Claude의 컨텍스트 윈도우가 1M 토큰으로 확장됐다. Anthropic은 최근 Claude Code와 Opus 4.6에서 1M 컨텍스트를 정식 지원하면서, 추가 요금도 없고 rate limit 감소도 없다고 발표했다. 모델이 한 번에 처리할 수 있는 텍스트의 양이 사실상 무제한에 가까워진 것이다. 그런데 이 뉴스를 보면서 나는 모델 성능보다 다른 쪽을 먼저 떠올렸다. 그 길어진 응답을 화면에 어떻게 보여줄 것인가.
응답이 길어진다는 것은 단순히 텍스트가 많아진다는 뜻이 아니다. 스트리밍 청크가 더 오래 이어지고, 마크다운 구조가 더 복잡해지며, 사용자가 스크롤을 올렸다 내렸다 하는 시간이 늘어난다는 뜻이다. 모델의 역량이 커질수록 UI가 감당해야 할 엣지 케이스도 함께 늘어난다. 최근 한 개발자가 velog에 공유한 AI 채팅 UI 구현기는 이 문제를 정면으로 파고든 글이었다. 읽으면서 '맞아, 이거 생각보다 훨씬 복잡하지'를 연발했다.
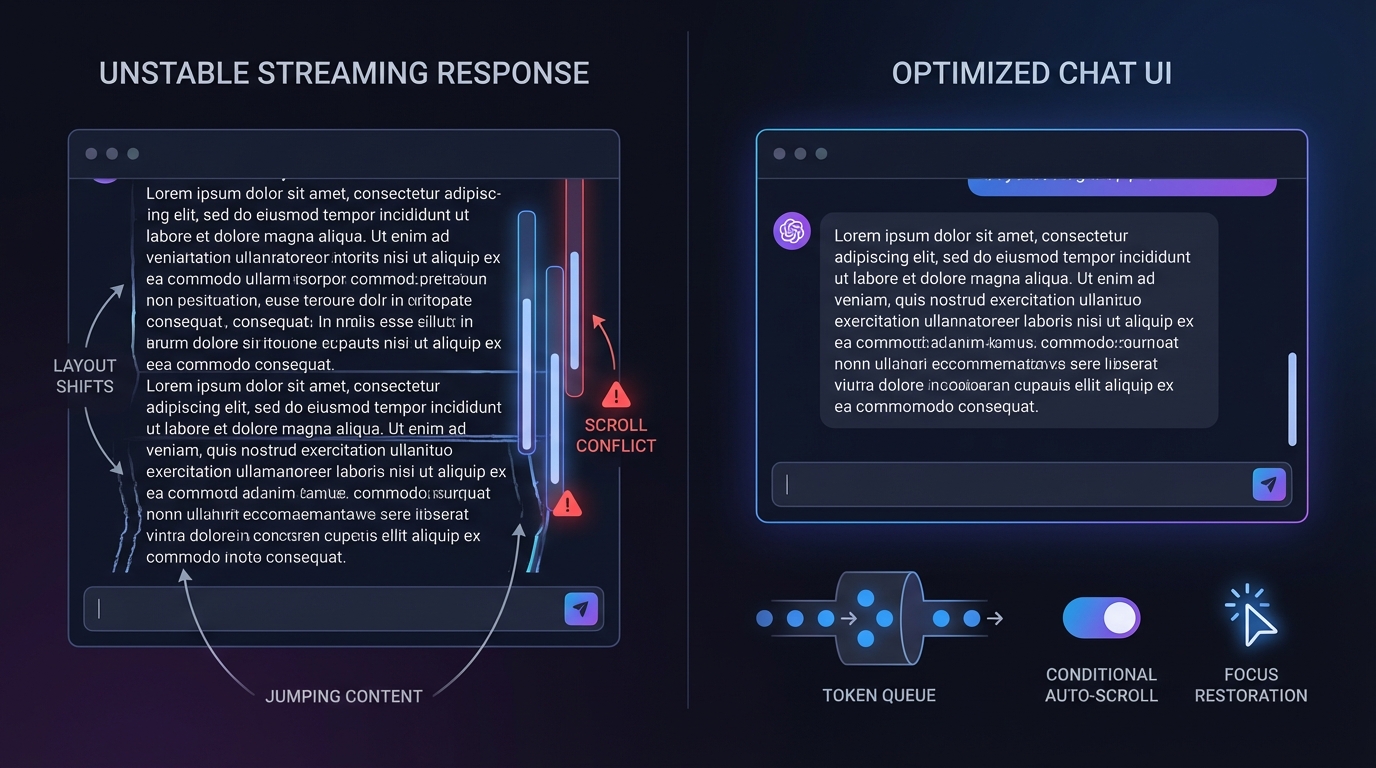
자동 스크롤은 편의 기능이 아니다
가장 먼저 부서지는 건 스크롤이다. 초기 구현은 단순하다. 새 청크가 들어올 때마다 스크롤을 맨 아래로 고정하면 된다. 개발 단계에서는 잘 동작한다. 문제는 응답이 길어질 때 시작된다. 사용자가 앞서 지나간 문장을 다시 읽으려고 위로 올리는 순간, 다음 청크가 도착하면서 화면이 강제로 끌려 내려간다. 시스템이 보여주려는 위치와 사용자가 읽고 싶은 위치가 충돌하는 것이다.
해결책은 '사용자가 의도적으로 위를 읽고 있는 상태'를 구분하는 것이다. 바닥 근처에 있을 때만 자동 스크롤을 유지하고, 일정 threshold 이상 올라가면 멈춘다. 그런데 여기서 한 가지 함정이 있다. 스크롤 이벤트만으로는 부족하다. 스트리밍 중에는 사용자가 직접 스크롤하지 않아도 콘텐츠가 늘어나면서 scrollHeight가 변한다. 이때 스크롤 이벤트는 발생하지 않는다. 그래서 ResizeObserver로 콘텐츠 영역의 크기 변화까지 함께 감시해야 한다. 스크롤 이벤트는 사용자의 명시적 조작을, ResizeObserver는 스트리밍으로 인한 구조 변화를 각각 담당하는 이중 감시 체계다.
자동 스크롤이 꺼진 상태에서는 '최하단으로 이동' 버튼도 필요하다. 현재 어디까지 응답이 왔는지 모르는 상태에서 직접 끝까지 내려가는 건 사용자에게 불필요한 수고다. 결국 자동 스크롤은 단순한 편의가 아니라 사용자의 읽기 흐름을 해치지 않는 조건부 동작으로 설계되어야 한다.
마크다운이 날리는 레이아웃 시프트
LLM 응답은 단순 텍스트가 아니다. 스트리밍 도중에 평범한 문장으로 시작하던 내용이 코드 블록이나 테이블로 바뀌면서 높이가 갑자기 커진다. 이 레이아웃 시프트가 스크롤 위치를 어색하게 밀어버린다. 일반 채팅 UI라면 신경 쓰지 않아도 될 부분이 LLM 서비스에서는 핵심 UX 문제가 된다.
디테일은 두 가지다. 첫째, 코드 블록의 복사 버튼. 마크다운 렌더러가 코드 블록을 감지하면 복사 버튼을 붙이는데, 스트리밍 중에는 코드가 미완성 상태다. 이때 복사 버튼이 활성화되어 있으면 불완전한 코드가 클립보드에 올라간다. 스트리밍이 끝난 후에만 버튼을 활성화해야 한다. 둘째, 모바일에서의 테이블. LLM이 넓은 테이블을 생성하면 모바일 화면에서 레이아웃이 깨진다. overflow-x-auto 래퍼로 감싸 가로 스크롤을 허용하는 것이 안전한 처리다. 사소해 보이지만 이 두 가지를 놓치면 사용자 신뢰가 조용히 무너진다.
토큰 큐와 SSE 파싱: 보이지 않는 곳의 설계
서버에서 도착하는 토큰을 그대로 화면에 반영하면 응답 속도가 불규칙해 어색하다. 네트워크 상태에 따라 토큰이 한꺼번에 몰려오거나 한 글자씩 느릿느릿 올 때도 있다. ChatGPT처럼 부드럽게 타이핑되는 느낌을 주려면 서버 수신 속도와 화면 출력 속도를 분리해야 한다. 도착한 토큰을 ref 기반 큐에 쌓아두고 setInterval로 일정 간격마다 하나씩 꺼내 렌더링하는 토큰 큐 패턴이 이 문제를 해결한다. 기술적으로 단순하지만 경험 품질의 차이는 크다.
SSE 파싱도 함정이 있다. EventSource API는 GET 요청만 지원하기 때문에, 대화 히스토리나 시스템 프롬프트를 body에 담아야 하는 챗봇에서는 fetch로 스트림을 직접 파싱해야 한다. 문제는 fetch의 ReadableStream이 SSE 이벤트 경계가 아닌 네트워크 패킷 경계로 데이터를 반환한다는 점이다. 한 번의 read()에 이벤트가 중간에 잘려 도착할 수 있다. 청크를 버퍼에 이어 붙이고 \n\n으로 분리하되 마지막 불완전 블록은 버퍼에 남겨두는 처리가 없으면, 로컬에서는 멀쩡하다가 운영 환경에서 간헐적으로 JSON 파싱 에러가 터진다.
한글 조합과 포커스: 마이크로 인터랙션의 무게
한글 입력에서 Enter를 치면 브라우저는 compositionend와 keydown을 거의 동시에 발생시킨다. 타이밍에 따라 조합 중인 문장이 전송되거나 마지막 글자가 누락된다. compositionstart/compositionend로 조합 상태를 감지하고 Enter 전송을 막아야 하는데, 여기서 useState만으로는 부족하다. React의 setState는 비동기적이라 compositionend 직후 keydown 핸들러에서 최신 state가 반영되지 않을 수 있다. useRef와 useState를 함께 두고 이벤트 핸들러에서는 ref를 기준으로 처리하는 패턴이 필요하다.
모바일에서는 Enter가 줄바꿈이고 전송은 버튼으로만 처리하는 분기도 챙겨야 한다. (pointer: coarse) 미디어 쿼리로 터치 디바이스를 감지하면 User-Agent 파싱보다 실용적이다. 그리고 스트리밍이 끝나 disabled가 풀리는 순간 브라우저는 포커스를 자동으로 복원하지 않는다. isSending이 true에서 false로 바뀌는 시점을 감지해 requestAnimationFrame 이후에 포커스를 복원해야 한다. 연속으로 질문을 주고받는 흐름에서 이 포커스 유지가 생각보다 훨씬 중요하다.
컨텍스트가 늘어날수록 UI 설계의 무게도 늘어난다
1M 컨텍스트 시대가 열렸다는 것은 모델이 더 많은 정보를 처리할 수 있다는 의미인 동시에, 사용자가 화면에서 더 오랫동안 스트리밍 응답을 마주한다는 뜻이다. 응답이 길어질수록 스크롤 충돌이 일어날 확률이 높아지고, 마크다운 구조가 복잡해질 가능성도 커지며, 사용자가 중간에 읽기 흐름을 끊을 일도 잦아진다. 모델의 역량 확장이 UI의 복잡도 확장을 동반한다.
지금까지 AI 채팅 UI는 '결과를 보여주는 화면'으로 다뤄졌다. 하지만 실제로 구현해보면 이것은 생성 과정을 실시간으로 제어하는 인터페이스다. 스트리밍을 멈추는 중단 버튼, 조건부 자동 스크롤, 불완전한 상태의 컴포넌트 처리, 포커스 복원까지—이 모든 것이 '응답을 생성하는 동안' 사용자가 겪는 경험을 설계하는 문제다. 모델이 강력해질수록 이 레이어의 설계 무게는 가벼워지지 않는다. 오히려 더 정교해져야 한다.