AI 에이전트를 제품에 붙이는 순간, LLM 호출은 더 이상 ‘기능 구현’이 아니라 성장(Activation·Retention) 관문이 됩니다. 단일 프로바이더 장애/레이트리밋/지역 이슈는 사용자에게 에러·지연으로 노출되고, 그 즉시 온보딩 흐름의 신뢰를 무너뜨려 전환율을 깎습니다. 동시에 에이전트가 쓰는 도구(MCP 등) 공급망이 오염되면 “우리 제품이 데이터를 훔친다”는 리스크로 번져 CAC를 폭발시킵니다.
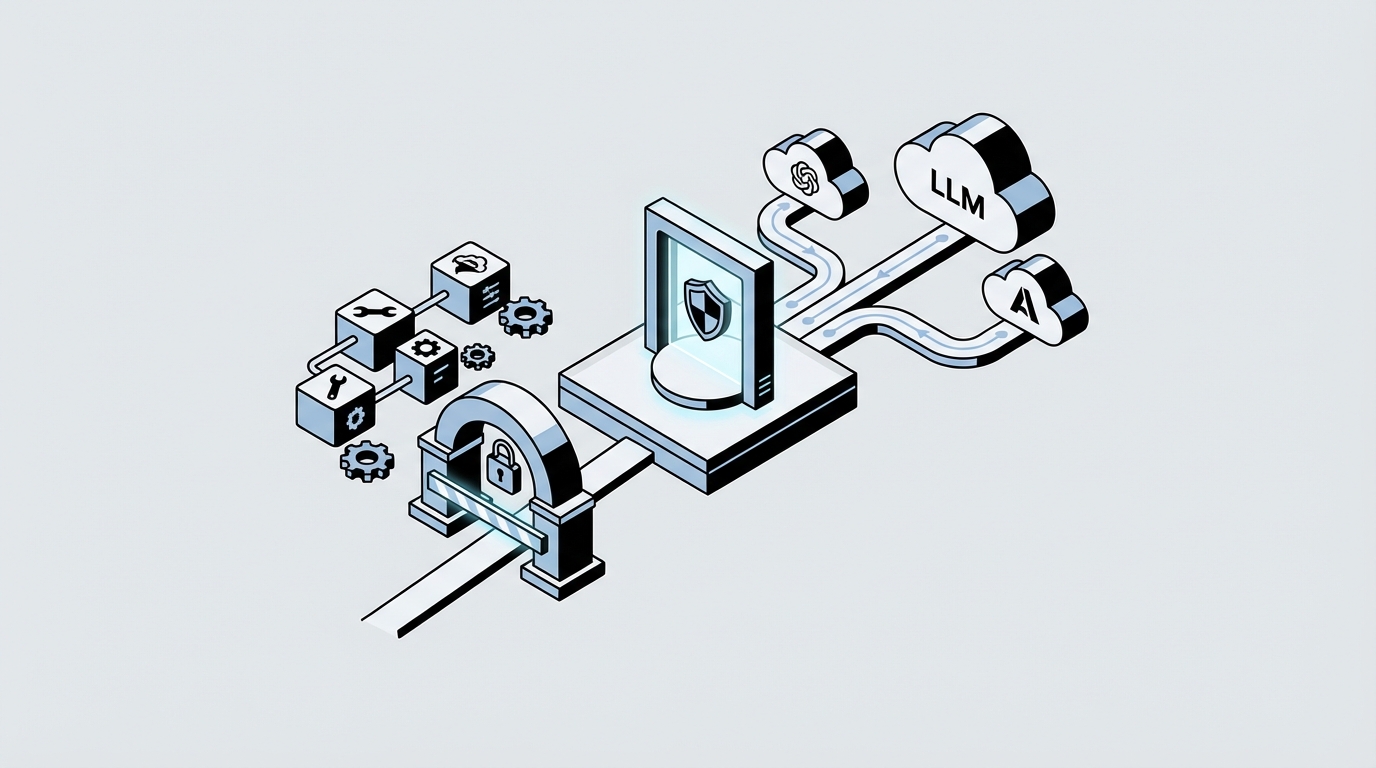
dev.to의 LiteLLM 라우팅 글은 이 병목을 아주 직설적으로 보여줍니다. 한 곳(OpenAI 등)에만 붙어 있으면 그 업체의 업타임이 곧 우리 SLA의 سق(천장)이고, 장애가 곧바로 사용자 오류로 번역됩니다. 저자가 말하는 핵심은 간단합니다: 하나의 인터페이스로 여러 모델을 묶고, 자동 페일오버/비용 기반/지연 기반 라우팅을 걸어라. 즉, 웹에서 DB·CDN 다중화가 상식이듯 LLM도 “단일 호출”을 버려야 프로덕션이 됩니다(출처: dev.to, LiteLLM 라우팅 아티클).
문제는 여기서 끝나지 않습니다. 또 다른 dev.to 글(보안 연구자 Socket의 공개를 인용)은 SANDWORM_MODE 캠페인이 npm 패키지로 침투 → MCP 서버를 끼워 넣고 → 툴 description에 프롬프트 인젝션을 심어 → 코딩 에이전트가 비밀키를 읽고 유출하게 만드는 흐름을 설명합니다. 공격자가 개발자 대신 에이전트의 툴-콜 파이프라인을 장악하는 방식으로 진화했다는 점이 핵심입니다(출처: dev.to, MCP 공급망 위협 아티클).
이 두 이야기는 따로가 아니라, 제품 관점에선 같은 한 문장으로 합쳐집니다. “에이전트 관문이 깨지면 성장 퍼널이 같이 깨진다.” 장애/지연은 즉시 Activation을, 공급망/보안 사고는 Retention과 브랜드 신뢰를 무너뜨립니다. 그리고 이 둘은 공통적으로 ‘에이전트 호출 레이어’에 집중되어 있습니다. 즉, 멀티 모델 라우팅(가용성·비용)과 MCP 공급망 보안(신뢰)을 하나의 게이트웨이 레이어로 설계해야 합니다.
시사점은 실행 과제로 떨어집니다. 첫째, 라우팅을 단일 코드 경로로 표준화하세요. LiteLLM 같은 라우터/어댑터 계층을 두고 (1) 자동 페일오버, (2) 비용 기반 라우팅, (3) 지연 기반 라우팅을 기본값으로 겁니다. 이때 KPI는 기술지표가 아니라 성장지표로 잡아야 합니다: 온보딩 단계 P95 응답시간, 에러율, D1 리텐션, 결제 전환률, 그리고 LLM COGS/활성 사용자가 같이 움직이는지 봐야 합니다.
둘째, 툴 파이프라인(MCP) 자체를 ‘보안-리뷰 대상’으로 승격시키세요. MCP 설정 파일을 권한·버전관리·리뷰 체계에 넣고, 신규/변경 MCP 서버 등록은 코드리뷰 없이 못 들어오게 막아야 합니다. 특히 “툴 description은 신뢰할 수 없다”를 전제로, (a) 허용 도구 allowlist, (b) 도구별 capability 최소화, (c) 민감 파일/토큰 접근 차단 규칙, (d) 에이전트 툴콜 로깅·감사를 관문 레이어에서 강제하는 게 현실적인 방어선입니다.
셋째, 비용·안정성·신뢰를 같은 실험판에서 A/B 테스트로 검증해야 합니다. 예를 들어 ‘기본은 저가 모델 + 복잡도 라우팅으로 상향’(LiteLLM의 smart tiering 아이디어)으로 COGS를 낮추되, 특정 태스크에서 오답/재시도 증가로 UX가 나빠져 리텐션이 떨어지지 않는지 함께 봐야 합니다. 반대로 보안 하드닝으로 툴콜 단계가 늘어 지연이 증가하면 Activation이 깎일 수 있으니, 보안 체크의 위치(클라이언트/게이트웨이/서버)와 캐싱 전략까지 포함해 실험 설계를 해야 합니다.
전망은 명확합니다. AI 에이전트가 제품의 ‘기능’에서 ‘운영체제’로 이동할수록, 시장은 두 가지 팀만 빠르게 성장시킬 겁니다. (1) 멀티 프로바이더 라우팅으로 장애·단가·지연을 흡수해 사용자 체감 품질을 안정화하는 팀, (2) MCP 같은 도구 공급망을 제품 신뢰 인프라로 다루며 사고 확률과 사고 반경을 최소화하는 팀. 결국 승부는 “더 똑똑한 모델”이 아니라, 관문 레이어를 잘 설계해 CAC를 낮추고 LTV를 지키는 팀에서 납니다.