전면 재작성은 실패한다. 그러면 어떻게 하나?
레거시 코드베이스를 만나면 누구나 한 번쯤 '그냥 다시 짜자'는 충동이 든다. velog 개발자 dasd412의 사례는 그 충동이 왜 위험한지를 정확히 보여준다. 1월에 전면 재작성을 시도했다가, k8s 데몬이 기존 DB 스키마에 강하게 결합되어 있어서 완전히 실패했다. 새 프로젝트로의 전환 자체가 불가능했다.
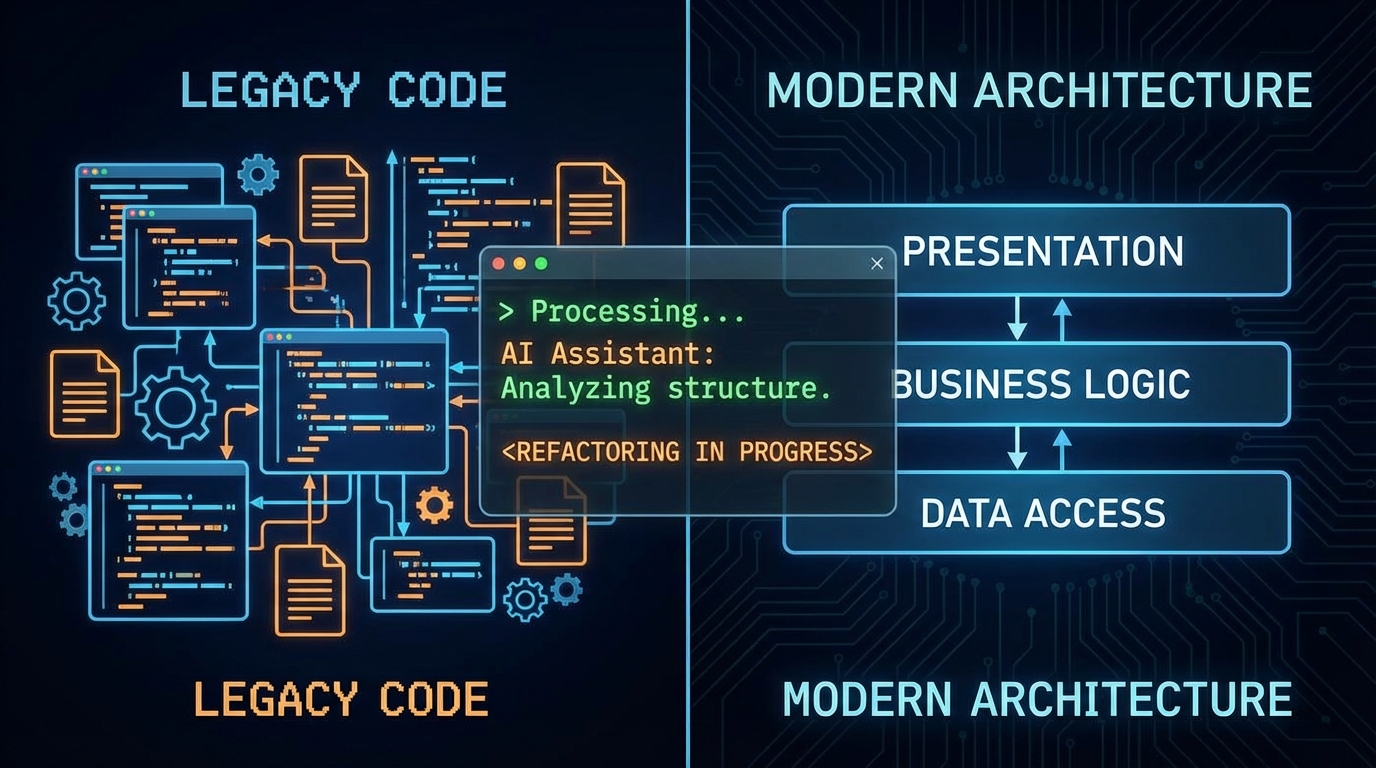
문제는 그 이후다. 재작성은 엎어졌지만 기술 부채는 그대로 남았다. db.py 하나에 5,000줄. 모든 SQLModel 정의와 DTO가 한 파일에 뒤엉켜 있고, 라우터 함수 안에 HTTP 처리·비즈니스 로직·DB 직접 접근이 공존했다. 서비스 레이어라는 개념 자체가 없는 구조였다. API 50개 이상을 운영 중단 없이, 2주 안에, 혼자서 리팩토링해야 했다.
Claude Code가 읽을 수 있는 크기로 먼저 쪼개라
여기서 핵심 통찰이 나온다. AI에게 리팩토링을 맡기려면 AI가 코드를 읽을 수 있어야 한다. 5,000줄짜리 db.py는 Claude Code의 읽기 허용량을 초과해서 분석 자체가 불가능했다. 그래서 모든 작업의 출발점은 db.py를 models/와 schemas/로 분리하고, 각 패키지 안에서 도메인별 파일로 다시 쪼개는 것이었다. 이 단계 하나에만 28커밋이 들었다.
파일 분리가 끝나자 Claude Code가 코드베이스를 정상적으로 읽기 시작했다. 이후 서비스 레이어 도입(50커밋), Repository 레이어 1차·2차 전환이 순차적으로 진행됐다. 최종적으로 grep -r "self.session." server/services/를 돌렸을 때 unit_of_work.py를 제외하고 0건. 서비스 레이어에서 세션을 직접 건드리는 코드가 완전히 사라진 걸 확인했다. 131커밋, 2주.
설계 세션과 실행 세션을 분리하라
Claude Code를 '그냥 쓰는 것'과 '잘 쓰는 것'의 차이는 세션 관리에 있다. dasd412가 설계한 10단계 방법론의 핵심은 설계 컨텍스트와 실행 컨텍스트를 분리하는 것이다. 하나의 세션에서 분석부터 실행까지 모두 처리하면 컨텍스트가 비대해져 AI의 실행 품질이 떨어진다.
실제 프로세스는 이렇다. 설계 세션에서 Claude Code에게 코드베이스를 분석시키고, 의존관계와 위반 패턴을 파악한 뒤 .md 설계 문서를 작성하게 한다. 이 프로젝트에서 작성된 설계 문서는 6개, 총 4,279줄이었다. 그다음 세션을 clear하고 새 세션을 열어서 설계 문서만 읽고 Phase별 코드 변경에만 집중시킨다. 분석 노이즈 없이 실행에만 집중하는 구조다.
사람과 AI의 역할 분담도 명확하다. 사람이 하는 것: 우선순위 판단, 안건 선정, 설계 문서 검토, Docker 빌드, 프론트엔드 교차 검증. AI가 하는 것: 코드베이스 분석, 설계 문서 작성, Phase별 코드 변경, GET baseline 캡처 및 비교, CUD 테스트 스크립트 실행. 판단이 필요한 일은 사람이, 패턴이 반복되는 일은 AI가 담당하는 구조다. Claude Code가 6가지 변환 패턴을 정의해두면 도메인마다 정확하게 반복하는 데 반해, "이 도메인은 전용 Repository가 필요한가"는 비즈니스 로직을 이해해야 판단할 수 있는 문제였다.
1M 컨텍스트 윈도우 정식 출시, 무엇이 달라지나
이 방법론이 등장한 맥락에서 하나의 큰 변수가 생겼다. Anthropic이 Claude Opus 4.6과 Sonnet 4.6에서 100만 토큰(1M) 컨텍스트 윈도우를 표준 요금으로 정식 출시했다. GeekNews에 따르면 별도 프리미엄 없이 9K든 900K든 동일 단가가 적용되며, Claude Code Max·Team·Enterprise 사용자는 자동으로 1M 컨텍스트를 활용할 수 있다. 세션 압축(compaction) 빈도가 줄어들고 대화 유지력이 향상된다는 것이 공식 설명이다.
그런데 여기서 냉정하게 짚어야 할 게 있다. 1M 컨텍스트가 생겼다고 해서 위에서 설명한 세션 분리 전략이 무의미해지는 건 아니다. Hacker News 커뮤니티 반응을 보면 "700k 토큰까지는 괜찮았지만 그 이상부터는 조금씩 둔해지는 느낌이 있었다