대규모 언어 모델(LLM)의 프로덕션 배포에서 가장 큰 병목은 항상 VRAM 점유율과 추론 시의 부동소수점 연산(FLOPs) 비용이었습니다. 기존의 4-bit 또는 8-bit 사후 양자화(Post-Training Quantization, PTQ) 기법은 모델 압축에는 기여했지만, 여전히 행렬 곱셈(MatMul) 연산의 굴레를 벗어나지 못해 성능 하락과 에너지 소비라는 트레이드오프를 강제했습니다. 이 맥락에서 최근 dev.to 및 GeekNews를 통해 공유된 Microsoft Research의 1-bit LLM 아키텍처 'BitNet b1.58 2B' 모델과 전용 추론 프레임워크 'bitnet.cpp'의 공개는, 단순한 경량화를 넘어선 연산 패러다임의 구조적 전환을 보여주는 중요한 데이터 포인트입니다.
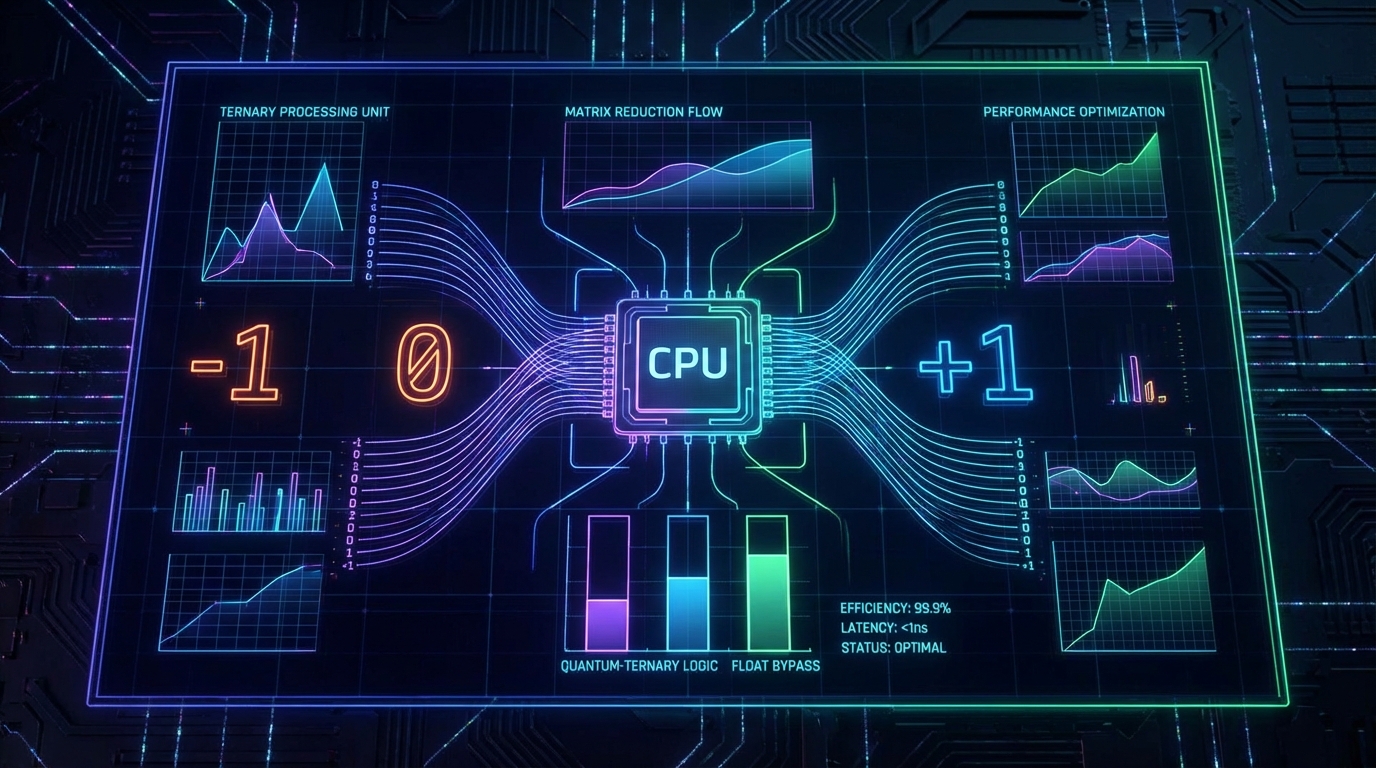
BitNet의 핵심은 가중치를 사후에 압축하는 것이 아니라, 초기 학습 단계부터 3진수(Ternary: {-1, 0, +1})로 제약하는 'Native 1.58-bit(log₂(3) ≈ 1.58)' 학습 아키텍처를 채택했다는 점입니다. 공개된 벤치마크 데이터를 살펴보면, 이 접근법이 만들어내는 비용-성능 지표는 압도적입니다. 2.4B 파라미터(4T 토큰 학습)를 지닌 BitNet b1.58은 추론 시 단 0.4GB의 메모리만 점유합니다. 이는 2GB를 요구하는 Llama 3.2 1B 대비 1/5 수준이며, CPU 지연 시간(Latency) 역시 29ms로 Qwen 2.5 1.5B(65ms)의 절반 이하입니다. 가장 주목할 만한 메트릭은 1회 추론당 에너지 소비량으로, Qwen이 0.347J을 소모하는 반면 BitNet은 0.028J만을 소비하여 약 12배의 에너지 효율성을 달성했습니다. 그럼에도 불구하고 GSM8K 벤치마크에서 58.38점을 기록하며 풀 정밀도(Full-precision) 모델들을 상회하는 성능을 입증했습니다.
이러한 극단적인 효율성은 BitLinear 레이어의 연산 구조에서 기인합니다. 가중치가 {-1, 0, +1}로 고정됨에 따라, 컴퓨팅 파이프라인에서 가장 무거운 부동소수점 곱셈이 완전히 제거되고 단순 덧셈과 뺄셈으로 치환됩니다. 이는 곧 메모리 대역폭의 병목을 해소하고 레지스터 활용도를 극대화함을 의미합니다. Microsoft가 공식 배포한 C++ 기반 추론 프레임워크 bitnet.cpp는 이 구조를 십분 활용합니다. ARM 아키텍처에서 1.37배~5.07배, x86 아키텍처에서는 2.37배~6.17배의 추론 속도 향상과 함께 최대 82.2%의 에너지 절감을 기록했습니다. 통계적으로 유의미한 이 수치들은, GPU가 아닌 일반 소비자용 CPU 환경에서도 P99 지연 시간을 상용 수준으로 통제할 가능성을 시사합니다.
그러나 시스템을 설계하는 엔지니어의 관점에서, 환호 이면에 존재하는 제약 사항을 비판적으로 검증해야 합니다. 첫째, 소프트웨어 의존성입니다. Hugging Face의 기본 transformers 라이브러리를 통해 모델을 호출할 경우, 특화된 삼진 연산 커널이 작동하지 않아 속도나 전력 이점을 전혀 누릴 수 없습니다. 둘째, Throughput 관점의 한계입니다. 단일 CPU에서 100B 파라미터 모델을 구동할 수 있다는 점은 아키텍처의 유연성을 증명하지만, 초당 5~7토큰(Tokens/sec)의 생성률은 인간의 평균 읽기 속도조차 밑도는 수치입니다. 프로덕션 환경에서 실시간 스트리밍 타임아웃을 방지하고 사용자 경험을 담보하기 위해서는 최소 15~20 tokens/sec 이상의 처리량이 요구되므로, 100B급 로컬 서빙은 아직 실무적이라기보다 개념 증명(PoC)에 가깝습니다.
결론적으로 BitNet 아키텍처는 클라우드 GPU의 VRAM 증설에 의존해온 기존의 추론 스케일링(Inference Scaling) 법칙에 균열을 내는 유의미한 성과입니다. 부동소수점을 버리고 정수 덧셈만으로 회귀한 이 방법론은, 향후 NPU(Neural Processing Unit)나 1-bit 전용 ASIC과 결합될 때 비로소 진가를 발휘할 것입니다. 오프그리드(Off-grid) 환경이나 엣지 디바이스에서 RAG 파이프라인의 로컬 Retrieval 및 요약을 수행해야 하는 시스템 아키텍트라면, 기존 4-bit 모델의 P99 지연 시간과 BitNet 1.58-bit의 CPU 레이턴시 간의 트레이드오프를 A/B 테스트를 통해 지금 당장 정량적으로 측정해 볼 시점입니다.