프로덕션 환경에서 생성형 AI 시스템을 운용할 때 마주하는 가장 치명적인 병목은 '행동 표류(Behavioral Drift)'입니다. 최근 개발자 커뮤니티 dev.to에 공유된 DriftWatch 구축 사례에 따르면, Google의 Gemini 1.5 Pro와 Anthropic의 Claude 3.5 Sonnet과 같은 SOTA 모델들이 버전 식별자 변경 없이 암묵적 업데이트를 단행하며 출력 포맷을 훼손하는 현상이 정량적으로 확인되었습니다. API 가동률(Uptime)은 99.9%를 가리키고 시스템 프롬프트는 단 한 글자도 바뀌지 않았음에도, 특정 시점을 기준으로 JSONDecodeError나 파싱 실패율이 급증하는 이른바 '조용한 회귀(Silent Regression)'가 발생하고 있는 것입니다.
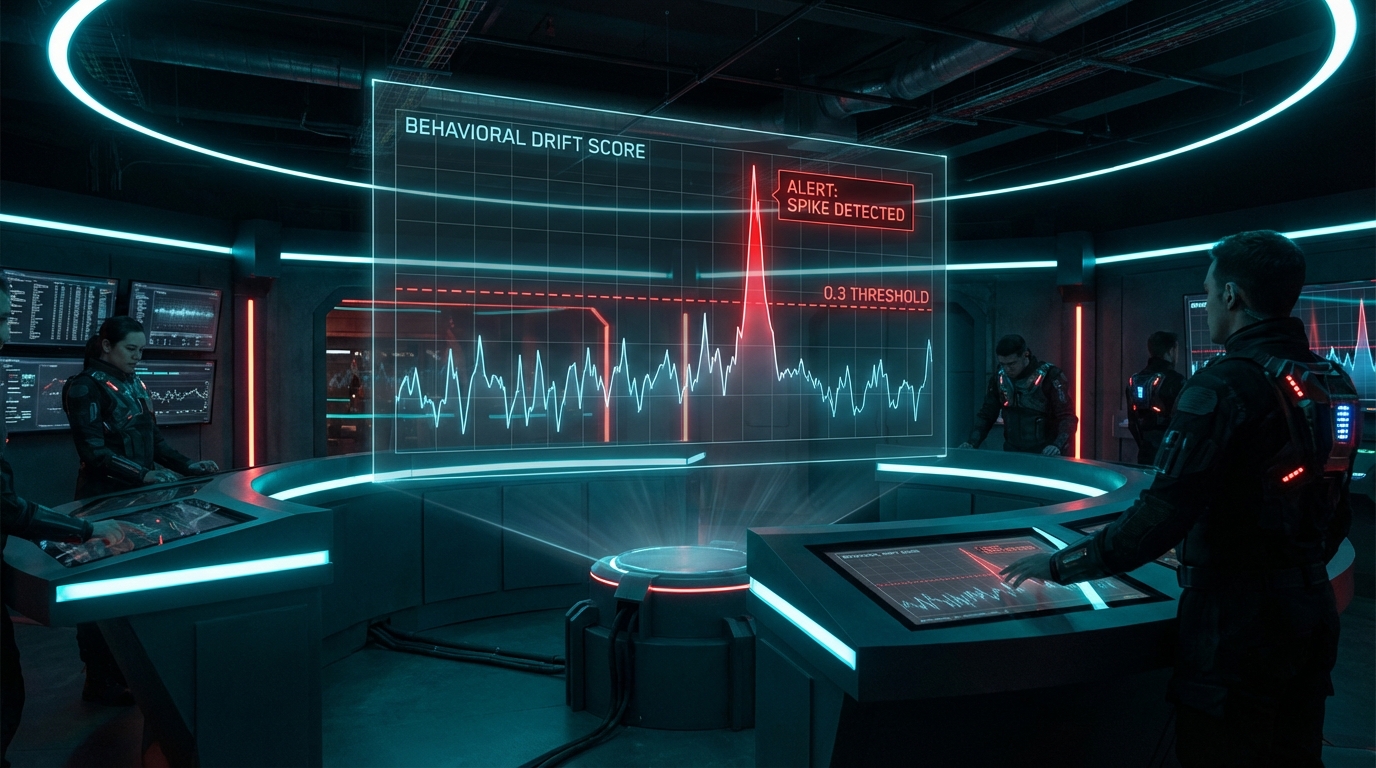
현상을 데이터로 뜯어보면 사태의 심각성이 더욱 명확해집니다. 실험 결과에 따르면, gemini-1.5-pro-002와 같이 고정된(Pinned) 모델조차 3주간 0.05~0.08 수준의 안정적인 드리프트 점수를 유지하다가 불과 36시간 만에 0.31로 급등했습니다. 순수 코드만 요구한 프롬프트에 마크다운 래퍼(Wrapper)를 씌우거나, 구조화된 JSON 데이터 추출 시 "Here is the extracted data:"라는 서문(Preamble)을 15~20%의 확률로 삽입하는 식입니다. 이는 모델 제공자의 A/B 테스트나 안전성 파인튜닝(Safety Fine-tuning)이 서버 사이드에서 적용되며 나타나는 전형적인 간섭 효과입니다. 결과적으로 다운스트림 파이프라인에서 정규표현식이나 json.loads()에 의존하는 애플리케이션은 즉각적인 시스템 에러와 P99 지연 시간 붕괴를 겪게 됩니다.
이 지점에서 우리는 LangSmith나 Helicone 같은 기존 LLMOps 추적(Tracing) 도구의 맹점을 비판적으로 짚고 넘어가야 합니다. 단순한 로깅과 레이턴시 모니터링만으로는 기준점(Baseline, $T_0$) 대비 현재($T_n$)의 '의미론적 변위'를 측정할 수 없습니다. 신뢰할 수 있는 데이터 파이프라인을 구축하기 위해서는 프롬프트 의존성을 낮추는 동시에, 정량적인 행동 기준선을 확립해야 합니다. 핵심 프롬프트의 기준 응답을 캐싱하고, 문장 임베딩(Sentence Transformer) 모델을 활용해 주기적으로 코사인 유사도(Cosine Similarity) 및 포맷 준수율을 측정해야 합니다. 측정된 드리프트 점수가 0.3을 초과하면 조사 알람을 발생시키고, 0.5를 초과하면 즉각적인 라우팅 차단 및 Fallback 모델로 스위칭하는 확정적(Deterministic) 통제 레이어가 필수적입니다.
단일 API 버전에 절대적으로 의존하는 낭만적인 시대는 끝났습니다. 앞으로의 LLM 애플리케이션 아키텍처는 모델의 성능과 행동 패턴을 정적인 상수로 취급하지 않고, 동적인 확률 변수로 다루는 방향으로 진화할 것입니다. 모델 드리프트는 벤더사의 배포 파이프라인이 존재하는 한 계속될 상수적 위협입니다. 따라서 ML 엔지니어링 조직은 감(Vibes)이나 우연에 의존한 프롬프트 덧대기식 수정을 멈추고, 시맨틱 평가 지표에 기반한 실시간 드리프트 모니터링과 동적 에이전트 라우팅 전략을 통해 시스템의 강건성(Robustness)을 스스로 증명해야만 합니다.