LLM 에이전트를 프로덕션에 배포할 때 가장 흔히 범하는 아키텍처 설계의 오류는 '컨텍스트 윈도우의 무한한 확장성'을 맹신하는 것이다. 최근 dev.to에 공유된 에이전트 도구 확장(Tool Scaling) 실험 결과는 이러한 맹신이 초래하는 치명적인 성능 붕괴를 정량적으로 증명한다. Kubernetes API 248개를 툴로 제공했을 때, 모델(qwen3:4b)의 라우팅 정확도는 12%로 급락했다. 8,192 토큰에 달하는 툴 정의서가 컨텍스트 윈도우를 가득 채우며 에이전트의 인지 과부하(Cognitive Overload)를 유발한 것이다. 이는 생성형 AI 시스템에서 툴의 개수와 라우팅 정확도가 역상관관계를 가진다는 통계적 유의성을 시사한다.
문제의 본질은 모델의 추론 능력이 아닌 '검색(Retrieval) 파이프라인'의 결함에 있다. 단순 코사인 유사도 기반의 평면적 벡터 검색은 '주문 취소'라는 프롬프트에 단일 툴만을 반환할 뿐, 실제 API 워크플로우에 필수적인 순차적 의존성(list → get → cancel)을 포착하지 못한다. 이를 해결하기 위해 제시된 graph-tool-call 라이브러리는 툴 간의 관계를 방향성 그래프(Directed Graph)로 모델링하고, wRRF(Weighted Reciprocal Rank Fusion)를 통해 BM25, 그래프 탐색, 임베딩 신호를 융합했다. 그 결과, 라우팅 정확도는 82%로 회복되었고 토큰 사용량은 1,699개로 감소하여 추론 비용을 79%나 절감했다. 이는 RAG 파이프라인에서 검색 품질(Retrieval accuracy)과 생성 품질(Generation quality)을 독립적으로 분리하여 최적화해야 함을 보여주는 실증 사례다.
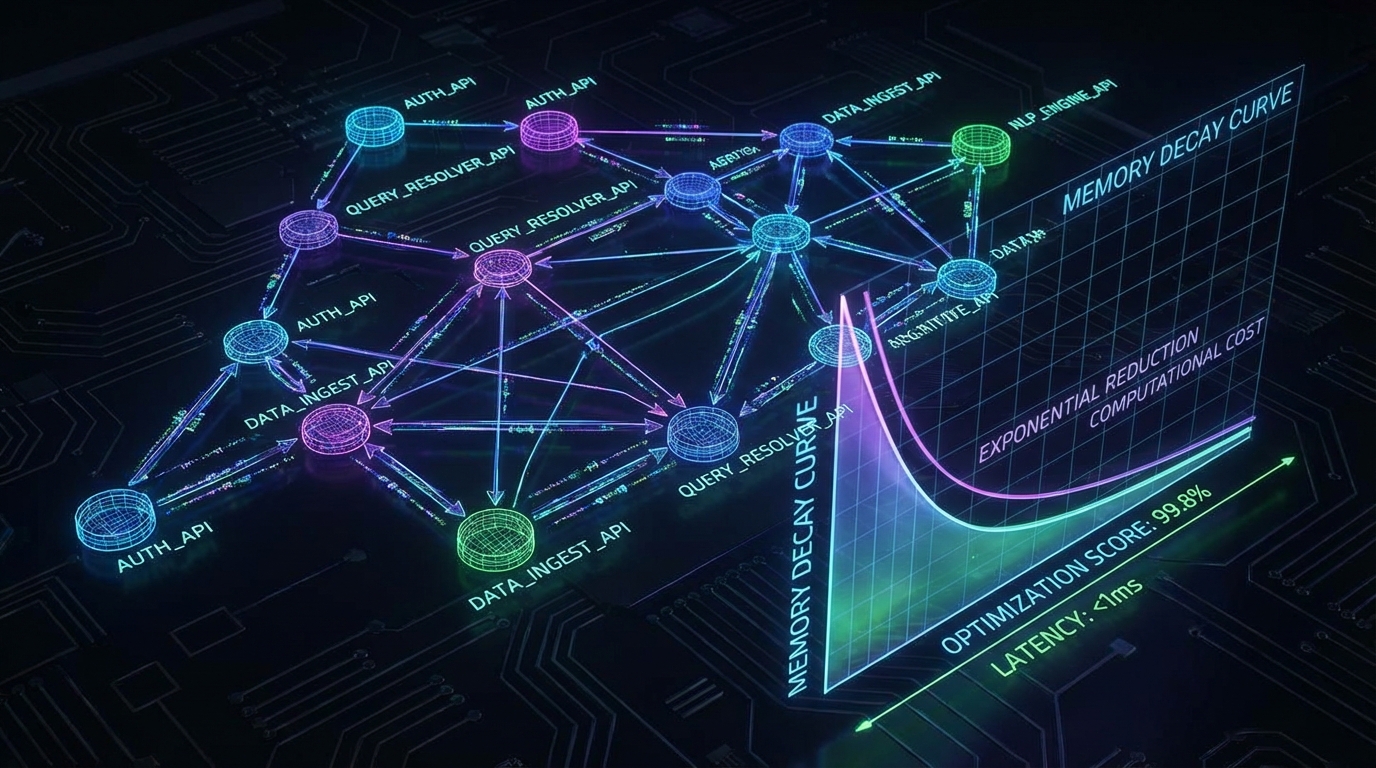
에이전트의 인지 과부하는 툴 선택뿐만 아니라 '메모리 상태(State)' 관리에서도 동일하게 발생한다. 과거의 사실(예: React 사용)과 현재의 사실(예: Vue로 전환)이 동일한 가중치로 컨텍스트에 주입될 경우, 환각(Hallucination)과 상태 충돌이 필연적으로 발생한다. 또 다른 dev.to의 분석에서 제안된 'Ebbinghaus 망각 곡선' 기반의 기억 감쇄(Decay) 알고리즘은 이 문제에 대한 우아한 수학적 접근을 보여준다. 코사인 유사도에 시간 감쇄 강도를 곱하여 검색 점수를 산출한 결과, LoCoMo 데이터셋 기준 Recall@5 지표가 34%로 기존 Mem0(18%) 대비 2배 가까이 향상되었다. 무엇보다 오래된 메모리의 정밀도(Stale memory precision)를 0%에서 100%로 끌어올리며 불필요한 컨텍스트 주입을 원천 차단했다.
이 두 가지 독립적인 실험 데이터는 프로덕션 AI 시스템 설계자들에게 명확한 시사점을 던진다. 프롬프트에 주입되는 정보의 절대량을 늘리는 것은 필연적으로 프로덕션 서빙 환경의 P99 지연 시간(Latency) 증가와 토큰당 I/O 비용 폭증을 초래하며, 어텐션 메커니즘의 집중도를 희석시킨다. 결국 에이전트 시스템의 실질적인 성능 한계점은 '얼마나 많은 도구와 기억을 보유하고 있는가'가 아니라, '현재 태스크에 필요한 최소 유효 컨텍스트(Minimal Viable Context)만을 얼마나 정밀하게 동적으로 라우팅할 수 있는가'에 의해 결정된다.
향후 멀티 에이전트 오케스트레이션 및 MCP(Model Context Protocol) 기반 생태계에서는 이러한 '컨텍스트 압축 및 동적 라우팅'이 핵심 미들웨어로 자리 잡을 것이다. 단순한 벡터 DB의 색인을 넘어, 그래프 탐색 기반의 워크플로우 매핑과 시계열 기반의 확률적 망각(Probabilistic Forgetting) 메커니즘을 결합하는 것만이 비용 효율성과 시스템 신뢰성(Reliability)이라는 트레이드오프를 극복할 수 있는 논리적 설계론이다. 데이터 파이프라인 관점에서 볼 때, 에이전트에게 진정으로 필요한 것은 무한한 기억력이 아니라 수학적으로 통제된 '정밀한 망각'이다.