는 것—수용 기준(Acceptance Criteria)을 코드보다 먼저 작성하고, 에이전트는 이 기준에 맞춰 구현하고, 별도의 검증 에이전트가 이를 판정한다. 구현한 AI와 검증하는 AI를 분리하는 것이 핵심이다. 로그인 기능을 예로 들면: "유효한 자격 증명으로 접속 시 /dashboard로 리다이렉트", "잘못된 비밀번호 시 'Invalid email or password' 표시", "5회 실패 후 60초 차단"—이 기준들은 각각 통과/실패로 명확히 판별된다. Claude Code headless 모드와 Playwright MCP를 결합한 4단계 파이프라인(Pre-flight → Planner → Browser Agents → Judge)은 이 구조를 실제로 구현한 사례다. 리뷰할 대상이 전체 diff가 아니라 '실패한 수용 기준'으로 좁혀진다.
이 세 가지 데이터 포인트—생산성 역설, 다중 관점 리뷰의 부재, TDD 기반 검증 파이프라인—는 서로 다른 각도에서 같은 조직 문제를 가리킨다. AI 도구 도입이 개인 생산성 향상으로는 분명히 작동하지만, 팀 성과로 연결되려면 검증과 리뷰 설계가 함께 바뀌어야 한다. AI 코딩 도구를 확산하면서 리뷰 인프라에 동시에 투자하지 않으면, 병목이 해소되는 게 아니라 코드 생성에서 리뷰·QA로 이동할 뿐이다.
테크 리드로서 지금 당장 팀에 적용할 수 있는 판단 기준은 세 가지다. 첫째, 측정 대상을 바꿔라. PR 수는 AI가 올려주는 숫자다. 진짜 지표는 사이클 타임, 배포당 결함, 커밋-투-프로덕션 리드 타임이다. 둘째, AI 코딩 도구 확산 전에 리뷰 용량을 먼저 설계하라. 리뷰 시간 증가는 CI 파이프라인 속도 문제가 아니라 구조적 문제다. 빠른 CI로는 못 푼다. 셋째, 작성자와 검증자를 분리하라. 같은 컨텍스트에서 작성과 검증을 동시에 수행하면 원래의 오해는 포착되지 않는다. AI든 사람이든 이 원칙은 동일하게 적용된다.
앞으로의 방향은 더 많은 AI 에이전트를 병렬로 돌리는 것이 아니다. AI가 빠르게 생성하는 코드를 팀 전체가 신뢰할 수 있는 구조—수용 기준 선행 정의, 다중 관점 리뷰, 작성-검증 분리—를 설계하는 것이다. AI가 빨라질수록 검증 설계의 중요성은 더 커진다. 병목이 이동했다면, 투자도 그쪽으로 이동해야 한다.