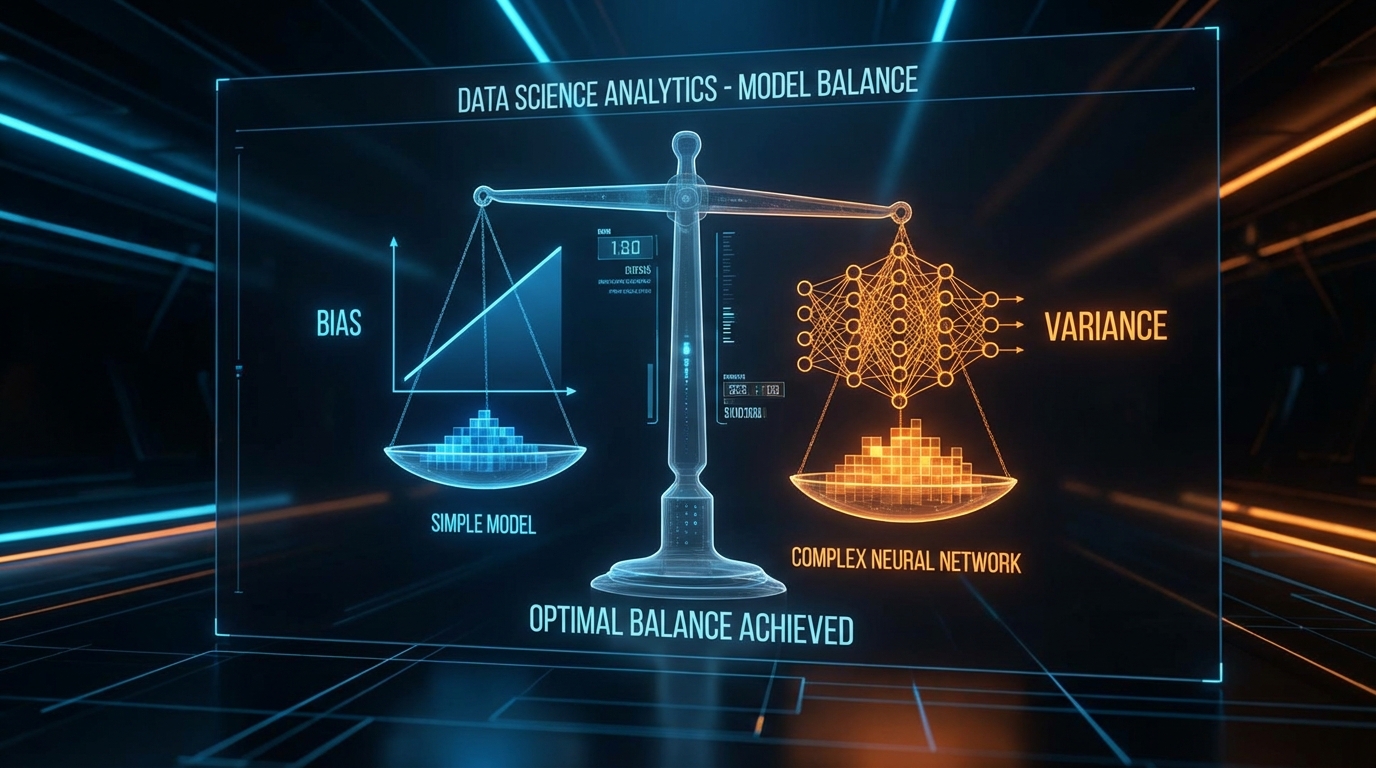
생성형 AI 검출(AI-Generated Text Detection) 시스템을 구축할 때 직면하는 가장 큰 착각은 '학습 데이터에 대한 높은 정확도가 프로덕션 환경의 성능을 보장한다'는 것이다. 하지만 ML 실무에서 단일 모델이 훈련 세트를 암기하는 것은 통계적으로 무의미하다. 핵심은 OOD(Out-of-Distribution) 데이터에 대한 일반화 성능이며, 이는 결국 편향(Bias)과 분산(Variance)의 정량적 통제 문제로 귀결된다. 최근 dev.to에 공유된 'Full-Stack NLP 기반 AI 텍스트 검출기 구축 가이드'와 '머신러닝의 편향-분산 트레이드오프' 아키텍처 분석은 이 이론적 딜레마를 프로덕션 레벨의 앙상블 시스템으로 어떻게 해결하는지 명확한 해답을 제시한다.
해당 프로젝트에서 베이스라인으로 채택된 TF-IDF 기반의 Logistic Regression(20만 개 특성)은 전형적인 고편향-저분산(High-Bias, Low-Variance) 모델이다. 밀리초(ms) 단위의 압도적인 추론 속도를 자랑하지만, 문맥의 미세한 뉘앙스를 포착하기에는 표현력(Expressiveness)이 부족하다. 반면, fp16 혼합 정밀도(Mixed-precision)로 파인튜닝된 DistilBERT 모델은 저편향-고분산(Low-Bias, High-Variance) 영역에 위치한다. 트랜스포머 아키텍처는 깊은 의미론적 관계를 매핑하여 편향을 최소화하지만, 훈련 데이터의 국소적 노이즈까지 학습하여 오버피팅될 위험(분산)이 높고 연산 비용(Computational Cost)이 크다.
이 시스템의 아키텍처적 백미는 두 모델의 트레이드오프를 상쇄하기 위해 도입된 가중치 기반 소프트 보팅(Weighted Soft-Voting) 앙상블이다. 하드 보팅(다수결)이 모델의 신뢰도(Confidence) 정보를 폐기하는 것과 달리, 이 시스템은 P_ensemble = 0.3 × P_baseline + 0.7 × P_transformer라는 확률 기반의 결합 방정식을 채택했다. 이는 분산 감소(Variance Reduction)라는 통계적 원리를 프로덕션에 직접 구현한 것이다. 트랜스포머의 높은 예측력을 주축(0.7)으로 삼되, 선형 모델의 보수적인 예측 궤적(0.3)을 닻(Anchor)으로 활용하여, 특정 데이터셋에 대한 트랜스포머의 과도한 확신(Overconfidence)이 유발하는 분산을 수학적으로 평활화(Smoothing)한다.
프로덕션 서빙 관점에서 이 앙상블 파이프라인의 FastAPI 구현체는 지연 시간(Latency) 최적화의 교과서적 사례를 보여준다. 단일 텍스트 요청 처리의 I/O 병목을 우려하여 최대 64개 텍스트의 배치 추론(Batch Inference) 엔드포인트를 분리한 것은 GPU 활용도를 극대화하는 핵심 설계다. 또한, 응답 페이로드에 단순 라벨(0 또는 1)뿐만 아니라 모델의 추론 지연 시간(ms 단위)과 Type-Token Ratio, 단어 엔트로피(Word Entropy) 같은 형태론적(Stylometric) 특성값을 포함시켰다. 외부 NLP 라이브러리 없이 정규식(Regex) 기반으로 추출된 이 특성들은 신경망의 블랙박스 결과를 검증하는 결정론적(Deterministic) 해석 레이어로 작동한다.
AI 검출 시스템에서 편향-분산 트레이드오프는 한 번 해결하고 끝나는 과제가 아니라, 지속적으로 관리해야 할 동적 제약 조건이다. 새로운 LLM이 출시될 때마다 생성 텍스트의 데이터 분포(Data Drift)는 필연적으로 변화한다. 따라서 API 응답으로 반환되는 클래스별 확률 분포와 지연 시간 데이터는 단순한 로깅 대상이 아니라, 모델의 일반화 성능 저하를 실시간으로 탐지하는 핵심 메트릭으로 취급되어야 한다. 데이터 중심의 MLOps 환경에서는 0.3과 0.7이라는 앙상블 가중치 역시 고정값이 아니라, A/B 테스트와 섀도우 배포(Shadow Deployment)를 통해 P99 지연 시간과 오탐율(False Positive Rate) 간의 상관관계에 따라 동적으로 최적화되는 파라미터로 진화해야 할 것이다.