AI 코딩 도구 도입 프로젝트가 조용히 실패하는 방식은 두 가지다. 아무도 안 쓰거나, 몇몇이 잘못 쓰거나. 전자는 대시보드에 잡힌다. 문제는 후자다. 이용률 지표는 멀쩡한데 팀은 번아웃 직전이고, ROI는 측정조차 안 되는 상황. 이 패턴이 반복되는 건 도구 자체의 문제가 아니다. 도입 설계가 없기 때문이다.
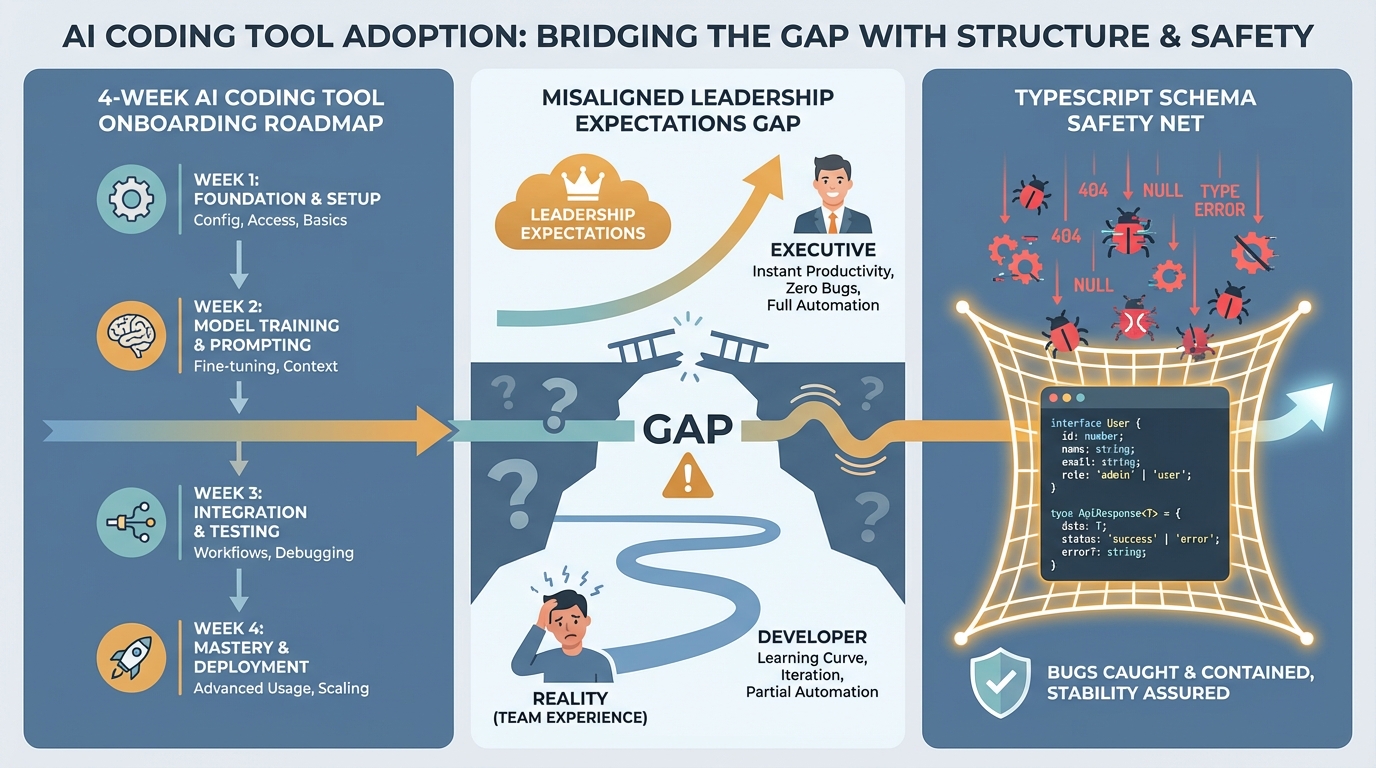
실패는 대부분 1주차에 이미 예고된다
dev.to에 올라온 Claude Code 팀 도입 사례 분석을 보면, 구조 없이 "그냥 써봐" 방식으로 배포했을 때 30일 이용률은 15~25%에 머문다. 단일 앵커 워크플로우와 주간 체크인을 붙이면 45~55%로 뛰고, 4주 단계별 온보딩과 공유 플레이북을 운영하면 65~80%까지 올라간다. 도구는 동일하다. 달라지는 건 온보딩 설계뿐이다.
실전에서 가장 효과적인 진입점은 pre-PR 리뷰다. PR 제출 전에 AI에게 diff를 넘기고 시니어 엔지니어라면 물어볼 법한 지점을 짚어달라고 요청하는 것. PR당 20~40분의 백앤드 커뮤니케이션이 줄어드는 효과를 엔지니어가 즉각 체감한다. 이 '첫 번째 승리 경험'이 없으면 2주차에 흥미가 사라진다.
2주차 이후를 설계하지 않으면 무너진다
1주차를 버텨도 문제는 이어진다. 대부분의 개발자는 "이메일 유효성 검사 함수 써줘" 식의 프롬프트로 막힌다. 출력은 나오지만 우리 코드베이스의 패턴, 에러 핸들링 컨벤션, 스타일 가이드와 맞지 않는다. 여기서 멈추는 팀이 많다.
해결책은 behavior-first prompting이다. "우리 코드베이스에서는 Zod로 스키마 검증을 하고, 커스텀 ValidationError를 던지며, 이 네이밍 패턴을 따른다. 이에 맞는 이메일 검증 함수를 작성해줘." 컨텍스트를 먼저 주입하면 출력 품질이 완전히 달라진다. 이 차이를 팀 전체가 공유하지 않으면 개인 학습이 축적되지 않는다. 30분짜리 팀 세션에서 '잘 된 프롬프트'와 '안 된 프롬프트'를 같이 꺼내놓고 패턴을 추출하는 작업이 2주차의 핵심이다.
3주차부터는 CLAUDE.md 같은 공유 플레이북을 팀이 직접 쌓아가야 한다. 코드 리뷰, 디버깅, 테스트 작성, 비즈니스 요구사항의 티켓 번역 등 실제 쓰인 프롬프트가 모이면 인터넷에서 복붙한 예제가 아닌 우리 팀만의 살아있는 문서가 된다.
리더십 기대치 불일치: 진짜 위험은 여기서 온다
Copilot 도입 후 조직 기대치 불일치를 다룬 또 다른 분석은 더 불편한 현실을 짚는다. r/ExperiencedDevs에 퍼진 사례처럼, 회사가 AI 라이선스를 구입하는 순간 리더십은 "이제 30~40% 더 빠르겠지"라고 계산을 시작한다. 스프린트 기대치가 올라가고, 개발자는 20~30% 이용률로 그 격차를 야근으로 메운다.
이 패턴의 위험은 대시보드에 잡히지 않는다는 점이다. 이용률 수치는 올라가 보이고, 일부 사람은 실제로 AI를 쓰고 있다. 하지만 팀 전체 산출물이 아닌 개인 효율 향상이 늘어난 요구사항에 흡수되어 버린다. 번아웃은 AI를 가장 열심히 쓰는 사람에게 먼저 온다.
좋은 도입의 조건은 간단하다. 베이스라인 먼저 측정하고, 특정 태스크 단위로 시간 단축을 추적하며, 리더십이 데이터 기반으로 기대치를 재보정하는 것. "개발자가 코드 리뷰에서 25% 빠르다. 테스트 작성은 아직 변화 없다."처럼 구체적으로 나눠야 한다. "AI 있으니까 40% 더 해"는 측정도, 관리도 안 되는 기대치다.
기술 스택이 AI의 안전망이 된다
도입 설계와 기대치 관리만으로 충분한가? 아니다. ZenStack 팀의 분석이 세 번째 변수를 꺼낸다. AI 에이전트는 빠르게 코드를 생성하지만, 인증 체크를 빼먹고, 테넌트 필터를 누락하고, 서로 다른 세 가지 이메일 검증 패턴을 만들어낸다. 이 오류들의 공통점은 하나다. 규칙이 암묵적이고 흩어져 있을 때 발생한다.
스택 선택의 기준에 새로운 차원이 추가됐다. 에이전트가 생성한 코드의 실수를 얼마나 구조적으로 잡아낼 수 있는가. TypeScript처럼 강한 타입 시스템은 모델 변경이 전파될 때 컴파일 타임에 오류를 잡는다. Prisma 같은 타입 안전 ORM은 존재하지 않는 필드를 쿼리하는 코드를 구조적으로 막는다. ZenStack처럼 접근 제어 규칙을 스키마 레벨에 선언적으로 두는 방식은 AI가 새 엔드포인트를 만들어도 권한 체크를 우회할 수 없게 만든다.
요점은 이것이다. 규칙이 코드 곳곳에 패턴으로 흩어져 있으면 LLM은 그 패턴을 통계적으로 근사할 뿐이고, 근사는 틀린다. 하나의 스키마 파일에 데이터 모델·접근 정책·검증 규칙이 집중되어 있으면 에이전트도 맥락 전체를 읽고 더 정확한 코드를 낸다.
세 가지 설계가 맞물려야 한다
세 가지 신호가 결국 같은 방향을 가리킨다. AI 코딩 도구의 팀 정착은 도구 선택 이후의 문제다. 4주 온보딩 설계로 이용률을 끌어올리고, 리더십 기대치를 데이터 기반으로 조율하며, 기술 스택을 AI 오류의 안전망으로 설계하는 것—이 세 레이어가 맞물릴 때 비로소 도구가 팀에 뿌리를 내린다.
테크 리드로서 내일 당장 쓸 수 있는 체크리스트는 세 가지다. 첫째, pre-PR 리뷰를 앵커 워크플로우로 고정하고 4주 온보딩 캘린더를 잡는다. 둘째, AI 도입 전 특정 태스크 베이스라인을 측정하고 리더십과 30일 후 기대치를 합의한다. 셋째, 접근 제어와 비즈니스 규칙이 선언적으로 집중된 스택 구조인지 점검한다. 이 세 가지가 없다면 아무리 좋은 모델을 붙여도 팀은 2주차에 조용히 이전 방식으로 돌아간다.