v0.dev에서 Tailwind 클래스가 달린 React 컴포넌트가 뚝딱 생성되는 장면은 분명 마법처럼 보인다. 하지만 그 마법을 프로덕션 에이전트 워크플로우에 연결하는 순간, 많은 개발자들이 같은 벽에 부딪힌다. 빨간 에러 화면, 터진 컨텍스트 윈도우, 그리고 예상보다 훨씬 무거운 토큰 비용. 이 세 가지는 사실 같은 뿌리에서 나온다.
LLM이 React 코드를 생성할 때 벌어지는 일
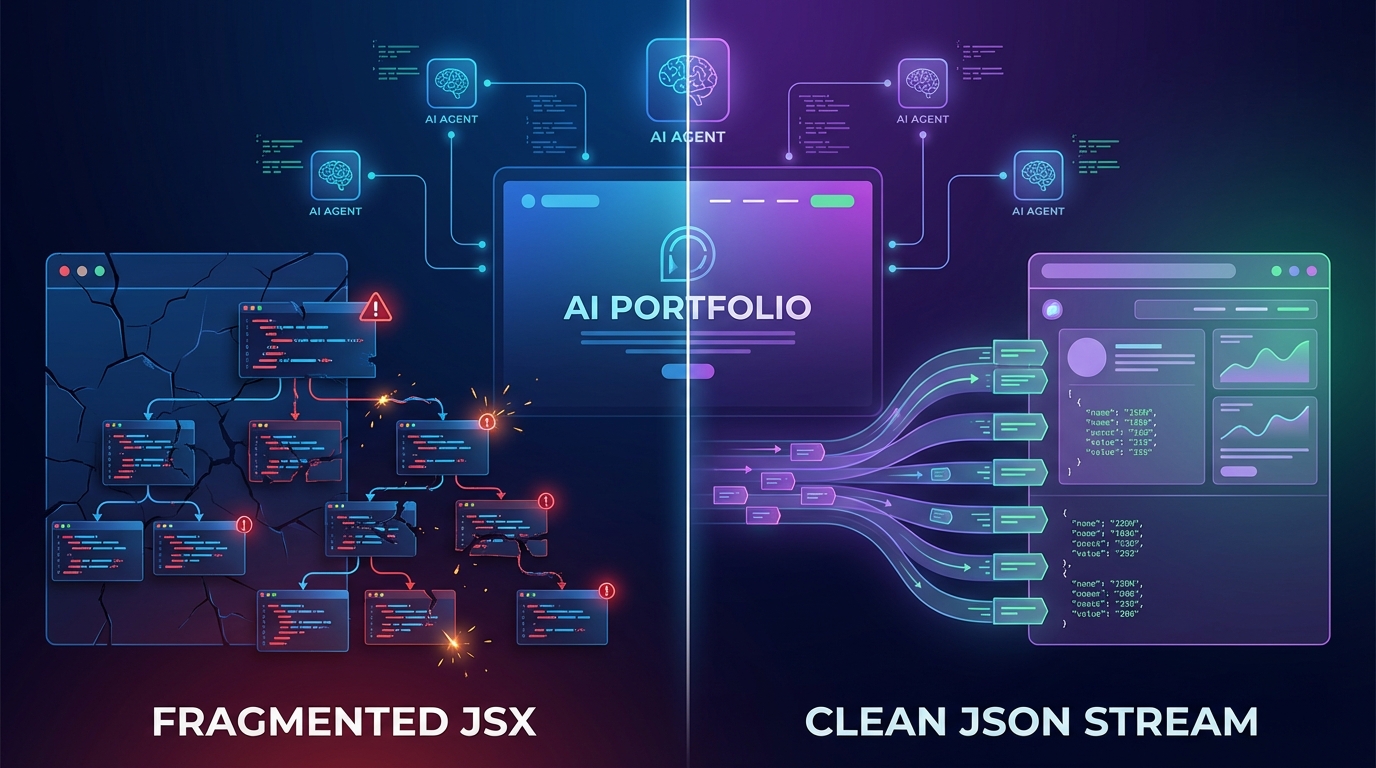
dev.to에 게재된 'Why asking LLMs to generate React/Nested code is a dead end for Agent UI'는 이 문제를 '환각세(Hallucination Tax)'라는 개념으로 정확히 짚는다. LLM은 본질적으로 선형 시퀀스 예측기다. 깊이 중첩된 JSX 트리를 생성하도록 강제할수록, 모델의 어텐션 리콜은 AST 깊이에 반비례해 저하된다. </div> 하나가 빠지거나 props 객체에 쉼표 하나가 누락되면 전체 컴포넌트 트리가 파싱 에러로 무너진다. 구조적으로 용납이 없는 코드를, 구조를 보장할 수 없는 모델에게 맡기는 역설이다.
더 심각한 문제는 레이턴시다. 중첩 구조는 전체 블록이 닫히고 검증될 때까지 안전하게 렌더링할 수 없다. 스트리밍이 주는 '즉각적인 피드백'이라는 UX적 이점이 완전히 사라지는 것이다. 게다가 닫는 태그, 들여쓰기, 괄호 같은 구조 문자들은 수천 토큰을 소비하면서도 의미를 전달하지 않는다. 이것이 바로 '환각세'의 본질이다.
패러다임 전환: 트리 대신 플랫 스트리밍
해법은 의외로 간단한 질문에서 시작한다. 브라우저 DOM이 어차피 트리라면, LLM도 트리를 스트리밍해야 할까? 답은 'No'다. 스트리밍, 로그 집계, LLM 텍스트 생성에 가장 강건한 자료구조는 플랫 리스트다.
중첩 JSON 대신 각 UI 요소를 독립된 원자 객체로 분리하고, parent 키로 관계를 선언하는 방식이다. { "id": "card_1", "type": "div" }가 스트리밍되는 순간 즉시 렌더링하고, 이후 { "id": "title_1", "parent": "card_1", "type": "h1" }이 뒤따르는 구조다. 만약 title_1 객체가 손상되더라도 card_1은 멀쩡하다. 에러가 격리(isolate)되고, UI는 전체 폭발 없이 부분 저하(graceful degradation)된다.
이 아이디어를 실제 엔진으로 구현한 것이 JSOMP(JSON-Standard Object Mapping Protocol)다. 15kb의 프레임워크 무관 런타임으로, LLM 스트림과 UI 라이브러리 사이에서 실시간 AST 자동 복구를 수행한다. 클릭 핸들러도 onClick={() => fetch(...)} 같은 위험한 eval 코드 대신 "actions": { "submit": ["onClick"] } 형태의 순수 JSON으로 선언한다. 프론트엔드 엔지니어가 실행 환경에 대한 통제권을 잃지 않으면서도, LLM이 UI를 안전하게 조작할 수 있는 구조다. 2,000개 노드 렌더링이 20ms 이내, 단일 속성 변경이 1ms 미만이라는 수치는 이 접근이 성능 면에서도 현실적임을 보여준다.
포트폴리오를 기계가 읽도록 설계한다는 것
한편 전혀 다른 각도에서 'AI 친화적 설계'를 실천한 사례가 있다. dev.to의 'I Made My Portfolio Site AI-Agent-Ready'는 포트폴리오 사이트를 AI 에이전트가 직접 탐색하고 서비스를 발견할 수 있는 구조로 재설계한 경험을 공유한다. 핵심 통찰은 단순하다. 대부분의 사이트가 AI 크롤러를 차단하는 지금, 적극적으로 환영하는 것 자체가 차별점이 된다.
구체적으로는 7개의 파일을 추가했다. robots.txt로 GPTBot, ClaudeBot 등 주요 AI 크롤러를 명시적으로 허용하고, llms.txt로 LLM이 '나는 누구인가'를 즉시 파악할 수 있는 기계 가독형 브리핑 문서를 제공한다. .well-known/agent-card.json은 Google의 A2A(Agent-to-Agent) 프로토콜에 따라 에이전트가 어떤 서비스를 제공하는지 선언하고, .well-known/mcp.json은 Anthropic의 MCP(Model Context Protocol) 표준으로 호출 가능한 도구를 기술한다. 프레임워크도 불필요하다. 정적 파일 몇 개로 Vercel, Netlify, GitHub Pages 어디서든 동작한다.
이 접근의 의미는 단순한 SEO 확장을 넘어선다. Google Search가 사람의 검색 의도를 연결했다면, A2A 에이전트 인덱스는 AI가 다른 AI를 위해 서비스를 탐색하는 새로운 발견 레이어다. 내 포트폴리오가 'AI 에이전트 생태계에서 발견되는가'는 조만간 'Google에서 검색되는가'만큼 중요한 질문이 될 것이다.
에이전트가 UI를 직접 제어하는 포트폴리오
세 번째 사례는 더 나아가 AI가 UI를 능동적으로 조작하는 포트폴리오를 구현한다. React 19, Vite, Google Gemini 2.5 Flash로 구축된 이 포트폴리오에서 AI 챗봇은 단순 Q&A를 넘어 Function Calling으로 프론트엔드 상태를 직접 제어한다. 사용자가 "웹 개발 프로젝트 보여줘"라고 말하면 Gemini가 의도를 파악해 filterProjects 함수를 호출하고, 프로젝트 갤러리가 실시간으로 필터링된다. "다크 모드로 전환해"는 toggleTheme으로, "경력 섹션으로 이동해"는 scrollToSection으로 매핑된다.
주목할 만한 설계 결정은 콘텐츠 중앙화다. 모든 프로젝트, 경력, 스킬 데이터를 단일 constants.ts 파일에서 관리하면서 UI 전체가 이 데이터에서 파생된다. AI가 콘텐츠를 참조하거나 업데이트해야 할 때 단일 진실의 원천(Single Source of Truth)이 명확하다는 것은 에이전트 통합의 안정성을 높이는 실용적 선택이다. WCAG 2.1 AA 접근성 준수와 화려한 glassmorphism 디자인을 동시에 유지한 점도, '에이전트 친화적'과 '사람 친화적'이 대립하지 않음을 보여준다.
프론트엔드가 다시 설계해야 할 질문
세 가지 사례가 가리키는 방향은 하나로 수렴한다. AI 에이전트 시대의 프론트엔드는 '사람이 보는 UI'와 '에이전트가 읽는 인터페이스'를 동시에 설계해야 한다. 이는 두 개의 UI를 만드는 것이 아니라, 설계 원점을 다시 세우는 문제다.
LLM의 구조적 특성을 거스르지 않는 플랫 데이터 프로토콜, 에이전트가 발견하고 호출할 수 있는 기계 친화적 파일 레이어, 그리고 AI가 UI 상태를 안전하게 제어할 수 있는 선언적 함수 스키마. 이 세 가지는 각각 독립된 기법이 아니라 하나의 설계 철학의 다른 표현이다. 에이전트의 한계를 설계로 보완하고, 에이전트의 강점이 흐를 수 있는 통로를 구조 안에 만들어두는 것.
'AI가 UI를 만드는 시대'는 이미 도래했다. 그러나 AI가 만들기 좋은 UI를 설계하는 것은, 여전히 사람의 몫이다. 그 설계를 먼저 고민한 팀과 개발자가 에이전트 생태계의 첫 번째 수혜자가 될 것이다.