프로덕션 환경에서 생성형 AI(GenAI) 시스템을 운영할 때 가장 경계해야 할 것은 '감(Vibes)'에 의존하는 프롬프트 엔지니어링입니다. 수작업으로 ChatGPT 콘솔에 프롬프트를 입력해보고 만족하는 방식은 정량적 데이터가 부재한 맹목적 최적화에 불과합니다. 프롬프트는 단순한 문자열이 아니라 AI의 행동, 안전성 가이드라인, 출력 형식을 제어하는 핵심 로직입니다. 이를 일반 코드처럼 취급하여 깃(Git) 저장소에 하드코딩할 경우, 출력 품질이 저하되었을 때 버전 비교(Diff)나 롤백, 정확한 지연 시간(Latency) 추적이 불가능해지는 '프롬프트 버전 관리 병목'에 직면하게 됩니다.
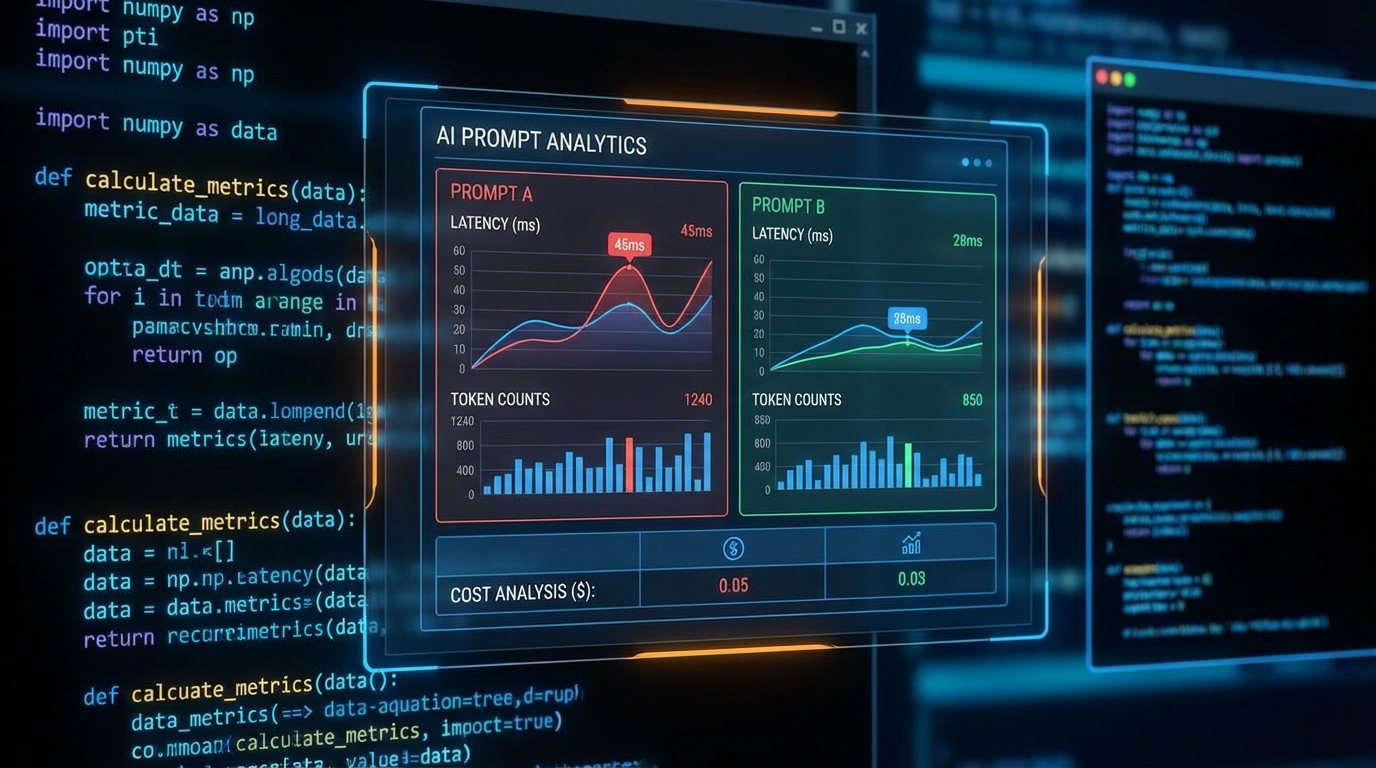
dev.to에 소개된 오픈소스 파이썬 CLI 툴 'Promptlab'의 벤치마크 사례는 데이터 중심 접근의 중요성을 명확히 보여줍니다. 동일한 작업을 수행하는 3개의 프롬프트 변형(예: 격식 있는, 친근한, 간결한)을 테스트했을 때, '격식 있는(Formal)' 프롬프트가 '간결한(Concise)' 프롬프트보다 유사한 품질을 내면서도 토큰 비용을 3배 더 소모할 수 있다는 점이 데이터로 입증되었습니다. 또한, GPT-4o-mini 모델이 GPT-4o 대비 10%의 비용으로 90%의 타깃 품질을 달성할 수 있다는 비용-성능 트레이드오프(Cost-Performance Trade-off)도 확인됩니다. 밀리초(ms) 단위의 응답 시간, 입력/출력 토큰 수, 예상 비용을 독립적으로 측정하지 않으면, '가장 결과물이 좋은 프롬프트'가 프로덕션 환경의 P99 지연 시간을 훼손하는 주범이 될 수 있습니다.
이러한 정량적 테스트가 단발성에 그치지 않으려면 체계적인 LLMOps 파이프라인이 필수적입니다. 최근 dev.to에서 분석한 프롬프트 버전 관리 플랫폼(Maxim AI, LangSmith, Promptfoo 등)의 아키텍처는 이를 뒷받침합니다. 특히 CLI 기반으로 기존 CI/CD 파이프라인에 통합되어 YAML 파일로 프롬프트와 테스트 케이스를 관리하는 Promptfoo나, 재사용 가능한 '프롬프트 파셜(Prompt Partials)'을 지원하는 Maxim AI의 접근은 매우 실무적입니다. 톤 앤 매너나 안전성 가이드라인 같은 공통 컨텍스트를 파셜로 모듈화({{partials.brand-voice.v1}})하면, 수십 개의 프롬프트에 중복 주입되어 발생하는 컨텍스트 윈도우 낭비를 막고 일관된 수정이 가능해집니다.
결론적으로, 프로덕션 환경에서 프롬프트 배포는 애플리케이션 코드 배포와 완전히 분리되어야 합니다. 라이브 트래픽의 일부를 새로운 프롬프트 버전에 라우팅하여 A/B 테스트를 수행하고, 이 과정에서 발생하는 ROUGE, BERTScore 등 Human evaluation 대용 메트릭스와 실제 지연 시간을 통계적으로 유의미한 수준에서 검증해야 합니다. 주관적 체감에 의존하던 프롬프트 작성의 시대는 끝났습니다. 앞으로의 RAG 및 에이전트 시스템 경쟁력은 프롬프트 변형에 따른 토큰 효율성 변화를 얼마나 정밀하게 추적(Tracing)하고, 비용-성능의 교차점을 데이터로 입증할 수 있는 파이프라인의 유무에 달려 있습니다.